
url stringlengths 58 61 | repository_url stringclasses 1 value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 2.19B | node_id stringlengths 18 24 | number int64 2 6.73k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2 values | locked bool 1 class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at timestamp[s] | updated_at timestamp[s] | closed_at timestamp[s] | author_association stringclasses 3 values | active_lock_reason null | draft null | pull_request null | body stringlengths 0 228k ⌀ | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 3 values |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/3374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3374/comments | https://api.github.com/repos/huggingface/datasets/issues/3374/events | https://github.com/huggingface/datasets/issues/3374 | 1,070,426,462 | I_kwDODunzps4_zWle | 3,374 | NonMatchingChecksumError for the CLUE:cluewsc2020, chid, c3 and tnews | {
"login": "Namco0816",
"id": 34687537,
"node_id": "MDQ6VXNlcjM0Njg3NTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/34687537?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Namco0816",
"html_url": "https://github.com/Namco0816",
"followers_url": "https://api.github.com/users/Namco0816/followers",
"following_url": "https://api.github.com/users/Namco0816/following{/other_user}",
"gists_url": "https://api.github.com/users/Namco0816/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Namco0816/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Namco0816/subscriptions",
"organizations_url": "https://api.github.com/users/Namco0816/orgs",
"repos_url": "https://api.github.com/users/Namco0816/repos",
"events_url": "https://api.github.com/users/Namco0816/events{/privacy}",
"received_events_url": "https://api.github.com/users/Namco0816/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Seems like the issue still exists,:\r\n`Downloading and preparing dataset clue/chid (download: 127.15 MiB, generated: 259.71 MiB, post-processed: Unknown size, total: 386.86 MiB) to /mnt/cache/tanhaochen/.cache/huggingface/datasets/clue/chid/1.0.0/e55b490cb7809dcd8db31b9a87119f2e2ec87cdc060da8a9ac070b070ca3e379...... | 2021-12-03T10:10:54 | 2021-12-08T14:14:41 | 2021-12-08T14:14:41 | NONE | null | null | null | Hi, it seems like there are updates in cluewsc2020, chid, c3 and tnews, since i could not load them due to the checksum error. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3374/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3374/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3373 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3373/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3373/comments | https://api.github.com/repos/huggingface/datasets/issues/3373/events | https://github.com/huggingface/datasets/issues/3373 | 1,070,406,391 | I_kwDODunzps4_zRr3 | 3,373 | Support streaming zipped CSV dataset repo by passing only repo name | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-12-03T09:48:24 | 2021-12-16T18:03:31 | 2021-12-16T18:03:31 | MEMBER | null | null | null | Given a community 🤗 dataset repository containing only a zipped CSV file (only raw data, no loading script), I would like to load it in streaming mode without passing `data_files`:
```
ds_name = "bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab"
ds = load_dataset(ds_name, split="train", streaming=True, use_auth_token=True)
item = next(iter(ds))
```
Currently, it gives a `FileNotFoundError` because there is no glob (no "\*" after "zip://": "zip://*") in the passed URL:
```
'zip://::https://huggingface.co/datasets/bigscience-catalogue-data/vietnamese_poetry_from_fsoft_ai_lab/resolve/e5d45f1bd9a8a798cc14f0a45ebc1ce91907c792/poems_dataset.zip'
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3373/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3373/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3372 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3372/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3372/comments | https://api.github.com/repos/huggingface/datasets/issues/3372/events | https://github.com/huggingface/datasets/issues/3372 | 1,069,948,178 | I_kwDODunzps4_xh0S | 3,372 | [SEO improvement] Add Dataset Metadata to make datasets indexable | {
"login": "cakiki",
"id": 3664563,
"node_id": "MDQ6VXNlcjM2NjQ1NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3664563?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cakiki",
"html_url": "https://github.com/cakiki",
"followers_url": "https://api.github.com/users/cakiki/followers",
"following_url": "https://api.github.com/users/cakiki/following{/other_user}",
"gists_url": "https://api.github.com/users/cakiki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cakiki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cakiki/subscriptions",
"organizations_url": "https://api.github.com/users/cakiki/orgs",
"repos_url": "https://api.github.com/users/cakiki/repos",
"events_url": "https://api.github.com/users/cakiki/events{/privacy}",
"received_events_url": "https://api.github.com/users/cakiki/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [] | 2021-12-02T20:21:07 | 2022-03-18T09:36:48 | 2022-03-18T09:36:48 | CONTRIBUTOR | null | null | null | Some people who host datasets on github seem to include a table of metadata at the end of their README.md to make the dataset indexable by [Google Dataset Search](https://datasetsearch.research.google.com/) (See [here](https://github.com/google-research/google-research/tree/master/goemotions#dataset-metadata) and [here](https://github.com/cvdfoundation/google-landmark#dataset-metadata)). This could be a useful addition to canonical datasets; perhaps even community datasets.
I'll include a screenshot (as opposed to markdown) as an example so as not to have a github issue indexed as a dataset:
> 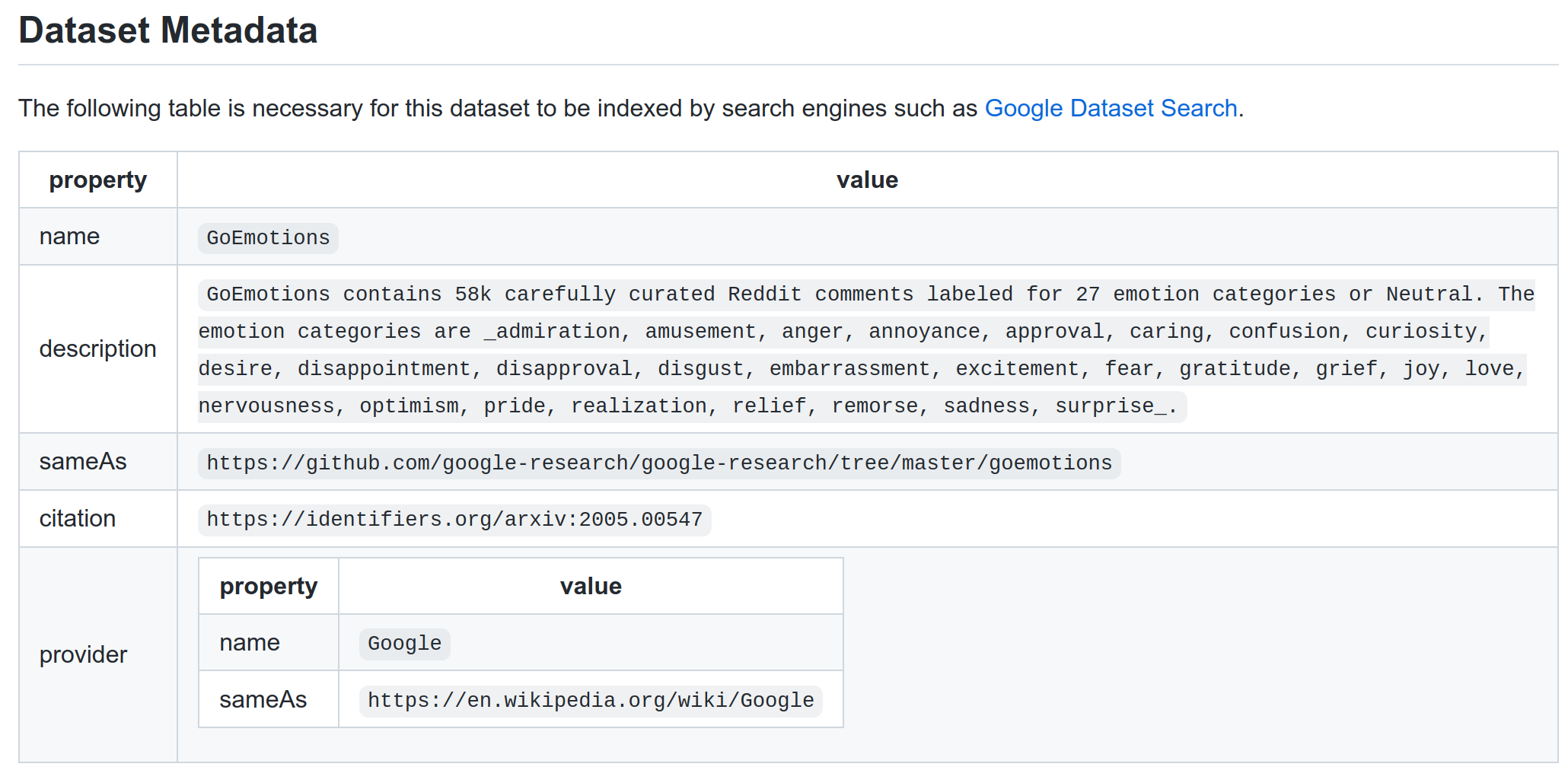
**_PS: It might very well be the case that this is already covered by some other markdown magic I'm not aware of._**
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3372/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3372/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3369 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3369/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3369/comments | https://api.github.com/repos/huggingface/datasets/issues/3369/events | https://github.com/huggingface/datasets/issues/3369 | 1,069,587,674 | I_kwDODunzps4_wJza | 3,369 | [Audio] Allow resampling for audio datasets in streaming mode | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"This requires implementing `cast_column` for iterable datasets, it could be a very nice addition !\r\n\r\n<s>It can also be useful to be able to disable the audio/image decoding for the dataset viewer (see PR https://github.com/huggingface/datasets/pull/3430) cc @severo </s>\r\nEDIT: actually following https://git... | 2021-12-02T14:04:57 | 2021-12-16T15:55:19 | 2021-12-16T15:55:19 | CONTRIBUTOR | null | null | null | Many audio datasets like Common Voice always need to be resampled. This can very easily be done in non-streaming mode as follows:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test")
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
However in streaming mode it fails currently:
```python
from datasets import load_dataset
ds = load_dataset("common_voice", "ab", split="test", streaming=True)
ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
```
with the following error:
```
AttributeError: 'IterableDataset' object has no attribute 'cast_column'
```
It would be great if we could add such a feature (I'm not 100% sure though how complex this would be) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3369/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3369/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3366 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3366/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3366/comments | https://api.github.com/repos/huggingface/datasets/issues/3366/events | https://github.com/huggingface/datasets/issues/3366 | 1,069,214,022 | I_kwDODunzps4_uulG | 3,366 | Add multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-12-02T07:24:04 | 2023-02-28T16:29:22 | null | MEMBER | null | null | null | Epic issue to track the addition of multimodal datasets:
- [ ] #2526
- [x] #1842
- [ ] #1810
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
