
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
FactoryBoy/factory_boy | sqlalchemy | 1,073 | Protect `master` branch to prevent accidents | I saw this on the home page:

I assume this was an accidental oversight... Or is there a reason this isn't currently enabled?
On other projects I help maintain, typically we setup the following:
1. `master` is loc... | closed | 2024-04-23T22:41:26Z | 2024-08-17T15:53:39Z | https://github.com/FactoryBoy/factory_boy/issues/1073 | [] | jeffwidman | 1 |
thtrieu/darkflow | tensorflow | 726 | Download datasets | I want to download images of apple fruit where can i download dataset | open | 2018-04-18T05:37:16Z | 2018-04-19T17:01:41Z | https://github.com/thtrieu/darkflow/issues/726 | [] | rucsacman | 1 |
3b1b/manim | python | 1,446 | Error while installing manim | ### Describe the error
Error while running test program in Manim
### Code and Error
**Code**:
manimgl example_scenes.py OpeningManimExample
**Error**:
Traceback (most recent call last):
File "/home/akhil/anaconda3/envs/manim/bin/manimgl", line 6, in <module>
from manimlib.__main__ import main
File... | closed | 2021-03-24T12:35:35Z | 2022-01-31T07:21:06Z | https://github.com/3b1b/manim/issues/1446 | [] | AkhilAkkapelli | 0 |
google-research/bert | nlp | 627 | BUG: 'truncate_seq_pair' | Hi,
I find something confused.
```
def truncate_seq_pair(tokens_a, tokens_b, max_num_tokens, rng):
"""Truncates a pair of sequences to a maximum sequence length."""
while True:
total_length = len(tokens_a) + len(tokens_b)
if total_length <= max_num_tokens:
break
tr... | open | 2019-05-08T09:03:15Z | 2019-05-08T09:03:15Z | https://github.com/google-research/bert/issues/627 | [] | moonlight1776 | 0 |
robotframework/robotframework | automation | 4,980 | DateTime library uses deprecated `datetime.utcnow()` | [datetime.datetime.utcnow()](https://docs.python.org/3/library/datetime.html#datetime.datetime.utcnow) has been deprecated in Python 3.12 and `datetime.datetime.now(datetime.UTC)` should be used instead. That `datetime.UTC` is new in Python 3.11, so we need to use either version or feature detection to avoid using it w... | closed | 2023-12-18T08:21:10Z | 2023-12-20T23:39:01Z | https://github.com/robotframework/robotframework/issues/4980 | [
"bug",
"priority: medium",
"rc 1",
"effort: small"
] | pekkaklarck | 1 |
jupyter/nbgrader | jupyter | 1,555 | `ImportError: cannot import name 'contextfilter' from 'jinja2'` | Using nbgrader 0.6.2 (also tried with 0.7.0-dev)
```
jupyter-nbconvert \
--Exporter.preprocessors=nbgrader.preprocessors.LockCells \
--Exporter.preprocessors=nbgrader.preprocessors.ClearSolutions \
--Exporter.preprocessors=nbgrader.preprocessors.ClearOutput \
--Exporter.preprocessors=nbgrader.preprocessors.... | closed | 2022-04-02T15:13:19Z | 2022-04-04T16:45:05Z | https://github.com/jupyter/nbgrader/issues/1555 | [] | goekce | 2 |
graphdeco-inria/gaussian-splatting | computer-vision | 798 | Training time breakdown | In the paper, the author mentioned that "The majority (∼80%) of our training time is spent in Python code, since...". However, I did a runtime breakdown on traing of 3DGS using torch.cuda.Event(), and it turns out that most of the time is spent on the backward propagation(which is implemented by CUDA), can anyone pleas... | closed | 2024-05-09T13:47:00Z | 2024-05-09T13:47:24Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/798 | [] | AmeYatoro | 0 |
marimo-team/marimo | data-visualization | 4,148 | Notebook move to "no folder" does not work on dashboard project | ### Describe the bug
If you select the "..." menu dropdown on a notebook in a project folder, choose "Move to folder", and select "No folder", nothing happens. I think it's supposed to move the notebook to the root folder of the project.
### Environment
This happened in `marimo.io/dashboard/projects?folder=****`.
... | open | 2025-03-18T14:36:52Z | 2025-03-18T14:36:52Z | https://github.com/marimo-team/marimo/issues/4148 | [
"bug"
] | dchassin | 0 |
robotframework/robotframework | automation | 5,219 | Support stopping execution using `robot:exit-on-failure` tag | The command line argument `--exitonfailure` has been very useful. If we can have a reserved tag `robot:exit-on-failure` that would be great so that the same behavior can be enabled in individual test suite. For example:
`suite1.robot`:
```
*** Settings ***
Test Tags robot:exit-on-failure
*** Test Cases ***
... | closed | 2024-09-24T15:54:43Z | 2024-12-18T13:33:02Z | https://github.com/robotframework/robotframework/issues/5219 | [
"enhancement",
"priority: medium",
"beta 1",
"effort: small"
] | douglasdotc | 1 |
ymcui/Chinese-BERT-wwm | tensorflow | 74 | 对于对话文本的阅读理解的效果怎样 | 感谢开源,对于描述类的文本看到有较好的效果可是对于对话形式的文本呢。 | closed | 2019-11-13T10:39:27Z | 2019-11-18T12:34:39Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/74 | [] | victor-wzq | 1 |
mage-ai/mage-ai | data-science | 5,697 | Search trigger by name in the UI | It would be very useful if we could search for pipeline name in the Triggers page, specially when you have pages of trigger, like in the example below.

| open | 2025-02-14T11:20:34Z | 2025-02-14T11:20:34Z | https://github.com/mage-ai/mage-ai/issues/5697 | [] | messerzen | 0 |
microsoft/JARVIS | pytorch | 7 | Where is the code? | closed | 2023-04-03T05:10:23Z | 2023-04-03T06:41:58Z | https://github.com/microsoft/JARVIS/issues/7 | [] | tensorboy | 1 | |
Anjok07/ultimatevocalremovergui | pytorch | 1,166 | Debugging | Hello, if you can change the internal bitvise software so that it automatically downloads and installs the latest version. | open | 2024-02-13T06:27:22Z | 2024-02-13T06:27:22Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1166 | [] | shayanspd | 0 |
flaskbb/flaskbb | flask | 378 | ValueError: unsupported pickle protocol: 4 | Can you help me? How can i solve the problem?
flaskbb version:
(.flaskbb)[root@python flaskbb]# flaskbb --version
FlaskBB 1.0 using Flask 0.12.1 on Python 2.7.5 (default, Aug 4 2017, 00:39:18)
The error:
(.flaskbb)[root@python flaskbb]# flaskbb --config flaskbb.cfg run
/usr/lib/python2.7/site-packages/pym... | closed | 2017-12-16T05:58:27Z | 2018-04-15T07:47:49Z | https://github.com/flaskbb/flaskbb/issues/378 | [
"bug"
] | 582727501 | 4 |
mitmproxy/mitmproxy | python | 7,423 | Merge of Set-Cookie response headers in reverse mode causes Firefox browser to not recognize all cookies | #### Problem Description
A clear and concise description of what the bug is.
