
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Evil0ctal/Douyin_TikTok_Download_API | api | 48 | tiktok 分享链接解析失败 | https://www.tiktok.com/@official_kotaro2004/video/7110458501767367938?is_from_webapp=1&sender_device=pc
大部分的链接都是可以解析的。 发现少量不行的

| closed | 2022-06-30T14:31:43Z | 2022-07-01T08:34:53Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/48 | [] | OhGui | 1 |
tox-dev/tox | automation | 2,753 | Document which environment variables are passed through by default | Documentation for tox3 had https://tox.wiki/en/3.27.0/config.html#conf-passenv
Documentation for tox4 does not show the list any more
Also see https://github.com/tox-dev/tox/blob/6b1cc141aeb9501aa23774056fbc7179b719e200/src/tox/tox_env/api.py#L179-L204 | closed | 2022-12-19T15:24:47Z | 2024-07-14T07:16:55Z | https://github.com/tox-dev/tox/issues/2753 | [
"area:documentation",
"level:easy",
"help:wanted"
] | jugmac00 | 3 |
tflearn/tflearn | tensorflow | 942 | tflearn not stuck while using with tensorflow.map_fn() | Here's my code:
<pre>
...
network = fully_connected(network, 512, activation='relu')
#network = tf.map_fn(lambda x:tf.abs(x), network)
network =....
</pre>
Commenting the second line will cause the training to stuck forever without and error thrown. The `tf.abs` is just an example. I've tried lot of functions ... | open | 2017-10-26T12:11:18Z | 2017-11-20T10:12:08Z | https://github.com/tflearn/tflearn/issues/942 | [] | D0048 | 4 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 801 | [Still present in latest version] AttributeError: 'FetchNode' object has no attribute 'update_state' | **Describe the bug**
I can't even run this example: https://github.com/ScrapeGraphAI/Scrapegraph-ai/blob/main/examples/openai/scrape_plain_text_openai.py
**To Reproduce**
Steps to reproduce the behavior:
1. Clone the repo and try running the example or any text. | closed | 2024-11-15T10:20:06Z | 2025-01-08T03:33:20Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/801 | [] | aleenprd | 9 |
KaiyangZhou/deep-person-reid | computer-vision | 225 | Help! I want to load weights from model zoo | I am trying to load weights from model zoo especially for OSNetx0.25. Model is not available for the same. When I am trying to load weights on model using function from the tool that giving me
Successfully loaded pretrained weights from "./osnet_x0_25_msmt17_combineall_256x128_amsgrad_ep150_stp60_lr0.0015_b64_fb10_... | closed | 2019-09-08T22:10:08Z | 2019-10-22T21:31:34Z | https://github.com/KaiyangZhou/deep-person-reid/issues/225 | [] | prathameshnetake | 2 |
littlecodersh/ItChat | api | 586 | 请问如何拿到特定群聊里面的所有人的账号信息? | 在提交前,请确保您已经检查了以下内容!
- [x] 您可以在浏览器中登陆微信账号,但不能使用`itchat`登陆
- [x] 我已经阅读并按[文档][document] 中的指引进行了操作
- [x] 您的问题没有在[issues][issues]报告,否则请在原有issue下报告
- [x] 本问题确实关于`itchat`, 而不是其他项目.
- [x] 如果你的问题关于稳定性,建议尝试对网络稳定性要求极低的[itchatmp][itchatmp]项目
请使用`itchat.run(debug=True)`运行,并将输出粘贴在下面:
```
[在这里粘贴完整日志]
```
您的itchat版本为... | closed | 2018-01-29T15:00:37Z | 2018-02-28T03:06:19Z | https://github.com/littlecodersh/ItChat/issues/586 | [
"question"
] | ghost | 1 |
rougier/numpy-100 | numpy | 55 | the answer of question 45 is not exactly correct. | For example:
`z = np.array([1, 2, 3, 4, 5, 5], dtype=int)`
`z[z.argmax()] = 0`
`print(z)`
will output:
`[1 2 3 4 0 5]`
But for this question, the correct answer should be:
`[1 2 3 4 0 0]` | open | 2017-12-27T00:39:26Z | 2020-09-15T05:37:11Z | https://github.com/rougier/numpy-100/issues/55 | [] | i5cnc | 5 |
dpgaspar/Flask-AppBuilder | flask | 2,058 | ModuleNotFoundError: No module named 'config' | ### Environment
Flask-Appbuilder version:
3.4.5
pip freeze output:
apispec==3.3.2
attrs==22.2.0
Babel==2.11.0
click==7.1.2
colorama==0.4.5
dataclasses==0.8
defusedxml==0.7.1
dnspython==2.2.1
email-validator==1.3.1
Flask==1.1.4
Flask-AppBuilder==3.4.5
Flask-Babel==2.0.0
Flask-JWT-Extended==3.25.1
Fl... | closed | 2023-06-12T13:16:21Z | 2023-06-13T15:34:33Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/2058 | [] | coopzr | 3 |
pytest-dev/pytest-django | pytest | 595 | django_db_setup runs inside transactional_db transaction | If the first db test that gets run happens to have `transactional_db` (or `django_db(transaction=True)`) then all subsequent db tests will fail.
This appears to be because the db setup (migrations etc.) are all rolled-back and will not run again because `django_db_setup` is session-scoped. | open | 2018-05-11T10:39:28Z | 2021-12-22T00:11:11Z | https://github.com/pytest-dev/pytest-django/issues/595 | [] | OrangeDog | 16 |
plotly/dash | flask | 2,592 | Be compatible with Flask 2.3 | dash dependency of end of support **flask** branch
```Flask>=1.0.4,<2.3.0```
since https://github.com/plotly/dash/commit/7bd5b7ebec72ffbfca85a57d0d4c19b595371a5a
The 2.3.x branch is now the supported fix branch, the 2.2.x branch will become a tag marking the end of support for that branch.
https://github.com/pall... | closed | 2023-07-07T22:57:24Z | 2023-10-26T21:01:54Z | https://github.com/plotly/dash/issues/2592 | [] | VelizarVESSELINOV | 1 |
pydata/xarray | numpy | 9,424 | Numpy 2.0 (and 2.1): np.linspace(DataArray) does not work any more | ### What happened?
I'm going through our test suite trying to umblock numpy 2.
So we likely have many strange uses of xarray, I can work around them, but I figured I would report the issues with MRC if that is ok with you all:
```
# 2.0 or 2.1 cause the issue
mamba create --name xr netcdf4 xarray numpy=2.1 pyt... | closed | 2024-09-03T14:48:51Z | 2024-09-03T15:40:47Z | https://github.com/pydata/xarray/issues/9424 | [
"bug",
"needs triage"
] | hmaarrfk | 3 |
litestar-org/litestar | asyncio | 3,650 | Bug(OpenAPI): Schema generation doesn't resolve signature types for "nested" objects | ### Description
OpenAPI schema generation fails if it encounters a "nested" object with a type which is not available at runtime but could be resolved using `signature types/namespaces`.