@VictorSanh feel free to add and sort by priority any interesting dataset. I have added the multimodal dataset requests which were already present as issues. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3366/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/3366/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3365/comments | https://api.github.com/repos/huggingface/datasets/issues/3365/events | https://github.com/huggingface/datasets/issues/3365 | 1,069,195,887 | I_kwDODunzps4_uqJv | 3,365 | Add task tags for multimodal datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"The Hub pulls these tags from [here](https://github.com/huggingface/hub-docs/blob/main/js/src/lib/interfaces/Types.ts) (allows multimodal tasks) now, so I'm closing this issue."
] | 2021-12-02T06:58:20 | 2023-07-25T18:21:33 | 2023-07-25T18:21:32 | MEMBER | null | null | null | ## **Is your feature request related to a problem? Please describe.**
Currently, task tags are either exclusively related to text or speech processing:
- https://github.com/huggingface/datasets/blob/master/src/datasets/utils/resources/tasks.json
## **Describe the solution you'd like**
We should also add tasks related to:
- multimodality
- image
- video
CC: @VictorSanh @lewtun @lhoestq @merveenoyan @SBrandeis | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3365/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3365/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3361/comments | https://api.github.com/repos/huggingface/datasets/issues/3361/events | https://github.com/huggingface/datasets/issues/3361 | 1,068,736,268 | I_kwDODunzps4_s58M | 3,361 | Jeopardy _URL access denied | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Just a side note: duplicate #3264"
] | 2021-12-01T18:21:33 | 2021-12-11T12:50:23 | 2021-12-06T11:16:31 | CONTRIBUTOR | null | null | null | ## Describe the bug
http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz returns Access Denied now.
However, https://drive.google.com/file/d/0BwT5wj_P7BKXb2hfM3d2RHU1ckE/view?usp=sharing from the original Reddit post https://www.reddit.com/r/datasets/comments/1uyd0t/200000_jeopardy_questions_in_a_json_file/ may work.
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
```
```python
>>> from datasets import load_dataset
>>> load_dataset("jeopardy")
```
## Expected results
The download completes.
## Actual results
```shell
Downloading: 4.18kB [00:00, 1.60MB/s]
Downloading: 2.03kB [00:00, 1.04MB/s]
Using custom data configuration default
Downloading and preparing dataset jeopardy/default (download: 12.13 MiB, generated: 34.46 MiB, post-processed: Unknown size, total: 46.59 MiB) to /Users/mike/.cache/huggingface/datasets/jeopardy/default/0.1.0/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/mike/.cache/huggingface/modules/datasets_modules/datasets/jeopardy/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810/jeopardy.py", line 72, in _split_generators
filepath = dl_manager.download_and_extract(_DATA_URL)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 197, in download
download_func, url_or_urls, map_tuple=True, num_proc=download_config.num_proc, disable_tqdm=False
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 197, in map_nested
return function(data_struct)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 305, in cached_path
use_auth_token=download_config.use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
---
```shell
> curl http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
```xml
<?xml version="1.0" encoding="UTF-8"?>
<Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>70Y9R36XNPEQXMGV</RequestId><HostId>G6F5AK4qo7JdaEdKGMtS0P6gdLPeFOdEfSEfvTOZEfk9km0/jAfp08QLfKSTFFj1oWIKoAoBehM=</HostId></Error>
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.0
- Platform: macOS Catalina 10.15.7
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3361/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3361/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3358 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3358/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3358/comments | https://api.github.com/repos/huggingface/datasets/issues/3358/events | https://github.com/huggingface/datasets/issues/3358 | 1,068,623,216 | I_kwDODunzps4_seVw | 3,358 | add new field, and get errors | {
"login": "PatricYan",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PatricYan",
"html_url": "https://github.com/PatricYan",
"followers_url": "https://api.github.com/users/PatricYan/followers",
"following_url": "https://api.github.com/users/PatricYan/following{/other_user}",
"gists_url": "https://api.github.com/users/PatricYan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PatricYan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PatricYan/subscriptions",
"organizations_url": "https://api.github.com/users/PatricYan/orgs",
"repos_url": "https://api.github.com/users/PatricYan/repos",
"events_url": "https://api.github.com/users/PatricYan/events{/privacy}",
"received_events_url": "https://api.github.com/users/PatricYan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi, \r\n\r\ncould you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests? ",
"> Hi,\r\n> \r\n> could you please post this question on our [Forum](https://discuss.huggingface.co/) as we keep issues for bugs and feature requests?\r\n\r\nok."
] | 2021-12-01T16:35:38 | 2021-12-02T02:26:22 | 2021-12-02T02:26:22 | NONE | null | null | null | after adding new field **tokenized_examples["example_id"]**, and get errors below,
I think it is due to changing data to tensor, and **tokenized_examples["example_id"]** is string list
**all fields**
```
***************** train_dataset 1: Dataset({
features: ['attention_mask', 'end_positions', 'example_id', 'input_ids', 'start_positions', 'token_type_ids'],
num_rows: 87714
})
```
**Errors**
```
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/transformers/tokenization_utils_base.py", line 705, in convert_to_tensors
tensor = as_tensor(value)
ValueError: too many dimensions 'str'
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3358/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3358/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3353/comments | https://api.github.com/repos/huggingface/datasets/issues/3353/events | https://github.com/huggingface/datasets/issues/3353 | 1,068,173,783 | I_kwDODunzps4_qwnX | 3,353 | add one field "example_id", but I can't see it in the "comput_loss" function | {
"login": "PatricYan",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PatricYan",
"html_url": "https://github.com/PatricYan",
"followers_url": "https://api.github.com/users/PatricYan/followers",
"following_url": "https://api.github.com/users/PatricYan/following{/other_user}",
"gists_url": "https://api.github.com/users/PatricYan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PatricYan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PatricYan/subscriptions",
"organizations_url": "https://api.github.com/users/PatricYan/orgs",
"repos_url": "https://api.github.com/users/PatricYan/repos",
"events_url": "https://api.github.com/users/PatricYan/events{/privacy}",
"received_events_url": "https://api.github.com/users/PatricYan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! Your function looks fine, I used to map `squad` locally and it indeed added the `example_id` field correctly.\r\n\r\nHowever I think that in the `compute_loss` method only a subset of the fields are available: the model inputs. Since `example_id` is not a model input (it's not passed as a parameter to the mod... | 2021-12-01T09:35:09 | 2021-12-01T16:02:39 | 2021-12-01T16:02:39 | NONE | null | null | null | Hi, I add one field **example_id**, but I can't see it in the **comput_loss** function, how can I do this? below is the information of inputs
```
*********************** inputs: {'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
...,
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0],
[1, 1, 1, ..., 0, 0, 0]], device='cuda:0'), 'end_positions': tensor([ 25, 97, 93, 44, 25, 112, 109, 134], device='cuda:0'), 'input_ids': tensor([[ 101, 2054, 2390, ..., 0, 0, 0],
[ 101, 2054, 2515, ..., 0, 0, 0],
[ 101, 2054, 2106, ..., 0, 0, 0],
...,
[ 101, 2339, 2001, ..., 0, 0, 0],
[ 101, 2054, 2515, ..., 0, 0, 0],
[ 101, 2054, 2003, ..., 0, 0, 0]], device='cuda:0'), 'start_positions': tensor([ 20, 90, 89, 41, 25, 96, 106, 132], device='cuda:0'), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], device='cuda:0')}