#### Steps to reproduce the behavior:
In anti proxy mode, the source server response contains multiple Set Cookie headers, but mitmproxy automatically merges them, resulting in some websites only recognizing the first cookie.
The web... | closed | 2024-12-29T17:16:15Z | 2024-12-30T09:21:41Z | https://github.com/mitmproxy/mitmproxy/issues/7423 | [
"kind/triage"
] | yinsel | 4 |
3b1b/manim | python | 1,925 | Different expressions of pi creatures were found. Should we put them in the repository? | Now all pi creatures are able to get:
https://github.com/CaftBotti/manim_pi_creatures
They are from 3blue1brown.com, maybe they are using in 3b1b videos.
That repository also includes pi_creature.py, it is from cairo-backend, but i changed a little to use the different picreatures, you just need to put the picreatur... | closed | 2022-12-10T09:03:28Z | 2022-12-10T15:07:57Z | https://github.com/3b1b/manim/issues/1925 | [] | CaftBotti | 1 |
fastapi-users/fastapi-users | fastapi | 220 | [feature request] route to generate tokens with equal or less access | The idea is that if a token can use some scopes (e.g. user:register, user:read, user:delete), he should be able to create a token for equal or smaller access.
Let's say, I have a token that expires in 1 day and has permissions `user:register, user:read`, I can generate a new token with just `user:read`, then I can mak... | closed | 2020-06-03T19:37:55Z | 2020-06-15T12:31:20Z | https://github.com/fastapi-users/fastapi-users/issues/220 | [
"duplicate"
] | nullhack | 2 |
davidteather/TikTok-Api | api | 213 | [BUG] - ByHashtag Not Working |
I run the bytag code and get the below error.
I have installed chromedriver and works properly.
{'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.0 Safari/537.36)', 'accept-encoding': 'gzip, deflate, br', 'accept': 'application/json, text/plain, ... | closed | 2020-08-11T15:27:14Z | 2020-08-11T20:35:04Z | https://github.com/davidteather/TikTok-Api/issues/213 | [
"bug"
] | soleimanian | 3 |
comfyanonymous/ComfyUI | pytorch | 6,472 | No module named 'ComfyUI-CCSR' | ### Your question
I'm trying to run a simple workflow and even though I have downloaded the correct model I keep getting an error that does not make it clear what I'm missing.

### Logs
```powershell
# ComfyUI Error Report
... | closed | 2025-01-15T01:12:25Z | 2025-01-15T01:37:11Z | https://github.com/comfyanonymous/ComfyUI/issues/6472 | [
"User Support"
] | dodgingspam | 1 |
xonsh/xonsh | data-science | 5,092 | The way to disable environment variable validation | We have validation for `*DIRS`:
https://github.com/xonsh/xonsh/blob/076ea2583f14485bc910c9f9b74561bfc9ca0094/xonsh/environ.py#L1232
But there is a case in [Jupyter](https://stackoverflow.com/questions/74734191/how-to-set-the-environment-variable-jupyter-platform-dirs-1):
>DeprecationWarning: Jupyter is migrati... | open | 2023-03-16T20:51:47Z | 2023-03-25T19:59:23Z | https://github.com/xonsh/xonsh/issues/5092 | [
"environ",
"priority-low"
] | anki-code | 0 |
pytest-dev/pytest-html | pytest | 612 | Implement better solution for DOM manipulation | We need a better solution/implementation for handling the DOM manipulation hooks.
They rely on primitives/low-level python API which is bad and extremely hacky with the new way of generating the report.
See #611 | open | 2023-04-01T23:19:45Z | 2023-04-01T23:19:49Z | https://github.com/pytest-dev/pytest-html/issues/612 | [] | BeyondEvil | 0 |
keras-team/keras | pytorch | 20,699 | The default setting for aggregation='mean' for variables and optimizers is incorrect. |
The default policy with aggregation='mean' is incorrect and should be set to none. In a distributed context, the backend handles gradient reduction and variable updates, eliminating the need for intermediate aggregations. Using aggregation='mean' breaks moment estimation in the optimizer. Ref: In keras==2.15.0, the d... | closed | 2024-12-28T16:40:30Z | 2024-12-31T04:22:19Z | https://github.com/keras-team/keras/issues/20699 | [] | loveyou143j | 0 |
ultralytics/yolov5 | deep-learning | 13,238 | How can I save the detections Yolov5 makes when he's working with a camera source? | Hi! Soo what I want to do is that my Yolov5 model saves in a folder the detections it makes when working with a camera in real time, in my Raspberry PI 4B+.
I found this code made by glenn-jocher responding to user sanchaykasturey at the following link:
https://github.com/ultralytics/yolov5/issues/11102, and I tri... | closed | 2024-08-01T03:47:26Z | 2024-10-20T19:51:14Z | https://github.com/ultralytics/yolov5/issues/13238 | [
"question"
] | ComederoAVES2024 | 4 |
graphql-python/graphene-django | django | 1,079 | Make input fields not required for DRF Serialize | **Is your feature request related to a problem? Please describe.**
I have a model and DRF serializer.
```
class Center(models.Model):
name = models.CharField(max_length=255) # required
homepage = models.URLField(null=True, blank=True)
class CenterSerializer(serializers.ModelSerializer):
cl... | closed | 2020-12-27T10:52:44Z | 2021-01-02T06:20:08Z | https://github.com/graphql-python/graphene-django/issues/1079 | [
"✨enhancement"
] | rganeyev | 2 |
yunjey/pytorch-tutorial | pytorch | 195 | RNN input size question | I'm new to pytorch, Can anyone answer my question which confused me a lot:
[In RNN tutorial](https://github.com/yunjey/pytorch-tutorial/blob/master/tutorials/02-intermediate/recurrent_neural_network/main.py)
images are reshaped into (batch, seq_len, input_size)
```
images = images.reshape(-1, sequence_length, i... | closed | 2019-11-20T00:39:00Z | 2019-11-21T05:32:10Z | https://github.com/yunjey/pytorch-tutorial/issues/195 | [] | OrangeC93 | 2 |
aimhubio/aim | tensorflow | 3,300 | Switch GitHub PR workflows run on the latest python version. | Currently, it looks like pull requests are tested on [python 3.8](https://github.com/aimhubio/aim/blob/main/.github/workflows/pull-request.yml). Can we update this workflow to run on the latest supported python version for aim (3.12)?
| closed | 2025-03-05T21:31:52Z | 2025-03-05T23:49:07Z | https://github.com/aimhubio/aim/issues/3300 | [
"type / code-health"
] | amifalk | 1 |
huggingface/datasets | deep-learning | 6,937 | JSON loader implicitly coerces floats to integers | The JSON loader implicitly coerces floats to integers.