### URL to code causing the issue
_No response_
### MCVE
main.py
```py
from litestar import Litestar, get
from ... | open | 2024-08-02T11:26:08Z | 2025-03-20T15:54:51Z | https://github.com/litestar-org/litestar/issues/3650 | [
"Bug :bug:",
"OpenAPI"
] | floxay | 0 |
ranaroussi/yfinance | pandas | 2,100 | 0.2.47 Refactor multi.py to return single-level index when a single ticker | **Describe bug**
Refactoring multi.py to return single-level indexes when using a single ticker is breaking a lot of existing code in several applications. Was this refactor necessary?
**Debug log**
No response
**yfinance version**
0.2.47
**Python version**
3.10
**Operating system**
kubuntu 2... | closed | 2024-10-25T15:58:17Z | 2024-10-25T18:05:15Z | https://github.com/ranaroussi/yfinance/issues/2100 | [] | BiggRanger | 2 |
flasgger/flasgger | rest-api | 552 | older flassger required package incompatibility | Hi Team, thanks for the great package!
We came across an issue where flassger 0.9.5 imports a flask/jinja version that in turn imports a version of markupsafe that has a breaking change (soft_unicode was removed, soft_str replaced it), which causes a hard fail. A current workaround for this is manually importing an ol... | open | 2022-11-23T12:21:38Z | 2022-11-23T12:21:38Z | https://github.com/flasgger/flasgger/issues/552 | [] | adamb910 | 0 |
widgetti/solara | fastapi | 572 | footgun: using a reactive var, not its value as a dependency | ```python
var = solara.reactive(1)
...
solara.use_effect(..., dependencies=[var])
```
A user probably intended to use `var.value`, since the effect should trigger when the value changes. I think we should warn when this happens, and have an opt out for this warning. | open | 2024-03-26T11:41:41Z | 2024-03-27T09:46:54Z | https://github.com/widgetti/solara/issues/572 | [
"footgun"
] | maartenbreddels | 0 |
jupyter/nbgrader | jupyter | 1,039 | Language support | I would like to add language support for Octave kernel.
And make it easier to add more languages and not have the code that checks for errors in two places like it is now in validator._extract_error and utils.determine_grade
You can see the code in this PR I just made that describes the changes better: #1038 | open | 2018-10-30T12:41:00Z | 2022-12-02T14:46:20Z | https://github.com/jupyter/nbgrader/issues/1039 | [
"enhancement"
] | sigurdurb | 3 |
ivy-llc/ivy | tensorflow | 28,517 | Fix Frontend Failing Test: torch - math.paddle.heaviside | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-03-09T14:58:00Z | 2024-03-14T21:29:22Z | https://github.com/ivy-llc/ivy/issues/28517 | [
"Sub Task"
] | ZJay07 | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 939 | Can not find the three Pretrained model |

I intended to download these models, but find nothing.
encoder\saved_models\pretrained.pt
synthesizer\saved_models\pretrained\pretrained.pt
vocoder\saved_models\pretrained\pretrained.pt
Any guys kn... | closed | 2021-12-06T18:32:20Z | 2021-12-28T12:34:19Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/939 | [] | ZSTUMathSciLab | 1 |
kevlened/pytest-parallel | pytest | 42 | cannot work with pytest‘s fixture | ```
python 3.7.4
pytest 5.2.0
pytest-parallel 0.2.2
gevent 1.4.0
```
the scope of fixture, for example: session,module, they do no work.
| open | 2019-10-21T12:38:24Z | 2019-11-18T10:11:40Z | https://github.com/kevlened/pytest-parallel/issues/42 | [] | bglmmz | 2 |
gunthercox/ChatterBot | machine-learning | 1,652 | ModuleNotFoundError | After installing chatterbot this error occurs!
C:\Users\Nabeel\chatbot> py chat.py
Traceback (most recent call last):
File "chat.py", line 1, in <module>
from chatterbot import ChatBot
ModuleNotFoundError: No module named 'chatterbot' | closed | 2019-03-04T17:41:45Z | 2020-01-17T16:16:22Z | https://github.com/gunthercox/ChatterBot/issues/1652 | [] | nabeelahmedsabri | 4 |
mirumee/ariadne | graphql | 224 | Update GraphQL Core Next & Starlette | Issue for me to remember to update our core dependencies to latest versions before release. | closed | 2019-08-01T15:41:48Z | 2019-08-12T12:24:54Z | https://github.com/mirumee/ariadne/issues/224 | [
"enhancement"
] | rafalp | 0 |
supabase/supabase-py | flask | 20 | AttributeError: 'RequestBuilder' object has no attribute 'on' | # Bug report
## Describe the bug
The Python client doesn't support realtime subscription and fails with "AttributeError: 'RequestBuilder' object has no attribute 'on'".
(Update 17/01/22: This was an example originally forming part of the README)
## To Reproduce
Using the following example from the origin... | closed | 2021-04-08T13:42:41Z | 2024-06-25T08:12:55Z | https://github.com/supabase/supabase-py/issues/20 | [
"bug",
"realtime",
"Stale"
] | iwootten | 10 |
ymcui/Chinese-BERT-wwm | nlp | 210 | Confusion with the config.json in RoBerta-based Models | closed | 2022-01-08T06:57:27Z | 2022-01-17T04:25:59Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/210 | [
"stale"
] | qhd1996 | 2 | |
mwaskom/seaborn | matplotlib | 2,986 | swarmplot change point maximum displacement from center | Hi,
I am trying to plot a `violinplot` + `swarmplot` combination for with multiple hues and many points and am struggling to get the optimal clarity with as few points as possible overlapping. I tried both `swarmplot` and `stripplot`, with and without `dodge`.
Since i have multiple categories on the y-axis , I have ... | closed | 2022-08-30T10:05:12Z | 2022-08-30T11:44:51Z | https://github.com/mwaskom/seaborn/issues/2986 | [] | ohickl | 4 |
torchbox/wagtail-grapple | graphql | 340 | Inconsistent error handling in the site query | I've noticed an inconsistency in how wagtail-grapple handles errors for the `site` query, which takes `id` and `hostname` as parameters.
When an incorrect `id` is provided, the query appropriately returns `null`, meaning the requested site does not exist. However, when a non-existent `hostname` is provided, it raise... | closed | 2023-07-03T12:11:17Z | 2023-07-09T16:09:24Z | https://github.com/torchbox/wagtail-grapple/issues/340 | [] | estyxx | 1 |
coqui-ai/TTS | deep-learning | 3,270 | [Bug] Cant run any of the xtts models using the TTS Command Line Interface (CLI) | ### Describe the bug
Hello I just started playing with the TTS library and I am running tests using the TTS Command Line Interface (CLI).
I was able to try capacitron, vits (english and portuguese) and tacotron2 successfully. But when I tried any of the xtts models, I get the same error that suggests I have yet to s... | closed | 2023-11-20T01:33:34Z | 2023-11-20T08:38:43Z | https://github.com/coqui-ai/TTS/issues/3270 | [
"bug"
] | 240db | 1 |
tqdm/tqdm | pandas | 1,015 | Progress bar always rendered in Google Colab/Jupyter Notebook | On the terminal, it is possible to disable the progress bar by not specifying `"{bar}"` in `bar_format`. For example `bar_format="{l_bar}{r_bar}"` will render the left and right sides of the bar, but not the actual progress bar itself.