```
```
# This function preprocesses a question answering dataset, tokenizing the question and context text
# and finding the right offsets for the answer spans in the tokenized context (to use as labels).
# Adapted from https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_qa.py
def prepare_train_dataset_qa(examples, tokenizer, max_seq_length=None):
questions = [q.lstrip() for q in examples["question"]]
max_seq_length = tokenizer.model_max_length
# tokenize both questions and the corresponding context
# if the context length is longer than max_length, we split it to several
# chunks of max_length
tokenized_examples = tokenizer(
questions,
examples["context"],
truncation="only_second",
max_length=max_seq_length,
stride=min(max_seq_length // 2, 128),
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length"
)
# Since one example might give us several features if it has a long context,
# we need a map from a feature to its corresponding example.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# The offset mappings will give us a map from token to character position
# in the original context. This will help us compute the start_positions
# and end_positions to get the final answer string.
offset_mapping = tokenized_examples.pop("offset_mapping")
tokenized_examples["start_positions"] = []
tokenized_examples["end_positions"] = []
tokenized_examples["example_id"] = []
for i, offsets in enumerate(offset_mapping):
input_ids = tokenized_examples["input_ids"][i]
# We will label features not containing the answer the index of the CLS token.
cls_index = input_ids.index(tokenizer.cls_token_id)
sequence_ids = tokenized_examples.sequence_ids(i)
# from the feature idx to sample idx
sample_index = sample_mapping[i]
# get the answer for a feature
answers = examples["answers"][sample_index]
tokenized_examples["example_id"].append(examples["id"][sample_index])
if len(answers["answer_start"]) == 0:
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Start/end character index of the answer in the text.
start_char = answers["answer_start"][0]
end_char = start_char + len(answers["text"][0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and
offsets[token_end_index][1] >= end_char):
tokenized_examples["start_positions"].append(cls_index)
tokenized_examples["end_positions"].append(cls_index)
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and \
offsets[token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples["start_positions"].append(
token_start_index - 1)
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples["end_positions"].append(token_end_index + 1)
return tokenized_examples
```
_Originally posted by @yanllearnn in https://github.com/huggingface/datasets/issues/3333#issuecomment-983457161_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3353/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3353/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3346/comments | https://api.github.com/repos/huggingface/datasets/issues/3346/events | https://github.com/huggingface/datasets/issues/3346 | 1,067,632,365 | I_kwDODunzps4_osbt | 3,346 | Failed to convert `string` with pyarrow for QED since 1.15.0 | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Scratch that, probably the old and incompatible usage of dataset builder from promptsource.",
"Actually, re-opening this issue cause the error persists\r\n\r\n```python\r\n>>> load_dataset(\"qed\")\r\nDownloading and preparing dataset qed/qed (download: 13.43 MiB, generated: 9.70 MiB, post-processed: Unknown siz... | 2021-11-30T20:11:42 | 2021-12-14T14:39:05 | 2021-12-14T14:39:05 | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading QED was fine until 1.15.0.
related: bigscience-workshop/promptsource#659, bigscience-workshop/promptsource#670
Not sure where the root cause is, but here are some candidates:
- #3158
- #3120
- #3196
- #2891
## Steps to reproduce the bug
```python
load_dataset("qed")
```
## Expected results
Loading completed.
## Actual results
```shell
ArrowInvalid: Could not convert in with type str: tried to convert to boolean
Traceback:
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/script_runner.py", line 354, in _run_script
exec(code, module.__dict__)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/app.py", line 260, in <module>
dataset = get_dataset(dataset_key, str(conf_option.name) if conf_option else None)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 543, in wrapped_func
return get_or_create_cached_value()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/streamlit/caching.py", line 527, in get_or_create_cached_value
return_value = func(*args, **kwargs)
File "/Users/s0s0cr3/Documents/GitHub/promptsource/promptsource/utils.py", line 49, in get_dataset
builder_instance.download_and_prepare()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/builder.py", line 1106, in _prepare_split
num_examples, num_bytes = writer.finalize()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 456, in finalize
self.write_examples_on_file()
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 325, in write_examples_on_file
pa_array = pa.array(typed_sequence)
File "pyarrow/array.pxi", line 222, in pyarrow.lib.array
File "pyarrow/array.pxi", line 110, in pyarrow.lib._handle_arrow_array_protocol
File "/Users/s0s0cr3/Library/Python/3.9/lib/python/site-packages/datasets/arrow_writer.py", line 121, in __arrow_array__
out = pa.array(cast_to_python_objects(self.data, only_1d_for_numpy=True), type=type)
File "pyarrow/array.pxi", line 305, in pyarrow.lib.array
File "pyarrow/array.pxi", line 39, in pyarrow.lib._sequence_to_array
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.0, 1.16.1
- Platform: macOS 1.15.7 or above
- Python version: 3.7.12 and 3.9
- PyArrow version: 3.0.0, 5.0.0, 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3346/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3346/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3345/comments | https://api.github.com/repos/huggingface/datasets/issues/3345/events | https://github.com/huggingface/datasets/issues/3345 | 1,067,622,951 | I_kwDODunzps4_oqIn | 3,345 | Failed to download species_800 from Google Drive zip file | {
"login": "tianjianjiang",
"id": 4812544,
"node_id": "MDQ6VXNlcjQ4MTI1NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/4812544?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tianjianjiang",
"html_url": "https://github.com/tianjianjiang",
"followers_url": "https://api.github.com/users/tianjianjiang/followers",
"following_url": "https://api.github.com/users/tianjianjiang/following{/other_user}",
"gists_url": "https://api.github.com/users/tianjianjiang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tianjianjiang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tianjianjiang/subscriptions",
"organizations_url": "https://api.github.com/users/tianjianjiang/orgs",
"repos_url": "https://api.github.com/users/tianjianjiang/repos",
"events_url": "https://api.github.com/users/tianjianjiang/events{/privacy}",
"received_events_url": "https://api.github.com/users/tianjianjiang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthe dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?",
"> Hi,\r\n> \r\n> the dataset is downloaded normally on my machine. Maybe the URL was down at the time of your download. Could you try again?\r\n\r\nI have tried that many time... | 2021-11-30T20:00:28 | 2021-12-01T17:53:15 | 2021-12-01T17:53:15 | CONTRIBUTOR | null | null | null | ## Describe the bug
One can manually download the zip file on Google Drive, but `load_dataset()` cannot.
related: #3248
## Steps to reproduce the bug
```shell
> python
Python 3.7.12 (default, Sep 5 2021, 08:34:29)
[Clang 11.0.3 (clang-1103.0.32.62)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
```
```python
>>> from datasets import load_dataset
>>> s800 = load_dataset("species_800")
```
## Expected results
species_800 downloaded.
## Actual results
```shell
Downloading: 5.68kB [00:00, 1.22MB/s]
Downloading: 2.70kB [00:00, 691kB/s]
Downloading and preparing dataset species800/species_800 (download: 17.36 MiB, generated: 3.53 MiB, post-processed: Unknown size, total: 20.89 MiB) to /Users/mike/.cache/huggingface/datasets/species800/species_800/1.0.0/532167f0bb8fbc0d77d6d03c4fd642c8c55527b9c5f2b1da77f3d00b0e559976...