The column values `[0.0, 1.0, 2.0]` are coerced to `[0, 1, 2]`.
See CI error in dataset-viewer: https://github.com/huggingface/dataset-viewer/actions/runs/9290164936/job/25576926446
```
=================================== FAILURES ===========================... | open | 2024-05-31T08:09:12Z | 2024-05-31T08:11:57Z | https://github.com/huggingface/datasets/issues/6937 | [
"bug"
] | albertvillanova | 0 |
BeanieODM/beanie | pydantic | 649 | [BUG] ModuleNotFoundError: No module named 'pydantic_settings' | **Describe the bug**
Trying to import beanie and _ModuleNotFoundError_ raises.
**To Reproduce**
```python
import beanie
```
**Expected behavior**
Successful import.
**Additional context**
I am also running pydantic v2.
Error:
`ModuleNotFoundError: No module named 'pydantic_settings'`
| closed | 2023-08-09T16:33:59Z | 2023-10-01T01:50:22Z | https://github.com/BeanieODM/beanie/issues/649 | [
"Stale"
] | arynyklas | 4 |
apify/crawlee-python | web-scraping | 496 | Throw an exception when we receive a 4xx status code | See https://github.com/apify/crawlee-python/issues/486 for motivation and details. | closed | 2024-09-04T06:08:39Z | 2024-09-06T13:36:13Z | https://github.com/apify/crawlee-python/issues/496 | [
"bug",
"t-tooling"
] | janbuchar | 0 |
healthchecks/healthchecks | django | 1,007 | Return UUID in "List Existing Checks" response | Just a minor quality-of-life request: have you considered returning a field with just the UUID in the `GET https://healthchecks.io/api/v3/checks/` response (assuming using a read-write API key)? It looks like the UUID can be extracted from the `ping_url` field, but would parsing that is still slightly error-prone and p... | closed | 2024-05-30T23:03:32Z | 2024-07-18T16:31:15Z | https://github.com/healthchecks/healthchecks/issues/1007 | [] | chriselion | 4 |
tflearn/tflearn | data-science | 1,056 | About examples/images/alexnet.py | in AlexNet ,
the order of the first and second layers is ( conv——LRN——maxPool )
but in your code
`network = input_data(shape=[None, 227, 227, 3])`
`network = conv_2d(network, 96, 11, strides=4, activation='relu')`
`network = max_pool_2d(network, 3, strides=2)`
`network = local_response_normalization(network)`... | open | 2018-05-25T06:43:09Z | 2018-05-25T07:05:23Z | https://github.com/tflearn/tflearn/issues/1056 | [] | SmokerX | 1 |
ultralytics/ultralytics | python | 18,718 | Draw / visualize ground truth annotations for segmentation | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/ultralytics/ultralytics/discussions) and found no similar questions.
### Question
As a standard step before training, I wanted to make sure that the gr... | closed | 2025-01-16T22:27:21Z | 2025-01-25T00:14:03Z | https://github.com/ultralytics/ultralytics/issues/18718 | [
"question",
"segment"
] | duklin | 8 |
encode/apistar | api | 340 | Misspelling in exception | apistar.exceptions.ConfigurationError: Route **wtih** name "welcome" exists more than once. Use an explicit name="..." on the Route to avoid a conflict.
apistar/components/router.py, line 27, in __init__
| closed | 2017-10-25T06:54:31Z | 2018-03-13T14:25:36Z | https://github.com/encode/apistar/issues/340 | [] | vulnersCom | 2 |
iperov/DeepFaceLab | deep-learning | 956 | Issue with dual GTX 1080TI cards | Hi everyone, I just bought 2 GTX 1080TI cards. I have installed them and they are recognized by the system, the drivers are up to date. One is on PCI16X (which obviously works at 8x) and the second is on PCIE4X (I have Asus crossfire motherboard).
NO SLI CONNECTION
When I launch DFL I immediately get this error a... | closed | 2020-11-24T00:05:24Z | 2020-11-27T12:39:06Z | https://github.com/iperov/DeepFaceLab/issues/956 | [] | fuorissimo | 0 |
airtai/faststream | asyncio | 2,016 | Feature: Manual commit Kafka | Is it possible to do manual commit with Kafka ? I don't find this feature in the doc.
| closed | 2025-01-02T14:12:25Z | 2025-01-03T12:50:13Z | https://github.com/airtai/faststream/issues/2016 | [
"enhancement"
] | Renaud-ia | 3 |
pytest-dev/pytest-cov | pytest | 437 | coverage starts too late with warning filter | # Summary
When trying to get coverage on something like `myproject`, while also running a warning filter on a warning within that project, say `myproject.MyWarning` coverage is started too late. For example:
```
python -m pytest -W error::myproject.MyWarning --cov=myproject tests/
```
will result in `myproject` ... | open | 2020-09-30T06:35:16Z | 2024-04-22T13:32:21Z | https://github.com/pytest-dev/pytest-cov/issues/437 | [] | dopplershift | 3 |
miguelgrinberg/Flask-SocketIO | flask | 1,068 | what is the uwsgi config file for runing websockets through nginx flask-socketio | uwsgi --http 0.0.0.0:8000 --gevent 1000 --http-websockets --master --wsgi-file socketexample/main.py --callable app
what is uwsgi config file for this one , do have any suggestions for this one? | closed | 2019-09-24T12:18:13Z | 2019-09-24T12:39:55Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1068 | [] | Sudheertati | 1 |
kymatio/kymatio | numpy | 75 | [BUG] ... typo that killed the unit tests... | https://github.com/eickenberg/scattering_transform/blob/master/scattering/scattering2d/tests/test_scattering.py#L17
Damn. It means there was no unit tests since a while and that it was if were on a free fall for a while
🥇 | closed | 2018-10-29T21:14:38Z | 2018-10-30T10:41:13Z | https://github.com/kymatio/kymatio/issues/75 | [
"bug",
"high priority"
] | edouardoyallon | 1 |
deepfakes/faceswap | machine-learning | 488 | Extract with dlib-cnn doesn't work on macOS | **Note: Please only report bugs in this repository. Just because you are getting an error message does not automatically mean you have discovered a bug. If you don't have a lot of experience with this type of project, or if you need for setup help and other issues in using the faceswap tool, please refer to the [facesw... | closed | 2018-09-03T02:38:06Z | 2018-10-22T06:56:13Z | https://github.com/deepfakes/faceswap/issues/488 | [
"bug"
] | helloall1900 | 2 |
explosion/spaCy | deep-learning | 12,012 | Add an example on how to discover available extensions on a Doc/Span/Token object | New to spacy and I was searching the Doc API documentation ([https://spacy.io/api/doc](https://spacy.io/api/doc)) on extensions about how to "discover" what extensions would be available on a given doc/span/token object.