On Google Colab/Jupyter Notebook, the bar will always render on the left side, ev... | closed | 2020-07-29T21:36:56Z | 2020-08-02T21:22:17Z | https://github.com/tqdm/tqdm/issues/1015 | [
"to-fix ⌛",
"p2-bug-warning ⚠",
"submodule-notebook 📓",
"c1-quick 🕐"
] | EugenHotaj | 1 |
docarray/docarray | fastapi | 1,351 | HnswDocIndex cannot use two time the same workdir | # Context
using two time the same `work_dir` lead to error
```python
from docarray import DocList
from docarray.documents import ImageDoc
from docarray.index import HnswDocumentIndex
import numpy as np
# create some data
dl = DocList[ImageDoc](
[
ImageDoc(
url="https://upload.wi... | closed | 2023-04-11T09:46:33Z | 2023-04-22T09:47:25Z | https://github.com/docarray/docarray/issues/1351 | [] | samsja | 2 |
keras-team/keras | machine-learning | 20,104 | Tensorflow model.fit fails on test_step: 'NoneType' object has no attribute 'items' | I am using tf.data module to load my datasets. Although the training and validation data modules are almost the same. The train_step works properly and the training on the first epoch continues till the last batch, but in the test_step I get the following error:
```shell
353 val_logs = {
--> 354 "va... | closed | 2024-08-09T15:32:39Z | 2024-08-10T17:59:05Z | https://github.com/keras-team/keras/issues/20104 | [
"stat:awaiting response from contributor",
"type:Bug"
] | JVD9kh96 | 2 |
sqlalchemy/sqlalchemy | sqlalchemy | 12,378 | Streamline Many-to-Many and One-to-Many Relationship Handling with Primary Key Lists | ### Describe the use case
Currently, SQLAlchemy requires fetching all related objects from the database to establish many-to-many or one-to-many relationships. This can be inefficient and unnecessary when only the primary keys of the related objects are known. A more efficient approach would be to allow the associatio... | closed | 2025-02-27T09:11:13Z | 2025-03-03T07:45:12Z | https://github.com/sqlalchemy/sqlalchemy/issues/12378 | [
"orm",
"use case"
] | Gepardgame | 6 |
ansible/awx | django | 15,540 | docker-compose-build fails with: Unable to find a match: openssl-3.0.7 | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | closed | 2024-09-18T14:33:40Z | 2024-09-19T16:13:57Z | https://github.com/ansible/awx/issues/15540 | [
"type:bug",
"needs_triage",
"community"
] | jean-christophe-manciot | 3 |
JaidedAI/EasyOCR | pytorch | 457 | Update 'Open in colab' link on the Home Page for Demo/Example | closed | 2021-06-12T08:29:22Z | 2021-06-13T07:16:21Z | https://github.com/JaidedAI/EasyOCR/issues/457 | [] | the-marlabs | 1 | |
deeppavlov/DeepPavlov | tensorflow | 1,454 | Support of the Transformers>=4.0.0 version library | **DeepPavlov version** (you can look it up by running `pip show deeppavlov`):
latest
**Python version**:
3.6
**Operating system** (ubuntu linux, windows, ...):
ubuntu
**Issue**:
Starting from version 4.0.0 the interface of Transformers library was changed and a dictionary is returned as model output. That is why... | closed | 2021-05-24T18:39:42Z | 2022-04-01T11:18:09Z | https://github.com/deeppavlov/DeepPavlov/issues/1454 | [
"bug"
] | spolezhaev | 2 |
davidsandberg/facenet | computer-vision | 499 | How do you setup the project? | I am missing the setup.py file, was the installation procedure changed? | closed | 2017-10-26T10:07:22Z | 2017-11-10T23:11:56Z | https://github.com/davidsandberg/facenet/issues/499 | [] | mia-petkovic | 2 |
vitalik/django-ninja | pydantic | 1,172 | Not required fields in FilterSchema | Please describe what you are trying to achieve:
in FilterSchema, is it possible to use the params 'exclude_none' ?
Please include code examples (like models code, schemes code, view function) to help understand the issue
```
class Filters(FilterSchema):
limit: int = 100
offset: int = None
qu... | open | 2024-05-20T08:16:49Z | 2024-09-27T06:27:31Z | https://github.com/vitalik/django-ninja/issues/1172 | [] | horizon365 | 1 |
PokeAPI/pokeapi | api | 452 | Add possibility to get Pokemon evolution easier | Please add possibility to make requests like this:
https://pokeapi.co/api/v2/evolution/{pkmn ID or name}/
This would return:
evo_from
evo_from_reqs
evo_to
evo_to_req
evo_mega
evo_form
Please add this. Currenly it's so hard to get specific pokemon evo from and evo to. | closed | 2019-10-12T10:24:05Z | 2020-08-19T10:07:31Z | https://github.com/PokeAPI/pokeapi/issues/452 | [] | ks129 | 4 |
huggingface/datasets | deep-learning | 6,973 | IndexError during training with Squad dataset and T5-small model | ### Describe the bug
I am encountering an IndexError while training a T5-small model on the Squad dataset using the transformers and datasets libraries. The error occurs even with a minimal reproducible example, suggesting a potential bug or incompatibility.
### Steps to reproduce the bug
1.Install the required libr... | closed | 2024-06-16T07:53:54Z | 2024-07-01T11:25:40Z | https://github.com/huggingface/datasets/issues/6973 | [] | ramtunguturi36 | 2 |
Miserlou/Zappa | django | 1,812 | How to "catch" an asynchronous task timeout? | Sorry if I missed this in the docs, but how can I "catch" that a certain asynchronous task has received a timeout? | open | 2019-03-12T17:05:51Z | 2019-03-14T13:21:24Z | https://github.com/Miserlou/Zappa/issues/1812 | [] | mojimi | 2 |
openapi-generators/openapi-python-client | rest-api | 750 | Allow tweaking configuration of black and isort via custom templates | **Is your feature request related to a problem? Please describe.**
I'm using a monorepo with multiple projects, where some of the projects are generated by openapi-python-client.
I'd like to have a single configuration of black and isort at the top level of the monorepo, but having them included in pyproject.toml of ... | closed | 2023-04-21T16:38:54Z | 2023-04-30T19:31:14Z | https://github.com/openapi-generators/openapi-python-client/issues/750 | [
"✨ enhancement"
] | machinehead | 1 |
RobertCraigie/prisma-client-py | pydantic | 854 | Retrying db calls? | Hey @RobertCraigie,
Is there a way to retry db calls? (or is this already happening under-the-hood)?