0%| | 0/1 [00:00<?, ?it/s]Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/load.py", line 1632, in load_dataset
use_auth_token=use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 608, in download_and_prepare
dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/mike/.cache/huggingface/modules/datasets_modules/datasets/species_800/532167f0bb8fbc0d77d6d03c4fd642c8c55527b9c5f2b1da77f3d00b0e559976/species_800.py", line 104, in _split_generators
downloaded_files = dl_manager.download_and_extract(urls_to_download)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 197, in download
download_func, url_or_urls, map_tuple=True, num_proc=download_config.num_proc, disable_tqdm=False
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 209, in map_nested
for obj in utils.tqdm(iterable, disable=disable_tqdm)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 209, in <listcomp>
for obj in utils.tqdm(iterable, disable=disable_tqdm)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/py_utils.py", line 143, in _single_map_nested
return function(data_struct)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 305, in cached_path
use_auth_token=download_config.use_auth_token,
File "/Users/mike/Library/Caches/pypoetry/virtualenvs/promptsource-hsdAcWsQ-py3.7/lib/python3.7/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://drive.google.com/u/0/uc?id=1OletxmPYNkz2ltOr9pyT0b0iBtUWxslh&export=download/
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14,0 1.15.0, 1.16.1
- Platform: macOS Catalina 10.15.7
- Python version: 3.7.12
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3345/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3345/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3341 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3341/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3341/comments | https://api.github.com/repos/huggingface/datasets/issues/3341/events | https://github.com/huggingface/datasets/issues/3341 | 1,067,449,569 | I_kwDODunzps4_n_zh | 3,341 | Mirror the canonical datasets to the Hugging Face Hub | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"I created a GitHub project to keep track of what needs to be done:\r\nhttps://github.com/huggingface/datasets/projects/3\r\n\r\nI also store my code in a (private for now) repository at https://github.com/huggingface/mirror_canonical_datasets_on_hub",
"I understand that the datasets are mirrored on the Hub now, ... | 2021-11-30T16:42:05 | 2022-01-26T14:47:37 | 2022-01-26T14:47:37 | CONTRIBUTOR | null | null | null | - [ ] create a repo on https://hf.co/datasets for every canonical dataset
- [ ] on every commit related to a dataset, update the hf.co repo
See https://github.com/huggingface/moon-landing/pull/1562
@SBrandeis: I let you edit this description if needed to precise the intent. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3341/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3341/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3339 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3339/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3339/comments | https://api.github.com/repos/huggingface/datasets/issues/3339/events | https://github.com/huggingface/datasets/issues/3339 | 1,066,662,477 | I_kwDODunzps4_k_pN | 3,339 | to_tf_dataset fails on TPU | {
"login": "nbroad1881",
"id": 24982805,
"node_id": "MDQ6VXNlcjI0OTgyODA1",
"avatar_url": "https://avatars.githubusercontent.com/u/24982805?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nbroad1881",
"html_url": "https://github.com/nbroad1881",
"followers_url": "https://api.github.com/users/nbroad1881/followers",
"following_url": "https://api.github.com/users/nbroad1881/following{/other_user}",
"gists_url": "https://api.github.com/users/nbroad1881/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nbroad1881/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nbroad1881/subscriptions",
"organizations_url": "https://api.github.com/users/nbroad1881/orgs",
"repos_url": "https://api.github.com/users/nbroad1881/repos",
"events_url": "https://api.github.com/users/nbroad1881/events{/privacy}",
"received_events_url": "https://api.github.com/users/nbroad1881/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"This might be related to https://github.com/tensorflow/tensorflow/issues/38762 , what do you think @Rocketknight1 ?\r\n> Dataset.from_generator is expected to not work with TPUs as it uses py_function underneath which is incompatible with Cloud TPU 2VM setup. If you would like to read from large datasets, maybe tr... | 2021-11-30T00:50:52 | 2021-12-02T14:21:27 | null | NONE | null | null | null | Using `to_tf_dataset` to create a dataset and then putting it in `model.fit` results in an internal error on TPUs. I've only tried on Colab and Kaggle TPUs, not GCP TPUs.
## Steps to reproduce the bug
I made a colab to show the error. https://colab.research.google.com/drive/12x_PFKzGouFxqD4OuWfnycW_1TaT276z?usp=sharing
## Expected results
dataset from `to_tf_dataset` works in `model.fit`
Right below the first error in the colab I use `tf.data.Dataset.from_tensor_slices` and `model.fit` works just fine. This is the desired outcome.
## Actual results
```
InternalError: 5 root error(s) found.
(0) INTERNAL: {{function_node __inference_train_function_30558}} failed to connect to all addresses
Additional GRPC error information from remote target /job:localhost/replica:0/task:0/device:CPU:0:
:{"created":"@1638231897.932218653","description":"Failed to pick subchannel","file":"third_party/grpc/src/core/ext/filters/client_channel/client_channel.cc","file_line":3151,"referenced_errors":[{"created":"@1638231897.932216754","description":"failed to connect to all addresses","file":"third_party/grpc/src/core/lib/transport/error_utils.cc","file_line":161,"grpc_status":14}]}
[[{{node StatefulPartitionedCall}}]]
[[MultiDeviceIteratorGetNextFromShard]]
Executing non-communication op <MultiDeviceIteratorGetNextFromShard> originally returned UnavailableError, and was replaced by InternalError to avoid invoking TF network error handling logic.
[[RemoteCall]]
[[IteratorGetNextAsOptional]]
[[tpu_compile_succeeded_assert/_14023832043698465348/_7/_439]]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.16.1
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.12
- PyArrow version: 3.0.0
- Tensorflow 2.7.0
- `transformers` 4.12.5
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3339/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3339/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3337/comments | https://api.github.com/repos/huggingface/datasets/issues/3337/events | https://github.com/huggingface/datasets/issues/3337 | 1,066,232,936 | I_kwDODunzps4_jWxo | 3,337 | Typing of Dataset.__getitem__ could be improved. | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"repos_url": "https://api.github.com/users/Dref360/repos",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.github.com/users/Dref360/followers",
"following_url": "https://api.github.com/users/Dref360/following{/other_user}",
"gists_url": "https://api.github.com/users/Dref360/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Dref360/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Dref360/subscriptions",
"organizations_url": "https://api.github.com/users/Dref360/orgs",
"repos_url": "https://api.github.com/users/Dref360/repos",
"events_url": "https://api.github.com/users/Dref360/events{/privacy}",
"received_events_url": "https://api.github.com/users/Dref360/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Dref360",
"id": 8976546,
"node_id": "MDQ6VXNlcjg5NzY1NDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8976546?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Dref360",
"html_url": "https://github.com/Dref360",
"followers_url": "https://api.githu... | null | [
"Hi ! Thanks for the suggestion, I didn't know about this decorator.\r\n\r\nIf you are interesting in contributing, feel free to open a pull request to add the overload methods for each typing combination :) To assign you to this issue, you can comment `#self-assign` in this thread.\r\n\r\n`Dataset.__getitem__` is ... | 2021-11-29T16:20:11 | 2021-12-14T10:28:54 | 2021-12-14T10:28:54 | CONTRIBUTOR | null | null | null | ## Describe the bug
The newly added typing for Dataset.__getitem__ is Union[Dict, List]. This makes tools like mypy a bit awkward to use as we need to check the type manually. We could use type overloading to make this easier. [Documentation](https://docs.python.org/3/library/typing.html#typing.overload)
## Steps to reproduce the bug
Let's have a file `test.py`
```python
from typing import List, Dict, Any
from datasets import Dataset
ds = Dataset.from_dict({
'a': [1,2,3],
'b': ["1", "2", "3"]
})
one_colum: List[str] = ds['a']
some_index: Dict[Any, Any] = ds[1]
```
## Expected results
Running `mypy test.py` should not give any error.