The use-case would have been discovering the available extensions of a doclike object returned by... | closed | 2022-12-21T16:08:57Z | 2023-02-23T14:06:14Z | https://github.com/explosion/spaCy/issues/12012 | [
"enhancement",
"feat / doc"
] | mattkeanny | 3 |
tfranzel/drf-spectacular | rest-api | 598 | Allow globally excluding certain content types | By default, (I believe because DRF supports the Browsable Web API) `drf-spectacular` will generate a schema with both `form-data` and `json` content types:
```yaml
requestBody:
content:
application/json:
schema:
type: array
items:
... | closed | 2021-11-09T16:18:13Z | 2025-03-13T05:25:31Z | https://github.com/tfranzel/drf-spectacular/issues/598 | [
"enhancement",
"fix confirmation pending"
] | johnthagen | 11 |
hpcaitech/ColossalAI | deep-learning | 6,200 | Does GeminiPlugin support DeepSeek V3? | How can we finetune or continue-pretrain DeepSeek V3 using GeminiPlugin?
Thanks a lot. | closed | 2025-02-19T06:57:57Z | 2025-02-20T04:01:13Z | https://github.com/hpcaitech/ColossalAI/issues/6200 | [] | ericxsun | 1 |
man-group/arctic | pandas | 663 | Versions should include metadata for the arctic version used to create it | #### Arctic Version
```
1.72.0
```
#### Arctic Store
```
VersionStore
```
#### Description of problem and/or code sample that reproduces the issue
We need to have finer control and visibility about the version of arctic which was used to crate a new version for Version store.
| closed | 2018-11-22T19:57:10Z | 2018-11-27T14:55:37Z | https://github.com/man-group/arctic/issues/663 | [
"enhancement",
"feature"
] | dimosped | 0 |
huggingface/datasets | pandas | 7,147 | IterableDataset strange deadlock | ### Describe the bug
```
import datasets
import torch.utils.data
num_shards = 1024
def gen(shards):
for shard in shards:
if shard < 25:
yield {"shard": shard}
def main():
dataset = datasets.IterableDataset.from_generator(
gen,
gen_kwargs={"shards": lis... | closed | 2024-09-12T18:59:33Z | 2024-09-23T09:32:27Z | https://github.com/huggingface/datasets/issues/7147 | [] | jonathanasdf | 6 |
NVIDIA/pix2pixHD | computer-vision | 18 | Perceptual Loss Issues | Hi: @mingyuliutw @junyanz
I have read your paper carefully, I noticed you use a perceptual loss in paper with hyperparameters λ=10, weights = 1/Mi and Mi is the number of elements of i-th layer in VGG19, however, I checked the codes you released where the weight of loss is [1.0/32, 1.0/16, 1.0/8, 1.0/4, 1.0], I am ... | closed | 2018-01-30T06:11:04Z | 2018-05-20T08:16:06Z | https://github.com/NVIDIA/pix2pixHD/issues/18 | [] | iRmantou | 3 |
lexiforest/curl_cffi | web-scraping | 402 | [BUG]ValueError: not enough values to unpack (expected 2, got 1) | **Describe the bug**
```
curl_cffi\requests\headers.py", line 132, in __init__
k, v = line.split(sep, maxsplit=1) # pyright: ignore
ValueError: not enough values to unpack (expected 2, got 1)
```
```
if isinstance(headers[0], (str, bytes)):
print(headers[0])
se... | closed | 2024-10-04T12:19:46Z | 2024-12-30T06:21:46Z | https://github.com/lexiforest/curl_cffi/issues/402 | [
"bug",
"needs more info"
] | wwang129 | 2 |
sktime/pytorch-forecasting | pandas | 1,695 | [MNT] `pre-commit` failing on `main` | **Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
`pre-commit` is failing on `main`, rendering it effectively unusable for other branches created from `main`.
**To Reproduce**
<!--
Add a Minimal, Complete, and Verifiable example (for more details, see e.g. https://stackoverflow.... | closed | 2024-10-09T08:59:51Z | 2024-10-10T10:12:04Z | https://github.com/sktime/pytorch-forecasting/issues/1695 | [
"bug"
] | ewth | 1 |
jina-ai/clip-as-service | pytorch | 270 | Load fine-tuned pytorch model | Is it possible to load a model fine-tuned with [huggingface's](https://github.com/huggingface/pytorch-pretrained-BERT) pytorch implementation? | open | 2019-03-13T15:46:30Z | 2019-07-17T21:24:48Z | https://github.com/jina-ai/clip-as-service/issues/270 | [] | v1nc3nt27 | 2 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,250 | Login fails when odbc_connect PWD= includes a plus sign | ### Describe the bug
When `odbc_connect` is given a properly-formed ODBC connection string with a password that contains a plus sign, the plus sign is converted to a space and the login fails.
### Optional link from https://docs.sqlalchemy.org which documents the behavior that is expected
_No response_
### SQLAlche... | closed | 2024-04-09T17:29:43Z | 2024-05-30T17:47:47Z | https://github.com/sqlalchemy/sqlalchemy/issues/11250 | [
"bug",
"SQL Server",
"quagmire"
] | gordthompson | 9 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 89 | Runtime error: Error running the bot: Error parsing YAML file. | Good afternoon! I went through all the steps and have matched my files to your example files and I am getting an error:
Runtime error: Error running the bot: Error parsing YAML file.