Users reporting failed db writes - https://github.com/BerriAI/litellm/issues/1056 | open | 2023-12-08T02:42:31Z | 2023-12-08T02:42:31Z | https://github.com/RobertCraigie/prisma-client-py/issues/854 | [] | krrishdholakia | 0 |
miguelgrinberg/python-socketio | asyncio | 528 | Good way to handle flow control | What is the best way to handle flow control with WebSockets. I am looking at a large file transfer case. Here is what I am currently doing
1. Chunk the files into 10k size chunks
2. Send out 5 chunks, then call sio.sleep(0.01)
3. back to step(2) until EOF
There are a few problems I run it, especially when the f... | closed | 2020-07-26T08:42:33Z | 2020-10-09T19:07:25Z | https://github.com/miguelgrinberg/python-socketio/issues/528 | [
"question"
] | bhakta0007 | 4 |
graphql-python/graphene-sqlalchemy | graphql | 31 | Anything on the roadmap for a relay SQLAlchemyClientIDMutation class? | I have been using this library for a project and its great so far, however it seems there should also be a class for relay ClientIDMutations. Is this on the roadmap? | closed | 2017-01-12T02:24:12Z | 2023-08-15T00:36:03Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/31 | [
":eyes: more info needed"
] | aminghadersohi | 2 |
explosion/spaCy | data-science | 13,680 | Spaces impacting tag/pos | ## How to reproduce the behaviour
Notice the double space in front of `sourire` in the first case vs. the single space in the second case
`Les publics avec un sourire chaleureux et`
<img width="1277" alt="image" src="https://github.com/user-attachments/assets/9bdb2aca-8741-41d5-995e-2333aa392158">
https://... | open | 2024-10-28T12:55:22Z | 2024-11-12T04:11:26Z | https://github.com/explosion/spaCy/issues/13680 | [] | lsmith77 | 1 |
ijl/orjson | numpy | 229 | JSON5 Format Support | Well the current issue more of an issue is an actual feature request or suggestion.
But basically, I've been wondernig if JSON5 is going to be implemented in this library which I think it'd be very useful given the library's speed performance in reading operations while being able to keep the advantages that this ne... | closed | 2022-01-06T19:22:18Z | 2022-01-13T00:09:37Z | https://github.com/ijl/orjson/issues/229 | [] | Vioshim | 1 |
explosion/spaCy | nlp | 13,157 | Issue when calling spacy info | Hi I am Bala. I use Spacy 3.6.1 for NLP. I am facing the following issue when calling spacy info and when loading any model. I use Python 3.8 on Windows 10.
<<
(pnlpbase) PS C:\windows\system32> python -m spacy info
Traceback (most recent call last):
File "D:\python\Anaconda3\envs\pnlpbase\lib\runpy.py", line 185... | closed | 2023-11-28T01:55:43Z | 2024-01-26T08:50:07Z | https://github.com/explosion/spaCy/issues/13157 | [
"duplicate"
] | balachander1964 | 3 |
horovod/horovod | deep-learning | 3,857 | Horovod with MPI and NCCL | If I have installed NCCL and MPI, and want to install horovod from source code. But I'm confused about some parameters.
**HOROVOD_GPU_OPERATIONS**,**HOROVOD_GPU_ALLREDUCE** and **HOROVOD_GPU_BROADCAST**
How to set this three parameters ? Which use NCCL and which use MPI ? Anyone can help to answer this question? ... | closed | 2023-03-01T07:27:23Z | 2023-03-01T10:08:37Z | https://github.com/horovod/horovod/issues/3857 | [
"question"
] | yjiangling | 2 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 579 | Custom dataset encoder training | Hi, how do i implement a cusom data set for the encoder training? | closed | 2020-10-29T15:03:13Z | 2021-02-10T07:36:20Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/579 | [] | quirijnve | 13 |
adbar/trafilatura | web-scraping | 676 | Remove deprecations (mostly CLI) | - [x] Look for lines like `raise ValueError("...deprecated")` and remove deprecations
- [x] Check if all CLI arguments are actually used
- [x] Remove corresponding tests | closed | 2024-08-15T15:34:45Z | 2024-10-08T16:53:12Z | https://github.com/adbar/trafilatura/issues/676 | [
"maintenance"
] | adbar | 0 |
allure-framework/allure-python | pytest | 484 | Attach a ZIP or XLSX file | Hello, using the latest package, what is the right code for attaching a file .xlsx to the report?
I'm using:
```
from allure_commons.types import AttachmentType
allure.attach.file("./bin/prova-riccardo.xlsx", name="prova-riccardo.xlsx")
```
but the downloaded file name has a strange name (508c27f28c7697d9.attac... | closed | 2020-04-14T10:47:31Z | 2022-04-19T19:05:56Z | https://github.com/allure-framework/allure-python/issues/484 | [] | ric79 | 3 |
encode/apistar | api | 523 | Docs/Guide give error: AttributeError: type object 'list' has no attribute '__args__' | [This](https://docs.apistar.com/api-guide/routing/) routing guide, give me error:
> (apistar) ➜ test python app.py
Traceback (most recent call last):
File "app.py", line 39, in <module>
Route('/users/', method='GET', handler=list_users),
File "/Users/atmosuwiryo/.virtualenvs/apistar/lib/python3.6/sit... | closed | 2018-05-09T16:29:03Z | 2018-05-21T09:41:51Z | https://github.com/encode/apistar/issues/523 | [] | atmosuwiryo | 1 |
vitalik/django-ninja | pydantic | 866 | Dates in query parameters without leading zeroes lead to 422 error | Query parameters defined as date now expect to be in the format YYYY-MM-DD with leading zeroes.
Before upgrade to beta v1 it was possible to send date parameters without leading zeroes, e.g. 2023-9-29.
After upgrade this will yield 422 Unprocessable Entity.
The request works with leading zeroes, e.g. 2023-09-29
I h... | closed | 2023-09-29T16:27:10Z | 2023-10-02T07:25:02Z | https://github.com/vitalik/django-ninja/issues/866 | [] | ognjenk | 3 |
PokeAPI/pokeapi | api | 1,140 | Kanto Route 13 encounter table missing time conditions for Crystal | - Pidgeotto, Nidorina, Nidorino slots should be equally split between morning only and day only.
- Venonat, Venomoth, Noctowl, Quagsire should be night only (except Quagsire's surf slot).
- Chansey slots have no time conditions at all, so what should be 1% is reported as 3%. | open | 2024-10-08T04:11:39Z | 2024-10-08T04:11:39Z | https://github.com/PokeAPI/pokeapi/issues/1140 | [] | Pinsplash | 0 |
recommenders-team/recommenders | machine-learning | 1,810 | Use LSTUR Model with own Data | ### Description
I am trying to use the LSTUR model with a dataset about purchase data, but I don't understand which format data have to pass to the model.