## Actual results
```
test.py:10: error: Incompatible types in assignment (expression has type "Union[Dict[Any, Any], List[Any]]", variable has type "List[str]")
test.py:11: error: Incompatible types in assignment (expression has type "Union[Dict[Any, Any], List[Any]]", variable has type "Dict[Any, Any]")
Found 2 errors in 1 file (checked 1 source file)
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.13.3
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.8
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3337/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3337/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3334 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3334/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3334/comments | https://api.github.com/repos/huggingface/datasets/issues/3334/events | https://github.com/huggingface/datasets/issues/3334 | 1,065,983,923 | I_kwDODunzps4_iZ-z | 3,334 | Integrate Polars library | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"If possible, a neat API could be something like `Dataset.to_polars()`, as well as `Dataset.set_format(\"polars\")`",
"Note they use a \"custom\" implementation of Arrow: [Arrow2](https://github.com/jorgecarleitao/arrow2).",
"Polars has grown rapidly in popularity over the last year - could you consider integra... | 2021-11-29T12:31:54 | 2024-03-16T01:35:00 | null | MEMBER | null | null | null | Check potential integration of the Polars library: https://github.com/pola-rs/polars
- Benchmark: https://h2oai.github.io/db-benchmark/
CC: @thomwolf @lewtun
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3334/reactions",
"total_count": 13,
"+1": 6,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 7,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3334/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3333 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3333/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3333/comments | https://api.github.com/repos/huggingface/datasets/issues/3333/events | https://github.com/huggingface/datasets/issues/3333 | 1,065,346,919 | I_kwDODunzps4_f-dn | 3,333 | load JSON files, get the errors | {
"login": "PatricYan",
"id": 38966558,
"node_id": "MDQ6VXNlcjM4OTY2NTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/38966558?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PatricYan",
"html_url": "https://github.com/PatricYan",
"followers_url": "https://api.github.com/users/PatricYan/followers",
"following_url": "https://api.github.com/users/PatricYan/following{/other_user}",
"gists_url": "https://api.github.com/users/PatricYan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PatricYan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PatricYan/subscriptions",
"organizations_url": "https://api.github.com/users/PatricYan/orgs",
"repos_url": "https://api.github.com/users/PatricYan/repos",
"events_url": "https://api.github.com/users/PatricYan/events{/privacy}",
"received_events_url": "https://api.github.com/users/PatricYan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Hi ! The message you're getting is not an error. It simply says that your JSON dataset is being prepared to a location in `/root/.cache/huggingface/datasets`",
"> \r\n\r\nbut I want to load local JSON file by command\r\n`python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_di... | 2021-11-28T14:29:58 | 2021-12-01T09:34:31 | 2021-12-01T03:57:48 | NONE | null | null | null | Hi, does this bug be fixed? when I load JSON files, I get the same errors by the command
`!python3 run.py --do_train --task qa --dataset squad-retrain-data/train-v2.0.json --output_dir ./re_trained_model/`
change the dateset to load json by refering to https://huggingface.co/docs/datasets/loading.html
`dataset = datasets.load_dataset('json', data_files=args.dataset)`
Errors:
`Downloading and preparing dataset json/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/json/default-c1e124ad488911b8/0.0.0/45636811569ec4a6630521c18235dfbbab83b7ab572e3393c5ba68ccabe98264...
`
_Originally posted by @yanllearnn in https://github.com/huggingface/datasets/issues/730#issuecomment-981095050_ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3333/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3333/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3331 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3331/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3331/comments | https://api.github.com/repos/huggingface/datasets/issues/3331/events | https://github.com/huggingface/datasets/issues/3331 | 1,065,275,896 | I_kwDODunzps4_ftH4 | 3,331 | AttributeError: 'CommunityDatasetModuleFactoryWithoutScript' object has no attribute 'path' | {
"login": "luozhouyang",
"id": 34032031,
"node_id": "MDQ6VXNlcjM0MDMyMDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/34032031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/luozhouyang",
"html_url": "https://github.com/luozhouyang",
"followers_url": "https://api.github.com/users/luozhouyang/followers",
"following_url": "https://api.github.com/users/luozhouyang/following{/other_user}",
"gists_url": "https://api.github.com/users/luozhouyang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/luozhouyang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/luozhouyang/subscriptions",
"organizations_url": "https://api.github.com/users/luozhouyang/orgs",
"repos_url": "https://api.github.com/users/luozhouyang/repos",
"events_url": "https://api.github.com/users/luozhouyang/events{/privacy}",
"received_events_url": "https://api.github.com/users/luozhouyang/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthe fix was merged and will be available in the next release of `datasets`.\r\nIn the meantime, you can use it by installing `datasets` directly from master as follows:\r\n```\r\npip install git+https://github.com/huggingface/datasets.git\r\n```"
] | 2021-11-28T08:54:05 | 2021-11-29T13:49:44 | 2021-11-29T13:34:14 | NONE | null | null | null | ## Describe the bug
I add a new question answering dataset to huggingface datasets manually. Here is the link: [luozhouyang/question-answering-datasets](https://huggingface.co/datasets/luozhouyang/question-answering-datasets)
But when I load the dataset, an error raised:
```bash
AttributeError: 'CommunityDatasetModuleFactoryWithoutScript' object has no attribute 'path'
```
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("luozhouyang/question-answering-datasets", data_files=["dureader_robust.train.json"])
```
## Expected results
Load dataset successfully without any error.
## Actual results
```bash
Traceback (most recent call last):
File "/mnt/home/zhouyang.lzy/github/naivenlp/naivenlp/tests/question_answering_tests/dataset_test.py", line 89, in test_load_dataset_with_hf
data_files=["dureader_robust.train.json"],
File "/mnt/home/zhouyang.lzy/.conda/envs/naivenlp/lib/python3.6/site-packages/datasets/load.py", line 1616, in load_dataset
**config_kwargs,
File "/mnt/home/zhouyang.lzy/.conda/envs/naivenlp/lib/python3.6/site-packages/datasets/load.py", line 1443, in load_dataset_builder
path, revision=revision, download_config=download_config, download_mode=download_mode, data_files=data_files
File "/mnt/home/zhouyang.lzy/.conda/envs/naivenlp/lib/python3.6/site-packages/datasets/load.py", line 1157, in dataset_module_factory
raise e1 from None
File "/mnt/home/zhouyang.lzy/.conda/envs/naivenlp/lib/python3.6/site-packages/datasets/load.py", line 1144, in dataset_module_factory
download_mode=download_mode,
File "/mnt/home/zhouyang.lzy/.conda/envs/naivenlp/lib/python3.6/site-packages/datasets/load.py", line 798, in get_module
raise FileNotFoundError(f"No data files or dataset script found in {self.path}")
AttributeError: 'CommunityDatasetModuleFactoryWithoutScript' object has no attribute 'path'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: linux
- Python version: 3.6.13
- PyArrow version: 6.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3331/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3331/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3329 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3329/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3329/comments | https://api.github.com/repos/huggingface/datasets/issues/3329/events | https://github.com/huggingface/datasets/issues/3329 | 1,065,096,971 | I_kwDODunzps4_fBcL | 3,329 | Map function: Type error on iter #999 | {
"login": "josephkready666",
"id": 52659318,
"node_id": "MDQ6VXNlcjUyNjU5MzE4",
"avatar_url": "https://avatars.githubusercontent.com/u/52659318?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/josephkready666",
"html_url": "https://github.com/josephkready666",
"followers_url": "https://api.github.com/users/josephkready666/followers",
"following_url": "https://api.github.com/users/josephkready666/following{/other_user}",
"gists_url": "https://api.github.com/users/josephkready666/gists{/gist_id}",
"starred_url": "https://api.github.com/users/josephkready666/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/josephkready666/subscriptions",
"organizations_url": "https://api.github.com/users/josephkready666/orgs",
"repos_url": "https://api.github.com/users/josephkready666/repos",
"events_url": "https://api.github.com/users/josephkready666/events{/privacy}",
"received_events_url": "https://api.github.com/users/josephkready666/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi, thanks for reporting.\r\n\r\nIt would be really helpful if you could provide the actual code of the `text_numbers_to_int` function so we can reproduce the error.",
"```\r\ndef text_numbers_to_int(text, column=\"\"):\r\n \"\"\"\r\n Convert text numbers to int.\r\n\r\n :param text: text numbers\r\n ... | 2021-11-27T17:53:05 | 2021-11-29T20:40:15 | 2021-11-29T20:40:15 | NONE | null | null | null | ## Describe the bug
Using the map function, it throws a type error on iter #999
Here is the code I am calling:
```
dataset = datasets.load_dataset('squad')
dataset['validation'].map(text_numbers_to_int, input_columns=['context'], fn_kwargs={'column': 'context'})
```
text_numbers_to_int returns the input text with numbers replaced in the format {'context': text}
It happens at
`
File "C:\Users\lonek\anaconda3\envs\ai\Lib\site-packages\datasets\arrow_writer.py", line 289, in <listcomp>
[row[0][col] for row in self.current_examples], type=col_type, try_type=col_try_type, col=col
`
The issue is that the list comprehension expects self.current_examples to be type tuple(dict, str), but for some reason 26 out of 1000 of the sefl.current_examples are type tuple(str, str)
Here is an example of what self.current_examples should be
({'context': 'Super Bowl 50 was an...merals 50.'}, '')
Here is an example of what self.current_examples are when it throws the error:
('The Panthers used th... Marriott.', '')
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3329/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3329/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3327 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3327/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3327/comments | https://api.github.com/repos/huggingface/datasets/issues/3327/events | https://github.com/huggingface/datasets/issues/3327 | 1,064,675,888 | I_kwDODunzps4_daow | 3,327 | "Shape of query is incorrect, it has to be either a 1D array or 2D (1, N)" | {
"login": "eliasws",
"id": 19492473,
"node_id": "MDQ6VXNlcjE5NDkyNDcz",
"avatar_url": "https://avatars.githubusercontent.com/u/19492473?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eliasws",
"html_url": "https://github.com/eliasws",
"followers_url": "https://api.github.com/users/eliasws/followers",
"following_url": "https://api.github.com/users/eliasws/following{/other_user}",
"gists_url": "https://api.github.com/users/eliasws/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eliasws/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eliasws/subscriptions",
"organizations_url": "https://api.github.com/users/eliasws/orgs",
"repos_url": "https://api.github.com/users/eliasws/repos",
"events_url": "https://api.github.com/users/eliasws/events{/privacy}",
"received_events_url": "https://api.github.com/users/eliasws/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"#3323 "
] | 2021-11-26T16:26:36 | 2021-11-26T16:44:11 | 2021-11-26T16:44:11 | CONTRIBUTOR | null | null | null | ## Describe the bug
Passing a correctly shaped Numpy-Array to get_nearest_examples leads to the Exception
"Shape of query is incorrect, it has to be either a 1D array or 2D (1, N)"
Probably the reason for this is a wrongly converted assertion.