Refer to the configuration and troubleshooting guide: https://github.com/feder-cr/LinkedIn_AIHawk_automatic_job_application/blob/main/r... | closed | 2024-08-27T17:22:05Z | 2024-11-17T00:18:08Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/89 | [
"bug"
] | Securitydude3245 | 12 |
Lightning-AI/LitServe | rest-api | 72 | Add OpenAI as a pluggable spec | ## 🚀 Feature
We should enable serving a model through a spec, without having to implement it manually in `decode_request` and `encode_response`. The spec (could be more than one) would:
- expose a route
- implement specific ways of decoding requests and encoding responses
- require the API to expose certain ki... | closed | 2024-04-30T19:05:20Z | 2024-05-23T15:45:03Z | https://github.com/Lightning-AI/LitServe/issues/72 | [
"enhancement",
"help wanted"
] | lantiga | 1 |
nltk/nltk | nlp | 2,805 | proxy error | i used to get my output through nltk.set_proxy('http://user:password@ip:port') for like one year, but now this method is giving HTTP error, even by using the rule given by the nltk library which is ('http://ip:port',user,password)
 | Describe the problem
Using tensorflow.contrib produces a warning. The warning is
WARNING:tensorflow:From C:\Users\xxxx\Anaconda3\envs\tensorflow\lib\site-packages\tensorflow\contrib\learn\python\learn\datasets\base.py:198: retry (from tensorflow.contrib.learn.python.learn.datasets.base) is deprecated and will be ... | open | 2018-05-19T13:01:36Z | 2018-12-09T12:56:51Z | https://github.com/tflearn/tflearn/issues/1053 | [] | chanwing | 2 |
sherlock-project/sherlock | python | 2,322 | Requesting support for: Velog | ### Site URL
https://velog.io/
### Additional info
Velog is a popular development blogging platform in Korea.
Many Korean developers, especially junior developers, frequently use Velog to share their technical knowledge and experiences.
Sherlock can detect if a username exists on Velog by using:
1. URL Patt... | closed | 2024-10-09T09:02:17Z | 2024-11-01T08:51:07Z | https://github.com/sherlock-project/sherlock/issues/2322 | [
"site support request"
] | Nuung | 0 |
swisskyrepo/GraphQLmap | graphql | 38 | TypeError: can only concatenate str (not "NoneType") to str | ```
_____ _ ____ _
/ ____| | | / __ \| |
| | __ _ __ __ _ _ __ | |__ | | | | | _ __ ___ __ _ _ __
| | |_ | '__/ _` | '_ \| '_ \| | | | | | '_ ` _ \ / _` | '_ \
| |__| | | | (_| | |_) | | | | |__| | |____| | | | | | (_| | |_) |
\_____|_| \__,_| .__/|_| ... | open | 2022-01-18T22:12:18Z | 2022-01-20T22:49:46Z | https://github.com/swisskyrepo/GraphQLmap/issues/38 | [] | chevyphillip | 1 |
aeon-toolkit/aeon | scikit-learn | 2,619 | [DOC] Cell Output Error in Interval Based Classification | ### Describe the issue linked to the documentation


### Suggest a potential alternative/fix
_No response_ | closed | 2025-03-14T15:32:22Z | 2025-03-16T14:40:59Z | https://github.com/aeon-toolkit/aeon/issues/2619 | [
"documentation"
] | kavya-r30 | 2 |
huggingface/transformers | tensorflow | 36,550 | size mismatch for lm_head when fintune QWEN2.5 | ### System Info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 4.49.0
- Platform: Linux-6.6.0-72.0.0.64.oe2403.x86_64-x86_64-with-glibc2.38
- Python version: 3.10.16
- Huggingface_hub version: 0.29.1
- Safetensors version: 0.5.3
- Accelerate version: 1.4... | closed | 2025-03-05T03:54:51Z | 2025-03-10T02:50:17Z | https://github.com/huggingface/transformers/issues/36550 | [
"bug"
] | minmie | 8 |
smarie/python-pytest-cases | pytest | 195 | filter/skipif combination of cases from multiple parametrize_with_cases decorators | Hi, loving the library! I have a instance where I create a large number of test cases based on a combination of multiple parametrize_with_cases, a simple example here:
in test_package_cases.py:
```python
def encrypted_encrypted():
"""Return a key for a encrypted test."""
return KEY
def encrypted_une... | closed | 2021-03-31T12:09:11Z | 2021-05-18T13:09:04Z | https://github.com/smarie/python-pytest-cases/issues/195 | [
"has_workaround"
] | eavanvalkenburg | 8 |
microsoft/nni | deep-learning | 5,457 | Failed to create NNI experiment, error: AttributeError: 'dict' object has no attribute 'name' | **Describe the issue**:
But when I created the NNI experiment using the official example of Hyperparameter Optimization, I received the following error information:
```
Traceback (most recent call last):
File "/home/sunze/anaconda3/bin/nnictl", line 8, in <module>
sys.exit(parse_args())
File "/home/sunz... | closed | 2023-03-18T12:38:13Z | 2023-03-21T04:48:49Z | https://github.com/microsoft/nni/issues/5457 | [] | sunze992 | 4 |
koxudaxi/datamodel-code-generator | pydantic | 2,351 | Add option to disable Field constraints | **Is your feature request related to a problem? Please describe.**
I'm in the unfortunate position of having to consume an API that has incorrect constraints in its OpenAPI documentation. Up until now, I have been manually removing the Field constraints, but I was wondering if this could be a useful CLI flag for anyone... | open | 2025-03-20T19:44:36Z | 2025-03-21T15:53:23Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2351 | [] | harrymconner | 1 |
pytest-dev/pytest-xdist | pytest | 1,004 | How Master node can know info from Worker nodes after call pytest_collection_modifyitems? | Hello everyone!
I am using Terstrail plugin to report.
So I need to know the list of test cases collected when calling pytest_collection_modifyitems on each node.
Do you know how I can know this?
Thanks. | open | 2024-01-10T14:11:28Z | 2024-01-12T12:39:19Z | https://github.com/pytest-dev/pytest-xdist/issues/1004 | [] | voloxastik | 8 |
scikit-optimize/scikit-optimize | scikit-learn | 1,105 | BayesSearchCV multimetric scoring inconsistency: KeyError: 'mean_test_score' | I am working on a multilabel classification and for now I have primarily been relying on `RandomizedSearchCV` from `scikit-learn` to perform hyperparameter optimization. I now started experimenting with `BayesSearchCV` and ran into a potential bug when using multi-metric scoring, combined with the `refit` argument.
... | open | 2022-02-06T16:38:09Z | 2023-02-18T15:51:17Z | https://github.com/scikit-optimize/scikit-optimize/issues/1105 | [] | leweex95 | 3 |
alirezamika/autoscraper | automation | 13 | Not very reasonable, a lot of things change |
Not very reasonable, a lot of things change | closed | 2020-09-10T07:31:31Z | 2020-09-10T13:33:58Z | https://github.com/alirezamika/autoscraper/issues/13 | [] | abbabb123 | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 815 | Can someone link me some resources about model training? | I have polish voice database that is maybe not the best but I still want to try to make polish model.