In the example:
` model = LSTURModel(hparams, iterator, seed=seed)`
Is data stored inside the "iterator" object?
| open | 2022-08-10T21:53:07Z | 2022-09-03T14:27:31Z | https://github.com/recommenders-team/recommenders/issues/1810 | [
"help wanted"
] | claraMarti | 2 |
bendichter/brokenaxes | matplotlib | 14 | How to share x axes in subplots? | I creat subplots with Gridspec, how can I make the top panel share the x axes with the bottom one? | closed | 2018-04-20T02:16:04Z | 2018-04-20T16:01:14Z | https://github.com/bendichter/brokenaxes/issues/14 | [] | Kal-Elll | 3 |
huggingface/diffusers | pytorch | 10,406 | CogVideoX: RuntimeWarning: invalid value encountered in cast | Can be closed | closed | 2024-12-29T08:50:56Z | 2024-12-29T08:59:00Z | https://github.com/huggingface/diffusers/issues/10406 | [
"bug"
] | nitinmukesh | 0 |
cvat-ai/cvat | tensorflow | 9,187 | Problem with version 2.31.0 after upgrading from 2.21.2: "Could not fetch requests from the server" | ### Actions before raising this issue
- [x] I searched the existing issues and did not find anything similar.
- [x] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
Hello,
we upgraded vom version 2.21.2 to 2.31.0. Now we see the following message after login or after an action like crea... | closed | 2025-03-10T08:04:30Z | 2025-03-10T14:09:02Z | https://github.com/cvat-ai/cvat/issues/9187 | [
"bug",
"need info"
] | RoseDeSable | 7 |
FlareSolverr/FlareSolverr | api | 1,123 | The CPU and memory usage of Chromium | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I hav... | closed | 2024-03-17T07:29:55Z | 2024-03-18T11:04:42Z | https://github.com/FlareSolverr/FlareSolverr/issues/1123 | [
"duplicate"
] | nanmuye | 2 |
gevent/gevent | asyncio | 1,806 | immediate disconnection of gevent-websocket (code: 1005, reason: “”) | * gevent version: gevent==21.1.2
* Python version: Python 3.8.10
* Operating System: Ubuntu 20.04.1 LTS
### Description:
I test the following simple websocket server with wscat, but it is immediately disconnected without listening.
I tried
```
python main.py &
wscat -c ws://localhost:5000/echo
```
a... | closed | 2021-07-10T21:37:40Z | 2021-07-11T11:17:33Z | https://github.com/gevent/gevent/issues/1806 | [] | nemnemnemy | 1 |
noirbizarre/flask-restplus | flask | 726 | Move to Jazzband or other shared project space | flask-restplus, even after adding multiple new maintainers, is continuing to fall behind requests. We are all donating our time and expertise, and there's still more work than available time.
We should think about moving to Jazzband or another shared project space. This gives us:
1. more possible maintainers and ... | open | 2019-10-09T14:26:47Z | 2019-10-10T18:47:17Z | https://github.com/noirbizarre/flask-restplus/issues/726 | [] | j5awry | 5 |
tensorpack/tensorpack | tensorflow | 1,200 | Add fetches tensors dynamically | Hi,
First,Thanks for your wonderful work.
I'm training an object detector. In the end of my net I have 2 Tensors of confidence and location.
I can take those two tensors to compute cost function (it works and train). I also want that at the end of each epoch take those two tensors apply tf function and apply summ... | closed | 2019-05-20T08:15:18Z | 2019-05-24T22:43:10Z | https://github.com/tensorpack/tensorpack/issues/1200 | [
"usage"
] | MikeyLev | 2 |
MycroftAI/mycroft-core | nlp | 2,770 | Mycroft fails to start on Manjaro | **Describe the bug**
Starting Mycroft on Manjaro Linux after installing it in the official way, results in errors and warnings.
**To Reproduce**
1. Go to https://github.com/MycroftAI/mycroft-core
2. Copy the steps from the Installation guide and run them in your terminal.
3. Answer all the Questions asked at the... | closed | 2020-12-01T09:14:48Z | 2024-09-08T08:32:16Z | https://github.com/MycroftAI/mycroft-core/issues/2770 | [
"bug"
] | 1Maxnet1 | 16 |
scikit-hep/awkward | numpy | 2,859 | GPU Tests Failed | The GPU tests failed for commit with the following pytest output:
```
``` | closed | 2023-11-30T07:02:11Z | 2023-11-30T12:59:36Z | https://github.com/scikit-hep/awkward/issues/2859 | [] | agoose77 | 0 |
pydantic/logfire | pydantic | 652 | Connecting Alternate Backend to GCP Metrics/Traces | ### Question
In the below documentation
https://logfire.pydantic.dev/docs/guides/advanced/alternative-backends/#other-environment-variables
it is mentioned if OTEL_TRACES_EXPORTER and/or OTEL_METRICS_EXPORTER is configured, it can work with alternate Backends
Can I connect the same to GCP Cloud Monitoring (Metr... | open | 2024-12-06T13:50:16Z | 2024-12-24T08:39:15Z | https://github.com/pydantic/logfire/issues/652 | [
"Question"
] | sandeep540 | 6 |
mitmproxy/pdoc | api | 35 | Parsing Epytext | Sorry the ignorance. Is there a way of 'forcing' pdoc to parse docstrings in Epytext format as the example below:
``` python
def load_config(filename, option):
"""
Loads and tests input parameters.
@param filename: input filename
@param option: option name
@return: returns a valid config value
... | closed | 2015-02-27T17:10:11Z | 2018-06-03T03:15:23Z | https://github.com/mitmproxy/pdoc/issues/35 | [] | biomadeira | 5 |
tortoise/tortoise-orm | asyncio | 1,551 | Optional parameter in pydantic_model_creator does not work after upgrading to pydantic v2 | **Describe the bug**
- tortoise-orm = 0.20.0
- pydantic==2.5.3
- pydantic-core==2.14.6
升级至 pydantic v2 后 使用 pydantic_model_creator 创建 pydantic 模型时,pydantic_model_creator(optional=(xxx))不生效,字段 仍为必须填写
After upgrading to pydantic v2, when using pydantic_model_creator to create pydantic model, pydantic_model_... | closed | 2024-01-25T09:48:13Z | 2024-05-24T07:23:25Z | https://github.com/tortoise/tortoise-orm/issues/1551 | [] | cary997 | 2 |
pyeve/eve | flask | 1,496 | Replace vs Merge Update on PATCH | ### Feature Request
Providing a header that will allow a PATCH request to replace a key value instead of using PUT, PUT replaces fields I want to
preserve and leave unchangeable.
Unless this can be achieved in another way
### Expected Behavior
```python
# Create a record
POST /api/profiles
{
'name':... | open | 2023-01-26T21:00:40Z | 2023-01-26T21:00:40Z | https://github.com/pyeve/eve/issues/1496 | [] | ghost | 0 |
long2ice/fastapi-cache | fastapi | 30 | Include dependencies with PyPi installation | Should not `aioredis`, `memcache`, and `redis` come with the installation of this package, as they are requirements?
Regarding `redis` vs `memcache` and PyPi, this is issue is related: #29 | closed | 2021-07-30T23:57:08Z | 2023-05-14T22:13:48Z | https://github.com/long2ice/fastapi-cache/issues/30 | [] | joeflack4 | 1 |
huggingface/transformers | python | 36,414 | Downloading models in distributed training | When I run distributed training, if the model is not already downloaded locally on disk, different ranks start fighting for the download and they crash.