1.15.1:
`assert len(query.shape) == 1 or (len(query.shape) == 2 and query.shape[0] == 1)`
1.16.1:
```
if len(query.shape) != 1 or (len(query.shape) == 2 and query.shape[0] != 1):
raise ValueError("Shape of query is incorrect, it has to be either a 1D array or 2D (1, N)")
```
## Steps to reproduce the bug
follow the steps described here: https://huggingface.co/course/chapter5/6?fw=tf
```python
question_embedding.shape # (1, 768)
scores, samples = embeddings_dataset.get_nearest_examples(
"embeddings", question_embedding, k=5 # Error
)
# "Shape of query is incorrect, it has to be either a 1D array or 2D (1, N)"
```
## Expected results
Should work without exception
## Actual results
Throws exception
## Environment info
- `datasets` version: 1.15.1
- Platform: Darwin-20.6.0-x86_64-i386-64bit
- Python version: 3.7.12
- PyArrow version: 6.0.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3327/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3327/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3324 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3324/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3324/comments | https://api.github.com/repos/huggingface/datasets/issues/3324/events | https://github.com/huggingface/datasets/issues/3324 | 1,064,661,212 | I_kwDODunzps4_dXDc | 3,324 | Can't import `datasets` in python 3.10 | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [] | 2021-11-26T16:06:14 | 2021-11-26T16:31:23 | 2021-11-26T16:31:23 | MEMBER | null | null | null | When importing `datasets` I'm getting this error in python 3.10:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/__init__.py", line 34, in <module>
from .arrow_dataset import Dataset, concatenate_datasets
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_dataset.py", line 47, in <module>
from .arrow_reader import ArrowReader
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/arrow_reader.py", line 33, in <module>
from .table import InMemoryTable, MemoryMappedTable, Table, concat_tables
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 334, in <module>
class InMemoryTable(TableBlock):
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 361, in InMemoryTable
def from_pandas(cls, *args, **kwargs):
File "/Users/quentinlhoest/Desktop/hf/nlp/src/datasets/table.py", line 24, in wrapper
out = wraps(arrow_table_method)(method)
File "/Users/quentinlhoest/.pyenv/versions/3.10.0/lib/python3.10/functools.py", line 61, in update_wrapper
wrapper.__wrapped__ = wrapped
AttributeError: readonly attribute
```
This makes the conda build fail.
I'm opening a PR to fix this and do a patch release 1.16.1 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3324/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3324/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3320 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3320/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3320/comments | https://api.github.com/repos/huggingface/datasets/issues/3320/events | https://github.com/huggingface/datasets/issues/3320 | 1,063,531,992 | I_kwDODunzps4_ZDXY | 3,320 | Can't get tatoeba.rus dataset | {
"login": "mmg10",
"id": 65535131,
"node_id": "MDQ6VXNlcjY1NTM1MTMx",
"avatar_url": "https://avatars.githubusercontent.com/u/65535131?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mmg10",
"html_url": "https://github.com/mmg10",
"followers_url": "https://api.github.com/users/mmg10/followers",
"following_url": "https://api.github.com/users/mmg10/following{/other_user}",
"gists_url": "https://api.github.com/users/mmg10/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mmg10/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mmg10/subscriptions",
"organizations_url": "https://api.github.com/users/mmg10/orgs",
"repos_url": "https://api.github.com/users/mmg10/repos",
"events_url": "https://api.github.com/users/mmg10/events{/privacy}",
"received_events_url": "https://api.github.com/users/mmg10/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 2021-11-25T12:31:11 | 2021-11-26T10:30:29 | 2021-11-26T10:30:29 | NONE | null | null | null | ## Describe the bug
It gives an error.
> FileNotFoundError: Couldn't find file at https://github.com/facebookresearch/LASER/raw/master/data/tatoeba/v1/tatoeba.rus-eng.rus
## Steps to reproduce the bug
```python
data=load_dataset("xtreme","tatoeba.rus", split="validation")
```
## Solution
The library tries to access the **master** branch. In the github repo of facebookresearch, it is in the **main** branch. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3320/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3320/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3317/comments | https://api.github.com/repos/huggingface/datasets/issues/3317/events | https://github.com/huggingface/datasets/issues/3317 | 1,062,284,447 | I_kwDODunzps4_USyf | 3,317 | Add desc parameter to Dataset filter method | {
"login": "vblagoje",
"id": 458335,
"node_id": "MDQ6VXNlcjQ1ODMzNQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/458335?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vblagoje",
"html_url": "https://github.com/vblagoje",
"followers_url": "https://api.github.com/users/vblagoje/followers",
"following_url": "https://api.github.com/users/vblagoje/following{/other_user}",
"gists_url": "https://api.github.com/users/vblagoje/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vblagoje/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vblagoje/subscriptions",
"organizations_url": "https://api.github.com/users/vblagoje/orgs",
"repos_url": "https://api.github.com/users/vblagoje/repos",
"events_url": "https://api.github.com/users/vblagoje/events{/privacy}",
"received_events_url": "https://api.github.com/users/vblagoje/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\n`Dataset.map` allows more generic transforms compared to `Dataset.filter`, which purpose is very specific (to filter examples based on a condition). That's why I don't think we need the `desc` parameter there for consistency. #3196 has added descriptions to the `Dataset` methods that call `.map` intern... | 2021-11-24T11:01:36 | 2022-01-05T18:31:24 | 2022-01-05T18:31:24 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
As I was filtering very large datasets I noticed the filter method doesn't have the desc parameter which is available in the map method. Why don't we add a desc parameter to the filter method both for consistency and it's nice to give some feedback to users during long operations on Datasets?