I have loaded my database into encoder training and there were some errors connected with "visdom_server"
Please help me find some resources to train it. Some kind of tutorial or guide? | closed | 2021-08-10T07:55:58Z | 2022-06-13T22:00:09Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/815 | [] | justkowal | 2 |
google-research/bert | nlp | 778 | Did Chinese-only model strip out the accent mark? I mean the mark like "-" | Did Chinese-only model strip out the accent mark? I mean the mark like "-" . I need it. Should I use Multilingual Cased instead? | open | 2019-07-20T09:34:03Z | 2019-07-20T09:34:03Z | https://github.com/google-research/bert/issues/778 | [] | LiangYuHai | 0 |
svc-develop-team/so-vits-svc | pytorch | 120 | 训练中途可以修改学习率吗? | 可不可以在刚开始训练时用较大的学习率(0.0004),中途再改为正常的(0.0002,0.0001) | closed | 2023-04-04T09:19:12Z | 2023-08-01T09:09:42Z | https://github.com/svc-develop-team/so-vits-svc/issues/120 | [
"not urgent"
] | TQG1997 | 6 |
comfyanonymous/ComfyUI | pytorch | 6,796 | CLIP/text encoder load device: cpu | ### Your question
I am running comfyui on RTX 3090. All drivers updated, comfyui environment updated. I dont have an issue with image generation speed, it runs on GPU, but it took my attention :
CLIP/text encoder model load device: cpu, offload device: cpu, current: cpu, dtype: torch.float16
Should i accept this ... | closed | 2025-02-12T14:44:14Z | 2025-02-28T15:36:28Z | https://github.com/comfyanonymous/ComfyUI/issues/6796 | [
"User Support"
] | simartem | 6 |
yeongpin/cursor-free-vip | automation | 323 | [讨论]: 我在使用自定义邮箱,但是没有接收到验证码。我要怎么做 | ### Issue 检查清单
- [x] 我理解 Issue 是用于反馈和解决问题的,而非吐槽评论区,将尽可能提供更多信息帮助问题解决。
- [x] 我确认自己需要的是提出问题并且讨论问题,而不是 Bug 反馈或需求建议。
- [x] 我已阅读 [Github Issues](https://github.com/yeongpin/cursor-free-vip/issues) 并搜索了现有的 [开放 Issue](https://github.com/yeongpin/cursor-free-vip/issues) 和 [已关闭 Issue](https://github.com/yeongpin/cursor-free-vip... | closed | 2025-03-20T00:33:23Z | 2025-03-20T03:47:34Z | https://github.com/yeongpin/cursor-free-vip/issues/323 | [
"question"
] | MyMaskKing | 1 |
ray-project/ray | data-science | 50,823 | [Train] Unable to gain long-term access to S3 storage for training state/checkpoints when running on AWS EKS | ### What happened + What you expected to happen
I am using Ray Train + KubeRay to train on AWS EKS. I have configured EKS to give Ray pods a specific IAM role through Pod Identity Association. EKS Pod Identity Association provides a HTTP endpoint through which an application can "assume said IAM role" - i.e. gain a se... | open | 2025-02-22T05:18:57Z | 2025-03-05T01:25:36Z | https://github.com/ray-project/ray/issues/50823 | [
"bug",
"P1",
"triage",
"train"
] | jleben | 1 |
graphdeco-inria/gaussian-splatting | computer-vision | 503 | Any suggestions on using lidar point clouds to initialize 3dgs to reconstruct large scenes | I'm trying to reconstruct a relatively large indoor scene using the 3dgs algorithm, in this case using colmap can easily fail due to the large number of low texture and similar areas in the interior. So I tried exporting the point cloud and pose from polycam and from there, trained 3dgs.
It is worth noting that the po... | closed | 2023-11-29T09:36:36Z | 2024-08-07T02:49:18Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/503 | [] | Bin-ze | 4 |
vitalik/django-ninja | pydantic | 1,227 | [BUG] Primary keys are always marked as nullable | **Describe the bug**
As a result of #1181, all primary keys are now marked as nullable in ModelSchema, regardless of whether the field is set to nullable or not. I'm not sure why this was done, but I would expect it to defer to the field's own nullable setting instead if for some reason you have a nullable primary key... | open | 2024-07-11T14:38:51Z | 2024-08-02T18:22:47Z | https://github.com/vitalik/django-ninja/issues/1227 | [] | pmdevita | 3 |
ydataai/ydata-profiling | pandas | 1,068 | tangled-up-in-unicode dependency means installing pandas-profiling takes ~2GB | ### Current Behaviour
```
⊙ python3.10 -m venv venv && venv/bin/python -m pip install --quiet pandas-profiling
...
⊙ du -ha venv | sort -h | tail -n 20 julian@Airm
25M ven... | closed | 2022-09-23T11:54:14Z | 2023-06-03T02:16:18Z | https://github.com/ydataai/ydata-profiling/issues/1068 | [
"dependencies 🔗"
] | Julian | 4 |
dpgaspar/Flask-AppBuilder | flask | 1,533 | FilterEqualFunction on Mongoengine | Hi, I've seen in the past you implemented in aminor release FilterEqualFunction on mongoengine. Any chances to get it in some new release?
Thanks | closed | 2020-12-17T13:40:32Z | 2021-06-29T00:56:13Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1533 | [
"stale"
] | amaioli | 1 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 280 | Out of memory error | Hello
XXXXXXXX-deskcomputer:~/Projects/photo_restoration$ python run.py --input_folder /home/XXXXXX/Videos/08281965BC/Test/ --output_folder /home/XXXXXX/Videos/08281965BC/ColorCorrected/ --GPU 0 --HR
Running Stage 1: Overall restoration
Mapping: You are using the mapping model without global restoration.
Traceb... | open | 2023-09-10T13:28:24Z | 2023-09-10T13:28:24Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/280 | [] | c1arocque | 0 |
gradio-app/gradio | data-visualization | 10,532 | dropdowns in apps built with gradio are not accessible for screenreaders | ### Describe the bug
All apps built with gradio I've used so far have this issue. When using a screenreader such as nvda:
https://www.nvaccess.org/
There is an issue which makes it unable for blind or visually impaired screenreader users to choose something from dropdowns in gradio UI.