I am looking for a fix such that:
1. If the model is not yet downloaded on disk, only one rank downloads it. The rest of the ranks are waiting until the file is down... | closed | 2025-02-26T09:28:06Z | 2025-03-11T22:08:10Z | https://github.com/huggingface/transformers/issues/36414 | [] | nikonikolov | 3 |
huggingface/text-generation-inference | nlp | 2,324 | 墙内用户如何不使用梯子运行docker容器.Chinese mainland users must use a proxy software when running Docker. How can they avoid using a proxy software? | ### Feature request
我可以确认在huggingface上下载的模型权重文件没有问题,运行docker时还是需要翻墙才能正常运行。我猜测是代码中需要对文件进行检查,是否可以设置一个参数避免进行检查呢?
I can confirm that the weight files of the neural network models downloaded from the Hugging Face website are correct, but the container still needs a proxy software (to bypass the firewall) to run normally. ... | closed | 2024-07-29T07:55:13Z | 2024-07-29T09:15:56Z | https://github.com/huggingface/text-generation-inference/issues/2324 | [] | zk19971101 | 5 |
unionai-oss/pandera | pandas | 851 | PyArrow as optional dependency | **Is your feature request related to a problem? Please describe.**
The PyArrow package contains some very large libraries (e.g., `libarrow.so` (50MB) and `libarrow_flight.so` (14M)). This makes it very hard to use the Pandera package in a serverless environment, since packages have strict size limits and PyArrow is ... | open | 2022-05-10T11:47:22Z | 2022-07-14T10:21:29Z | https://github.com/unionai-oss/pandera/issues/851 | [
"enhancement"
] | markkvdb | 6 |
jupyterlab/jupyter-ai | jupyter | 292 | Allow /generate to accept a schema or template | ### Problem
Right now, users have no control over the "structure" of notebooks generated via `/generate`.
### Proposed Solution
Offer some way for users to indicate to `/generate` the schema/template of the notebook. The specifics of how this may be implemented remain open to discussion. | open | 2023-07-24T16:31:41Z | 2024-10-23T22:09:19Z | https://github.com/jupyterlab/jupyter-ai/issues/292 | [
"enhancement",
"scope:generate"
] | dlqqq | 1 |
chainer/chainer | numpy | 8,545 | Incompatible version is released to Python 2 | `chainer>=7.0.0` released before #8517 is still released to Python 2, even though they doesn't support Python 2.
Due to this, we cannot use `pip install chainer` in Python 2. Instead, we always have to specify install version like `pip install chainer<7.0.0`.
```
$ pip install --user chainer --no-cache-dir -U
/usr/... | closed | 2020-02-11T03:00:41Z | 2021-01-13T11:37:38Z | https://github.com/chainer/chainer/issues/8545 | [
"stale",
"issue-checked"
] | pazeshun | 11 |
davidteather/TikTok-Api | api | 227 | [BUG] - Putting Spanish lang code gives me Russian hashtags and Arabic trendings | **Describe the bug**
Putting the Spanish lang code gives me Russian hashtags using the get trending hashtag. If I do use the get trending function I do get Arabic videos.
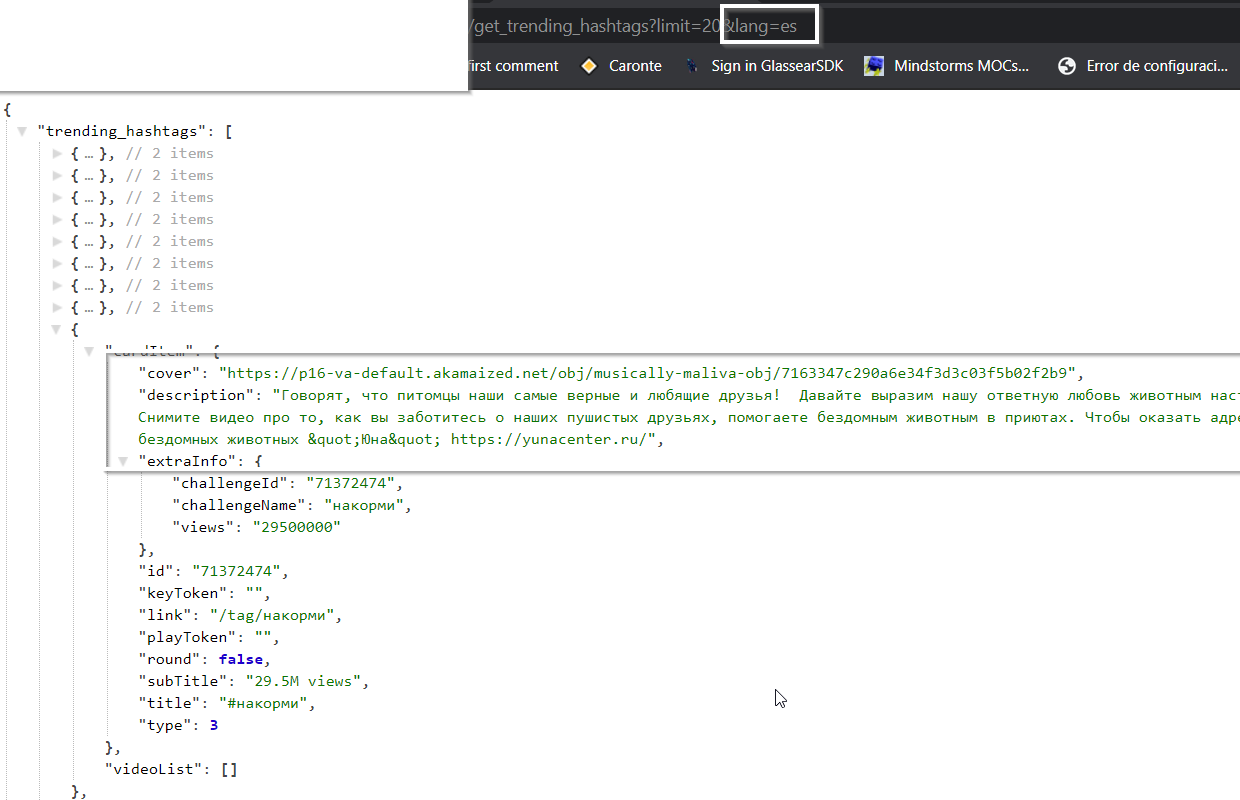
**The buggy code*... | closed | 2020-08-20T11:29:24Z | 2020-08-20T16:56:26Z | https://github.com/davidteather/TikTok-Api/issues/227 | [
"bug"
] | elblogbruno | 4 |
jupyter-incubator/sparkmagic | jupyter | 760 | [BUG] Running sparkmagic notebook in sagemaker lifecycle script | **Describe the bug**
Through sagemaker notebooks I am trying to run a sparkmagic notebook (to talk to an emr) via nbconvert inside of the lifecycle script that runs during start up. It looks like it isn't picking up the config file.
If I wait till after sagemaker has started it all connects and works fine.