**Describe the solution you'd like**
Add desc parameter to Dataset filter method
**Describe alternatives you've considered**
N/A
**Additional context**
N/A
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3317/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3317/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3316/comments | https://api.github.com/repos/huggingface/datasets/issues/3316/events | https://github.com/huggingface/datasets/issues/3316 | 1,062,185,822 | I_kwDODunzps4_T6te | 3,316 | Add RedCaps dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
... | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [] | 2021-11-24T09:23:02 | 2022-01-12T14:13:15 | 2022-01-12T14:13:15 | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** RedCaps
- **Description:** Web-curated image-text data created by the people, for the people
- **Paper:** https://arxiv.org/abs/2111.11431
- **Data:** https://redcaps.xyz/
- **Motivation:** Multimodal image-text dataset: 12M+ Image-text pairs
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
Proposed by @patil-suraj | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3316/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3316/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3313 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3313/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3313/comments | https://api.github.com/repos/huggingface/datasets/issues/3313/events | https://github.com/huggingface/datasets/issues/3313 | 1,060,933,392 | I_kwDODunzps4_PI8Q | 3,313 | TriviaQA License Mismatch | {
"login": "akhilkedia",
"id": 16665267,
"node_id": "MDQ6VXNlcjE2NjY1MjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/16665267?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/akhilkedia",
"html_url": "https://github.com/akhilkedia",
"followers_url": "https://api.github.com/users/akhilkedia/followers",
"following_url": "https://api.github.com/users/akhilkedia/following{/other_user}",
"gists_url": "https://api.github.com/users/akhilkedia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/akhilkedia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/akhilkedia/subscriptions",
"organizations_url": "https://api.github.com/users/akhilkedia/orgs",
"repos_url": "https://api.github.com/users/akhilkedia/repos",
"events_url": "https://api.github.com/users/akhilkedia/events{/privacy}",
"received_events_url": "https://api.github.com/users/akhilkedia/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! You're completely right, this must be mentioned in the dataset card.\r\nIf you're interesting in contributing, feel free to open a pull request to mention this in the `trivia_qa` dataset card in the \"Licensing Information\" section at https://github.com/huggingface/datasets/blob/master/datasets/trivia_qa/REA... | 2021-11-23T08:00:15 | 2021-11-29T11:24:21 | 2021-11-29T11:24:21 | NONE | null | null | null | ## Describe the bug
TriviaQA Webpage at http://nlp.cs.washington.edu/triviaqa/ says they do not own the copyright to the data. However, Huggingface datasets at https://huggingface.co/datasets/trivia_qa mentions that the dataset is released under Apache License
Is the License Information on HuggingFace correct? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3313/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3313/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3311 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3311/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3311/comments | https://api.github.com/repos/huggingface/datasets/issues/3311/events | https://github.com/huggingface/datasets/issues/3311 | 1,060,387,957 | I_kwDODunzps4_NDx1 | 3,311 | Add WebSRC | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [] | 2021-11-22T16:58:33 | 2021-11-22T16:58:33 | null | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** WebSRC
- **Description:** WebSRC is a novel Web-based Structural Reading Comprehension dataset. It consists of 0.44M question-answer pairs, which are collected from 6.5K web pages with corresponding HTML source code, screenshots and metadata.
- **Paper:** https://arxiv.org/abs/2101.09465
- **Data:** https://x-lance.github.io/WebSRC/dashboard.html#
- **Motivation:** Currently adding MarkupLM to HuggingFace Transformers, which achieves SOTA on this dataset.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3311/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3311/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3310 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3310/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3310/comments | https://api.github.com/repos/huggingface/datasets/issues/3310/events | https://github.com/huggingface/datasets/issues/3310 | 1,060,098,104 | I_kwDODunzps4_L9A4 | 3,310 | Fatal error condition occurred in aws-c-io | {
"login": "Crabzmatic",
"id": 31850219,
"node_id": "MDQ6VXNlcjMxODUwMjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/31850219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Crabzmatic",
"html_url": "https://github.com/Crabzmatic",
"followers_url": "https://api.github.com/users/Crabzmatic/followers",
"following_url": "https://api.github.com/users/Crabzmatic/following{/other_user}",
"gists_url": "https://api.github.com/users/Crabzmatic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Crabzmatic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Crabzmatic/subscriptions",
"organizations_url": "https://api.github.com/users/Crabzmatic/orgs",
"repos_url": "https://api.github.com/users/Crabzmatic/repos",
"events_url": "https://api.github.com/users/Crabzmatic/events{/privacy}",
"received_events_url": "https://api.github.com/users/Crabzmatic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Are you having this issue only with this specific dataset, or it also happens with other ones like `squad` ?",
"@lhoestq It happens also on `squad`. It successfully downloads the whole dataset and then crashes on: \r\n\r\n```\r\nFatal error condition occurred in D:\\bld\\aws-c-io_1633633258269\\work\\source... | 2021-11-22T12:27:54 | 2023-02-08T10:31:05 | 2021-11-29T22:22:37 | NONE | null | null | null | ## Describe the bug
Fatal error when using the library
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset('wikiann', 'en')
```
## Expected results
No fatal errors
## Actual results
```
Fatal error condition occurred in D:\bld\aws-c-io_1633633258269\work\source\event_loop.c:74: aws_thread_launch(&cleanup_thread, s_event_loop_destroy_async_thread_fn, el_group, &thread_options) == AWS_OP_SUCCESS
Exiting Application
```
## Environment info
- `datasets` version: 1.15.2.dev0
- Platform: Windows-10-10.0.22504-SP0
- Python version: 3.8.12
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3310/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3310/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3308 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3308/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3308/comments | https://api.github.com/repos/huggingface/datasets/issues/3308/events | https://github.com/huggingface/datasets/issues/3308 | 1,059,255,705 | I_kwDODunzps4_IvWZ | 3,308 | "dataset_infos.json" missing for chr_en and mc4 | {
"login": "amitness",
"id": 8587189,
"node_id": "MDQ6VXNlcjg1ODcxODk=",
"avatar_url": "https://avatars.githubusercontent.com/u/8587189?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amitness",
"html_url": "https://github.com/amitness",
"followers_url": "https://api.github.com/users/amitness/followers",
"following_url": "https://api.github.com/users/amitness/following{/other_user}",
"gists_url": "https://api.github.com/users/amitness/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amitness/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amitness/subscriptions",
"organizations_url": "https://api.github.com/users/amitness/orgs",
"repos_url": "https://api.github.com/users/amitness/repos",
"events_url": "https://api.github.com/users/amitness/events{/privacy}",
"received_events_url": "https://api.github.com/users/amitness/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg... | open | false | null | [] | null | [
"Hi ! Thanks for reporting :) \r\nWe can easily add the metadata for `chr_en` IMO, but for mC4 it will take more time, since it requires to count the number of examples in each language",
"No problem. I am trying to do some analysis on the metadata of all available datasets. Is reading `metadata_infos.json` for e... | 2021-11-21T00:07:22 | 2022-01-19T13:55:32 | null | NONE | null | null | null | ## Describe the bug
In the repository, every dataset has its metadata in a file called`dataset_infos.json`. But, this file is missing for two datasets: `chr_en` and `mc4`.
## Steps to reproduce the bug
Check [chr_en](https://github.com/huggingface/datasets/tree/master/datasets/chr_en) and [mc4](https://github.com/huggingface/datasets/tree/master/datasets/mc4) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3308/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3308/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3306/comments | https://api.github.com/repos/huggingface/datasets/issues/3306/events | https://github.com/huggingface/datasets/issues/3306 | 1,059,185,860 | I_kwDODunzps4_IeTE | 3,306 | nested sequence feature won't encode example if the first item of the outside sequence is an empty list | {
"login": "function2-llx",
"id": 38486514,
"node_id": "MDQ6VXNlcjM4NDg2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/38486514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/function2-llx",
"html_url": "https://github.com/function2-llx",
"followers_url": "https://api.github.com/users/function2-llx/followers",
"following_url": "https://api.github.com/users/function2-llx/following{/other_user}",
"gists_url": "https://api.github.com/users/function2-llx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/function2-llx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/function2-llx/subscriptions",
"organizations_url": "https://api.github.com/users/function2-llx/orgs",
"repos_url": "https://api.github.com/users/function2-llx/repos",
"events_url": "https://api.github.com/users/function2-llx/events{/privacy}",
"received_events_url": "https://api.github.com/users/function2-llx/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"knock knock",
"Hi, thanks for reporting! I've linked a PR that should fix the issue.",
"I've checked the PR and it looks great, thanks a lot!"
] | 2021-11-20T16:57:54 | 2021-12-08T13:02:15 | 2021-12-08T13:02:15 | NONE | null | null | null | ## Describe the bug
As the title, nested sequence feature won't encode example if the first item of the outside sequence is an empty list.