The list is being presented as... | open | 2025-02-06T23:14:40Z | 2025-02-07T03:31:26Z | https://github.com/gradio-app/gradio/issues/10532 | [
"bug",
"svelte"
] | VIPPotato | 0 |
plotly/dash | plotly | 2,346 | Allow a "cleanup" callback that is executed when a session ends | It would be nice to have something like this, sort of the opposite of a `serve_layout()` function that gets executed with `app.layout` for every new session. This would allow, for example, server-side storing (e.g. using Redis) that would delete session data when the user disconnects.
```python
def serve_layout():
... | open | 2022-12-01T05:11:56Z | 2024-08-13T19:23:42Z | https://github.com/plotly/dash/issues/2346 | [
"feature",
"P3"
] | xhluca | 0 |
predict-idlab/plotly-resampler | plotly | 132 | FigureResampler not working when using backend parameter on ServersideOutputTransform | Hello and thank you for this awesome project.
I'm trying to specify backend parameter on ServersideOutputTransform in order to set threshold parameter on FileSystemCache, but then if I do that my callback with fig.construct_update_data(relayoutdata) stop working. Any idea about why this is happening?
Code:
```... | closed | 2022-11-07T16:12:11Z | 2023-10-25T22:59:20Z | https://github.com/predict-idlab/plotly-resampler/issues/132 | [] | VictorBauler | 2 |
jupyter-book/jupyter-book | jupyter | 1,528 | Plotly and dollarmath don't work unless using mathjax2 | ### Describe the problem
I have noticed that after adding the myst extension "dollarmath" plotly graphs stopped rendering.
Looking at the browser console I could see these errors:
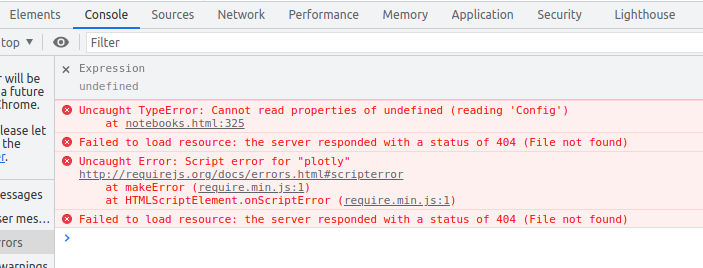
Going to the noteboo... | closed | 2021-10-28T23:06:51Z | 2023-10-13T00:04:42Z | https://github.com/jupyter-book/jupyter-book/issues/1528 | [
"bug"
] | raphaeltimbo | 10 |
desec-io/desec-stack | rest-api | 412 | [Feature Request] DynDNS API can update subdomains | **Feature Description:**
Using the [dynDNS API] it is possible to update `A` and `AAAA` records of sub-domains, e.g. `sub.main.dedyn.io`.
One possible way to achieve this would be via the already existing `hostname` parameter in the API:
```
curl -u main.dedyn.io:<token> https://update.dedyn.io/?hostname=sub.... | closed | 2020-06-10T12:08:57Z | 2024-10-07T17:21:54Z | https://github.com/desec-io/desec-stack/issues/412 | [
"enhancement",
"api",
"prio: high",
"easy"
] | hcc23 | 8 |
fastapi-users/fastapi-users | asyncio | 1,099 | asyncio.exceptions.CancelledError | ## Describe the bug
I am running the full example in a fastapi application and I am regularly running into `asyncio.exceptions.CancelledError`.
```
api_1 | INFO: 172.20.0.1:51026 - "POST /auth/jwt/login HTTP/1.1" 200 OK
api_1 | INFO: 172.20.0.1:51032 - "POST /auth/jwt/login HTT... | closed | 2022-10-20T13:12:16Z | 2022-10-23T07:47:59Z | https://github.com/fastapi-users/fastapi-users/issues/1099 | [
"bug"
] | bert2002 | 0 |
darrenburns/posting | rest-api | 185 | vim mode? | is there any plans to add vim mode | open | 2025-02-11T18:41:52Z | 2025-03-17T01:10:40Z | https://github.com/darrenburns/posting/issues/185 | [] | samarth-na | 5 |
pytest-dev/pytest-mock | pytest | 174 | xxx() missing 1 required positional argument: 'mocker' | I'm using pytest 5.3.0 with pytest-mock 1.12.1, and in a pytest class I want to temporarily mock a function of an object returned by some other module function. When I use `test_calls_operation(mocker)` outside a test class, then the `mocker` arg gets filled in by pytest-mock as expected. However, when I declare the t... | closed | 2019-12-07T15:10:47Z | 2023-04-15T09:41:56Z | https://github.com/pytest-dev/pytest-mock/issues/174 | [] | thediveo | 17 |
scikit-learn/scikit-learn | machine-learning | 30,714 | Version 1.0.2 requires numpy<2 | ### Describe the bug
Installing scikit-learn version 1.0.2 leads to the following error:
```bash
ValueError: numpy.dtype size changed, may indicate binary incompatibility. Expected 96 from C header, got 88 from PyObject
```
This seems to indicate a mismatch between this version of scikit-learn and numpy versions grea... | closed | 2025-01-24T11:47:50Z | 2025-01-24T15:00:00Z | https://github.com/scikit-learn/scikit-learn/issues/30714 | [
"Bug",
"Needs Triage"
] | grudloff | 7 |
tflearn/tflearn | data-science | 849 | Model.predict giving same predictions for every examples | I have a 110 layer resnet trained and validated with 4 classes to classify. Training examples are in decent proportion (30%,20%,25%,25%). It has validation accuracy of around 90%. When testing it for new examples it gives same class as output always. I am giving a list of arrays as input to model.predict. I have attach... | open | 2017-07-22T21:30:11Z | 2019-05-24T14:20:06Z | https://github.com/tflearn/tflearn/issues/849 | [] | deepakanandece | 2 |
gradio-app/gradio | data-visualization | 10,354 | KeyError in gradio_client stream_messages() pending_event_ids | ### Describe the bug
```
Traceback (most recent call last):
File "/usr/local/lib/python3.12/site-packages/gradio_client/client.py", line 277, in stream_messages
self.pending_event_ids.remove(event_id)
KeyError: 'a4306ceb969b452f8b4e2d6de58cd88f'
```
Hi, a `httpx.ReadTimeout` during `client.predict()` mig... | open | 2025-01-14T14:57:49Z | 2025-03-05T12:30:24Z | https://github.com/gradio-app/gradio/issues/10354 | [
"bug"
] | linzack | 1 |
onnx/onnx | pytorch | 6,533 | [reference] Improve ConcatFromSequence reference implementation | > I still have the same question. I agree there is an ambiguity in the ONNX documentation ... but the ambiguity applies to values other than -1 also. Eg., -2 as well.