I kn... | open | 2022-05-03T11:16:49Z | 2022-05-06T13:30:47Z | https://github.com/jupyter-incubator/sparkmagic/issues/760 | [] | byteford | 4 |
Textualize/rich | python | 2,827 | [BUG] rich progress bar display problem | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | closed | 2023-02-23T12:35:54Z | 2023-03-04T15:01:16Z | https://github.com/Textualize/rich/issues/2827 | [
"more information needed"
] | shimbay | 4 |
yt-dlp/yt-dlp | python | 12,546 | embed online subtitles directly ? | ### Checklist
- [x] I'm asking a question and **not** reporting a bug or requesting a feature
- [x] I've looked through the [README](https://github.com/yt-dlp/yt-dlp#readme)
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))... | closed | 2025-03-06T08:49:53Z | 2025-03-06T10:06:35Z | https://github.com/yt-dlp/yt-dlp/issues/12546 | [
"question",
"piracy/illegal"
] | veganomy | 8 |
unit8co/darts | data-science | 2,403 | Enhance integration of Global and Local models. | **Is your feature request related to a current problem? Please describe.**
When using a mixture of local and global models, the user needs to distinguish the model types.
Here's a list of practical examples:
- When calling the `fit` method, local models don't support lists of TimeSeries.
- Ensembles support a ... | open | 2024-06-05T09:43:32Z | 2024-06-10T14:52:16Z | https://github.com/unit8co/darts/issues/2403 | [
"triage"
] | davide-burba | 2 |
recommenders-team/recommenders | data-science | 1,933 | [BUG] Issue with AzureML machines in tests. Conflict of Cornac with NumPy | ### Description
<!--- Describe your issue/bug/request in detail -->
Machines are not starting, so no tests are being triggered.
### In which platform does it happen?
<!--- Describe the platform where the issue is happening (use a list if needed) -->
<!--- For example: -->
<!--- * Azure Data Science Virtual Ma... | closed | 2023-06-01T15:39:21Z | 2023-06-08T10:41:48Z | https://github.com/recommenders-team/recommenders/issues/1933 | [
"bug"
] | miguelgfierro | 5 |
FujiwaraChoki/MoneyPrinterV2 | automation | 65 | I optimized a version that supports Chinese(中文) and made a lot of optimizations | # I am very grateful for the MoneyPrinter project.
I found that its support for **Chinese** was not very good.
So I did a refactor and optimization to make it support **both Chinese and English** well.
It supports various Chinese and English speech synthesis, and the subtitle effect has been improved.
[https:... | closed | 2024-03-13T02:23:03Z | 2024-04-28T09:25:43Z | https://github.com/FujiwaraChoki/MoneyPrinterV2/issues/65 | [] | harry0703 | 1 |
collerek/ormar | sqlalchemy | 529 | JSON field isnull filter | Using a nullable JSON field and filtering with isnull produces unexpected results. Is the JSON intended to be treated differently when it comes to nullness?
**To reproduce and expected behavior:**
```
import asyncio
import databases
import ormar
import sqlalchemy
DATABASE_URL = "sqlite:///db.sqlite"
datab... | closed | 2022-01-15T08:20:05Z | 2022-02-25T11:19:46Z | https://github.com/collerek/ormar/issues/529 | [
"bug"
] | vekkuli | 1 |
coqui-ai/TTS | deep-learning | 3,131 | [Bug] Error occurs when resuming training a xtts model | ### Describe the bug
Error occurs when I try to resume training of a xtts model. Details are describe below.
### To Reproduce
First, I train a xtts model using the official script:
```
cd TS/recipes/ljspeech/xtts_v1
CUDA_VISIBLE_DEVICES="0" python train_gpt_xtts.py
```
Then, during the training, it is c... | closed | 2023-11-01T10:04:46Z | 2024-01-26T11:33:37Z | https://github.com/coqui-ai/TTS/issues/3131 | [
"bug"
] | yiliu-mt | 7 |
iperov/DeepFaceLive | machine-learning | 169 | Camera Input Problem | Hello iperov,
Thanks in advance. But i have a problem. I'm using Logitech C922 Pro Webcam, RTX 4090 Graphic Card, 64 Gb Ram, Intel-i7 12700F, Windows 11 system and your nvidia dfl version. I cant chose better than 720x480 for camera input. And it gives only 30 FPS for 720x480. So final output gives 30 fps too. But m... | closed | 2023-05-31T14:21:08Z | 2023-05-31T14:23:21Z | https://github.com/iperov/DeepFaceLive/issues/169 | [] | Ridefort01 | 0 |
strawberry-graphql/strawberry | fastapi | 3,481 | `strawberry.Parent` not supporting forward refs | I would like the strawberry documentation on accessing parent with function resolvers on this [page](https://strawberry.rocks/docs/guides/accessing-parent-data#accessing-parents-data-in-function-resolvers) tweaked to be more clear, or maybe corrected?
From what I understand in the docs, its suggesting you end up wit... | open | 2024-05-01T16:35:23Z | 2025-03-20T15:56:43Z | https://github.com/strawberry-graphql/strawberry/issues/3481 | [
"bug"
] | andrewkruse | 7 |
graphdeco-inria/gaussian-splatting | computer-vision | 244 | SIBR compile error in windows: There is no provided GLEW library for your version of MSVC | Hi, I tried to compile the SIBR Viewer in Windows11, but I got error below.
I just installed the MinGW, Cmake and git. Do I need to install the MSVC?
Is there any advice? And is there a more detailed instruction about what to be installed? Thank you!
```
PS C:\Users\17670\Desktop\SIBR_viewers> cmake -Bbuild .
... | closed | 2023-09-26T16:50:41Z | 2023-10-10T19:54:21Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/244 | [] | Chuan-10 | 1 |
ultralytics/yolov5 | pytorch | 13,537 | how to set label smoothing in yolov8/yolov11? | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
how to set label smoothing in yolov8/yolov11?
### Additional
_No response_ | open | 2025-03-20T07:50:55Z | 2025-03-21T10:35:15Z | https://github.com/ultralytics/yolov5/issues/13537 | [
"question"
] | xuan-xuan6 | 4 |
strawberry-graphql/strawberry | graphql | 3,130 | Confusing Getting Started Guide | Hi, I'm brand new to Graphql and Strawberry and sorry if this is obvious but I was going through the getting started guide
and starting on Step 3. [Step 3: Define your data set](https://strawberry.rocks/docs#step-3-define-your-data-set) It doesn't specify if you are suppose to start a new file, so I'm assuming you are... | closed | 2023-10-02T14:14:08Z | 2025-03-20T15:56:24Z | https://github.com/strawberry-graphql/strawberry/issues/3130 | [] | JacobGoldenArt | 2 |
KaiyangZhou/deep-person-reid | computer-vision | 35 | Performance when training a model on one dataset and testing in another? | Just wondering, has anyone tried? Do you think it would be useful to try it or the results will be awful? | closed | 2018-07-13T00:26:11Z | 2018-08-31T02:43:31Z | https://github.com/KaiyangZhou/deep-person-reid/issues/35 | [] | ortegatron | 3 |
scikit-image/scikit-image | computer-vision | 7,083 | phase_cross_correlation returns tuple instead of np.array when disambiguate=True | ### Description:
According to its documentation, `ski.registration.phase_cross_correlation` returns a numpy array as a shift. However, when using the function with `disambiguate=True`, a tuple is returned.