>
> I think that the spec means that the specified axis is interpreted with respect to the output's shape (not the input's shape). So, the specified ... | open | 2024-11-05T23:17:22Z | 2024-11-05T23:18:34Z | https://github.com/onnx/onnx/issues/6533 | [
"module: reference implementation",
"contributions welcome"
] | justinchuby | 0 |
tflearn/tflearn | data-science | 782 | wide and deep help. | Run on default everything,
Training
---------------------------------
Run id: wide+deep
Log directory: /tmp/tflearn_logs/
INFO:tensorflow:Summary name BinaryAccuracy/wide_regression_0 (raw) is illegal; using BinaryAccuracy/wide_regression_0__raw_ instead.
INFO:tensorflow:Summary name BinaryAccuracy_1/deep_regr... | open | 2017-06-06T03:54:06Z | 2017-06-06T03:54:06Z | https://github.com/tflearn/tflearn/issues/782 | [] | lancerts | 0 |
scikit-image/scikit-image | computer-vision | 6,915 | Existing "inpainting" gallery example could use a better (more specific) title. | Creating this issue so we don't lose track of what's been discussed in the conversation _Originally posted by @lagru in https://github.com/scikit-image/scikit-image/pull/6853#discussion_r1149741067_
> @mkcor, just wondering how this relates to [our existing inpainting example ](https://scikit-image.org/docs/dev/auto... | closed | 2023-05-02T15:44:44Z | 2023-06-03T16:51:32Z | https://github.com/scikit-image/scikit-image/issues/6915 | [
":page_facing_up: type: Documentation"
] | mkcor | 0 |
PokeAPI/pokeapi | api | 315 | Pokemon Ultra Sun and Ultra Moon data needed | Pokemon Ultra sun and moon added some new pokemon and forms which seem to have yet to be added to the database, like the new forms of necrozma and dusk lycanroc. | closed | 2017-12-05T20:59:33Z | 2018-05-21T08:43:36Z | https://github.com/PokeAPI/pokeapi/issues/315 | [
"enhancement",
"veekun"
] | Smethan | 2 |
Gozargah/Marzban | api | 1,034 | ALPN bug in dev branch | Hello dear Gozargah team and Thank you very much for you help to bypass internet restrictions.
In latest version of dev branch, when we set ALPN to the combination of http/1.1 and h2, the panel return it as a string (i.e, "h2, http/1.1" ) into json config and does not split it as separate values for the ALPN array o... | closed | 2024-06-05T12:21:52Z | 2024-07-04T12:24:41Z | https://github.com/Gozargah/Marzban/issues/1034 | [
"Bug"
] | develfishere | 2 |
horovod/horovod | pytorch | 2,998 | Imported target "MPI::MPI_CXX" includes non-existent path | Hello,
I am having some issues installing horovod with MPI, would anybody be able to give any suggestions? I have attached my setup below.
Thanks,
Yiltan
**Environment:**
1. Framework: TensorFlow
2. Framework version: 1.15.2
3. Horovod version: v0.20.3
4. MPI version: MVAPICH2-GDR
5. CUDA version: 10.1.2... | closed | 2021-06-25T21:50:13Z | 2021-07-02T22:39:50Z | https://github.com/horovod/horovod/issues/2998 | [
"bug"
] | Yiltan | 2 |
pallets/quart | asyncio | 223 | Quart::send_from_directory produces ( semanticly ) incorrect response object in case of 304 response | **Bug**
When serving files from a directory using `send_from_directory`, Quart sometimes returns an `304 Not Modified` response.
However the content in this response is not empty as it should be as dictated by RFC 7230
> Any response to a HEAD request and any response with a 1xx
(Informational), 204 (No ... | closed | 2023-03-01T09:06:08Z | 2023-10-01T00:20:34Z | https://github.com/pallets/quart/issues/223 | [] | SamCoutteauHybrid | 1 |
coqui-ai/TTS | pytorch | 3,833 | [Bug] Error with torch.isin() in Docker Container with transformers Library | ### Describe the bug
When running the application inside a Docker container, an error occurs related to the torch.isin() method within the transformers library. The error does not occur when running the application locally (outside of the container), suggesting a possible incompatibility or issue with the dependencies... | closed | 2024-07-23T21:26:45Z | 2024-07-24T18:30:14Z | https://github.com/coqui-ai/TTS/issues/3833 | [
"bug"
] | Fledermaus-20 | 3 |
laughingman7743/PyAthena | sqlalchemy | 56 | SQLAlchemy doubles percent sign (%) | (But it can be fixed by setting self._double_percents = False in AthenaIdentifierPreparer `__init__`)
Broken:
```python
>>> import sqlalchemy
>>> engine = sqlalchemy.create_engine(.....)
>>> session = engine.connect()
>>> sql = "select date_parse('20191030', '%Y%m%d' )"
>>> txt = sqlalchemy.sql.text(sql)
>>... | closed | 2018-11-14T04:48:40Z | 2018-11-26T04:27:16Z | https://github.com/laughingman7743/PyAthena/issues/56 | [] | mister-average | 6 |
Kav-K/GPTDiscord | asyncio | 81 | Don't end the conversation if an api error occurs | Currently, when an api error occurs like overload, rate limit, or etc, the conversation will end, fix this, allow for the user to just be able to retry it | closed | 2023-01-10T08:22:55Z | 2023-01-11T23:07:12Z | https://github.com/Kav-K/GPTDiscord/issues/81 | [
"enhancement",
"high-prio"
] | Kav-K | 1 |
quantumlib/Cirq | api | 6,336 | Fix CI notebook tests for MacOS and Windows | **Description of the issue**
After activating MacOS and Windows testing in [ci-daily.yml](https://github.com/quantumlib/Cirq/blob/master/.github/workflows/ci-daily.yml) in #6331, the notebook tests failed on these platforms, [example](https://github.com/quantumlib/Cirq/actions/runs/6700241980).
As a temporary solut... | open | 2023-10-31T06:38:21Z | 2024-11-13T01:40:28Z | https://github.com/quantumlib/Cirq/issues/6336 | [
"good first issue",
"no QC knowledge needed",
"kind/health",
"triage/accepted"
] | pavoljuhas | 6 |
ultralytics/ultralytics | python | 19,316 | Inquiry Regarding Licensing for Commercial Use of YOLO with Custom Training Tool | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello,
I have developed a user-friendly tool (UI) that enables code-free tra... | open | 2025-02-19T16:45:49Z | 2025-02-24T07:08:11Z | https://github.com/ultralytics/ultralytics/issues/19316 | [
"question",
"enterprise"
] | DoBacc | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.