### Way to reproduce:
```python
import numpy as np
import skimage as ski
im = np.random.randint(0, 100, ... | closed | 2023-08-02T16:40:24Z | 2023-09-20T10:40:30Z | https://github.com/scikit-image/scikit-image/issues/7083 | [
":bug: Bug"
] | m-albert | 5 |
jupyter/docker-stacks | jupyter | 2,043 | Conda environment not fully set in Jupyter | ### What docker image(s) are you using?
minimal-notebook
### Host OS system
CentOS
### Host architecture
x86_64
### What Docker command are you running?
sudo docker run -p8888:8888 --rm docker.io/jupyter/minimal-notebook:latest
(or standard run from JupyterHub)
### How to Reproduce the problem?
Start a Pyt... | closed | 2023-11-24T18:03:39Z | 2023-12-04T20:52:41Z | https://github.com/jupyter/docker-stacks/issues/2043 | [
"type:Bug"
] | nthiery | 6 |
nolar/kopf | asyncio | 359 | Helm 3 change triggers create insteand of update | > <a href="https://github.com/Carles-Figuerola"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/13749641?v=4"></a> An issue by [Carles-Figuerola](https://github.com/Carles-Figuerola) at _2020-05-07 20:30:30+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/issues/359
> ... | open | 2020-08-18T20:04:36Z | 2020-08-23T20:57:59Z | https://github.com/nolar/kopf/issues/359 | [
"question",
"archive"
] | kopf-archiver[bot] | 0 |
jupyter/docker-stacks | jupyter | 1,779 | [BUG] - Docker images for ubuntu 20.04 not updated | ### What docker image(s) are you using?
base-notebook, datascience-notebook, minimal-notebook, pyspark-notebook, r-notebook, scipy-notebook, tensorflow-notebook
### OS system and architecture running docker image
amd64
### What Docker command are you running?
On dockerhub, the last ubuntu 20.04 images are a month ... | closed | 2022-09-02T01:16:40Z | 2022-10-10T14:07:39Z | https://github.com/jupyter/docker-stacks/issues/1779 | [
"type:Bug"
] | tiaden | 3 |
dask/dask | pandas | 11,595 | Supporting inconsistent schemas in read_json | If you have two (jsonl) files where one contains columns `{"id", "text"}` and the other contains `{"text", "id", "meta"}` and you wish to read the two files using `dd.read_json([file1.jsonl, file2.jsonl], lines=True)` we run into an error
```
Metadata mismatch found in `from_delayed`.
Partition type: `pandas.cor... | open | 2024-12-10T18:24:48Z | 2025-02-24T02:01:24Z | https://github.com/dask/dask/issues/11595 | [
"dataframe",
"needs attention",
"feature"
] | praateekmahajan | 1 |
supabase/supabase-py | fastapi | 1 | create project base structure | Use [postgrest-py](https://github.com/supabase/postgrest-py) and [supabase-js](https://github.com/supabase/supabase-js) as reference implementations
| closed | 2020-08-28T06:38:31Z | 2021-04-01T18:44:49Z | https://github.com/supabase/supabase-py/issues/1 | [
"help wanted"
] | awalias | 0 |
netbox-community/netbox | django | 18,453 | Multiple Tunnel Terminations support | ### NetBox version
v4.1.2
### Feature type
New functionality
### Proposed functionality
I wanna Define Multiple Tunnel Terminations point for several Tunnel installed in same device
### Use case
Site To Site Ipsec Tunnel
### Database changes
_No response_
### External dependencies
_No response_ | closed | 2025-01-22T09:49:53Z | 2025-03-13T04:23:15Z | https://github.com/netbox-community/netbox/issues/18453 | [
"type: feature",
"status: revisions needed",
"pending closure"
] | l0rdmaster | 3 |
FlareSolverr/FlareSolverr | api | 1,375 | [yggtorrent] (testing) Exception (yggtorrent): FlareSolverr was unable to process the request, please check FlareSolverr logs. | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2024-09-30T15:21:01Z | 2024-10-05T04:14:02Z | https://github.com/FlareSolverr/FlareSolverr/issues/1375 | [] | DaGreenX | 7 |
scikit-tda/kepler-mapper | data-visualization | 211 | try different min_intersections from the visualization | I'm thinking about implementing this -- make changing the min_intersection before drawing an edge possible to do from the js visualization | closed | 2021-02-12T23:59:11Z | 2021-10-09T23:14:42Z | https://github.com/scikit-tda/kepler-mapper/issues/211 | [] | deargle | 0 |
qubvel-org/segmentation_models.pytorch | computer-vision | 628 | Colab notebook not found | https://github.com/googlecolab/colabtools/blob/master/examples/binary_segmentation_intro.ipynb linked on readme returns Notebook not found | closed | 2022-08-05T12:40:20Z | 2022-10-12T02:18:34Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/628 | [
"Stale"
] | robmarkcole | 5 |
pydata/pandas-datareader | pandas | 405 | NaN for the start date | Hello,
I just experienced a strange behaviour with some European Equities:
`
import pandas_datareader.data as web
start='2017-05-25'
end='2017-10-01'
f=web.DataReader('ASML.AS', 'yahoo', start=start, end=end)
`
The first line of the resulting DF is 2017-05-24 and it has NaN for all attributes (open, high, ... | closed | 2017-10-02T20:17:55Z | 2018-01-18T16:23:42Z | https://github.com/pydata/pandas-datareader/issues/405 | [
"yahoo-finance"
] | ComeAsUAre | 1 |
allenai/allennlp | nlp | 4,823 | Add the Gaussian Error Linear Unit as an Activation option | The [Gaussian Error Linear Unit](https://arxiv.org/pdf/1606.08415.pdf) activation is currently not a possible option from the set of registered Activations. Since this class just directly called the PyTorch classes - adding this in is a 1 line addition. Motivation is that models like BART/BERT use this activation in ma... | closed | 2020-11-26T18:20:18Z | 2020-12-02T04:04:05Z | https://github.com/allenai/allennlp/issues/4823 | [
"Feature request"
] | tomsherborne | 1 |
Esri/arcgis-python-api | jupyter | 1,370 | Errors Trying to Install ArcGIS in Anaconda Navigator | **Describe the bug**
I am running into a long list of errors trying to install ArcGIS into my Anaconda Navigator, but I believe the critical one is: ModuleNotFoundError: Required requests_ntlm not found.
**Platform (please complete the following information):**
- Windows 10
- Microsoft Edge
- Python 3.9
*... | closed | 2022-10-26T22:34:05Z | 2022-10-27T18:26:42Z | https://github.com/Esri/arcgis-python-api/issues/1370 | [
"bug"
] | tomasliutsung | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.