## Steps to reproduce the bug
```python
from datasets import Features, Sequence, ClassLabel
features = Features({
'x': Sequence(Sequence(ClassLabel(names=['a', 'b']))),
})
print(features.encode_batch({
'x': [
[['a'], ['b']],
[[], ['b']],
]
}))
```
## Expected results
print `{'x': [[[0], [1]], [[], ['1']]]}`
## Actual results
print `{'x': [[[0], [1]], [[], ['b']]]}`
## Environment info
- `datasets` version: 1.15.1
- Platform: Linux-5.13.0-21-generic-x86_64-with-glibc2.34
- Python version: 3.9.7
- PyArrow version: 6.0.0
## Additional information
I think the issue stems from [here](https://github.com/huggingface/datasets/blob/8555197a3fe826e98bd0206c2d031c4488c53c5c/src/datasets/features/features.py#L847-L848).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3306/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/datasets/issues/3306/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3304/comments | https://api.github.com/repos/huggingface/datasets/issues/3304/events | https://github.com/huggingface/datasets/issues/3304 | 1,059,130,494 | I_kwDODunzps4_IQx- | 3,304 | Dataset object has no attribute `to_tf_dataset` | {
"login": "RajkumarGalaxy",
"id": 59993678,
"node_id": "MDQ6VXNlcjU5OTkzNjc4",
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RajkumarGalaxy",
"html_url": "https://github.com/RajkumarGalaxy",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
"gists_url": "https://api.github.com/users/RajkumarGalaxy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RajkumarGalaxy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RajkumarGalaxy/subscriptions",
"organizations_url": "https://api.github.com/users/RajkumarGalaxy/orgs",
"repos_url": "https://api.github.com/users/RajkumarGalaxy/repos",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"received_events_url": "https://api.github.com/users/RajkumarGalaxy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"The issue is due to the older version of transformers and datasets. It has been resolved by upgrading their versions.\r\n\r\n```\r\n# upgrade transformers and datasets to latest versions\r\n!pip install --upgrade transformers\r\n!pip install --upgrade datasets\r\n```\r\n\r\nRegards!"
] | 2021-11-20T12:03:59 | 2021-11-21T07:07:25 | 2021-11-21T07:07:25 | NONE | null | null | null | I am following HuggingFace Course. I am at Fine-tuning a model.
Link: https://huggingface.co/course/chapter3/2?fw=tf
I use tokenize_function and `map` as mentioned in the course to process data.
`# define a tokenize function`
`def Tokenize_function(example):`
` return tokenizer(example['sentence'], truncation=True)`
`# tokenize entire data`
`tokenized_data = raw_data.map(Tokenize_function, batched=True)`
I get Dataset object at this point. When I try converting this to a TF dataset object as mentioned in the course, it throws the following error.
`# convert to TF dataset`
`train_data = tokenized_data["train"].to_tf_dataset( `
` columns = ['attention_mask', 'input_ids', 'token_type_ids'], `
` label_cols = ['label'], `
` shuffle = True, `
` collate_fn = data_collator, `
` batch_size = 8 `
`)`
Output:
`---------------------------------------------------------------------------`
`AttributeError Traceback (most recent call last)`
`/tmp/ipykernel_42/103099799.py in <module>`
` 1 # convert to TF dataset`
`----> 2 train_data = tokenized_data["train"].to_tf_dataset( \`
` 3 columns = ['attention_mask', 'input_ids', 'token_type_ids'], \`
` 4 label_cols = ['label'], \`
` 5 shuffle = True, \`
`AttributeError: 'Dataset' object has no attribute 'to_tf_dataset'`
When I look for `dir(tokenized_data["train"])`, there is no method or attribute in the name of `to_tf_dataset`.
Why do I get this error? And how to clear this?
Please help me. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3304/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3304/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3303 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3303/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3303/comments | https://api.github.com/repos/huggingface/datasets/issues/3303/events | https://github.com/huggingface/datasets/issues/3303 | 1,059,129,732 | I_kwDODunzps4_IQmE | 3,303 | DataCollatorWithPadding: TypeError | {
"login": "RajkumarGalaxy",
"id": 59993678,
"node_id": "MDQ6VXNlcjU5OTkzNjc4",
"avatar_url": "https://avatars.githubusercontent.com/u/59993678?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RajkumarGalaxy",
"html_url": "https://github.com/RajkumarGalaxy",
"followers_url": "https://api.github.com/users/RajkumarGalaxy/followers",
"following_url": "https://api.github.com/users/RajkumarGalaxy/following{/other_user}",
"gists_url": "https://api.github.com/users/RajkumarGalaxy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RajkumarGalaxy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RajkumarGalaxy/subscriptions",
"organizations_url": "https://api.github.com/users/RajkumarGalaxy/orgs",
"repos_url": "https://api.github.com/users/RajkumarGalaxy/repos",
"events_url": "https://api.github.com/users/RajkumarGalaxy/events{/privacy}",
"received_events_url": "https://api.github.com/users/RajkumarGalaxy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"\r\n> \r\n> Input:\r\n> \r\n> ```\r\n> tokenizer = AutoTokenizer.from_pretrained(checkpoint)\r\n> data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors=\"tf\")\r\n> ```\r\n> \r\n> Output:\r\n> \r\n> ```\r\n> TypeError Traceback (most recent call last)\r\n> /tmp... | 2021-11-20T11:59:55 | 2021-11-21T07:05:37 | 2021-11-21T07:05:37 | NONE | null | null | null | Hi,
I am following the HuggingFace course. I am now at Fine-tuning [https://huggingface.co/course/chapter3/3?fw=tf](https://huggingface.co/course/chapter3/3?fw=tf). When I set up `DataCollatorWithPadding` as following I got an error while trying to reproduce the course code in Kaggle. This error occurs with either a CPU-only-device or a GPU-device.
Input:
```checkpoint = 'bert-base-uncased'
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
```
Output:
```---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
/tmp/ipykernel_42/1563280798.py in <module>
1 checkpoint = 'bert-base-uncased'
2 tokenizer = AutoTokenizer.from_pretrained(checkpoint)
----> 3 data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="pt")
TypeError: __init__() got an unexpected keyword argument 'return_tensors'
```
When I call `help` method, it too confirms that there is no argument `return_tensors`.
Input:
```
help(DataCollatorWithPadding.__init__)
```
Output:
```
Help on function __init__ in module transformers.data.data_collator:
__init__(self, tokenizer: transformers.tokenization_utils_base.PreTrainedTokenizerBase, padding: Union[bool, str, transformers.file_utils.PaddingStrategy] = True, max_length: Union[int, NoneType] = None, pad_to_multiple_of: Union[int, NoneType] = None) -> None
```
But, the source file *[Data Collator - docs](https://huggingface.co/transformers/main_classes/data_collator.html#datacollatorwithpadding)* says that there is such an argument. By default, it returns Pytorch tensors while I need TF tensors.
Where do I miss?
Please help me. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3303/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3303/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3300 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3300/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3300/comments | https://api.github.com/repos/huggingface/datasets/issues/3300/events | https://github.com/huggingface/datasets/issues/3300 | 1,058,644,459 | I_kwDODunzps4_GaHr | 3,300 | ❓ Dataset loading script from Hugging Face Hub | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3470211881,
... | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Hi ! In the next version of `datasets`, your train and test splits will be correctly separated (changes from #3027) if you create a dataset repository with only your CSV files.\r\n\r\nAlso it seems that you overwrite the `data_files` and `data_dir` arguments in your code, when you instantiate the AGNewsConfig obje... | 2021-11-19T15:20:52 | 2021-12-22T10:57:56 | 2021-12-22T10:57:56 | NONE | null | null | null | Hi there,
I am trying to add my custom `ag_news` with its own loading script on the Hugging Face datasets hub. In particular, I would like to test the addition of a second configuration to the existing `ag_news` dataset. Once it works in my hub, I plan to make a PR to the original dataset. However, in trying to do so I have encountered certain problems as detailed below.
Issues I have encountered:
- Without a loading script, the train and test files are loaded together into a unique `dataset.Dataset` -> so I wrote a loading script. Also, I need a loading script otherwise I cannot specify multiple configurations
- Once my loading script is working locally, I do not manage to make it work on the hub. In particular, I would like to be able to load the dataset like this
```python
load_dataset("pietrolesci/ag_news", name="my_configuration")
```
Apparently, the `load_dataset` is able to pick up the loading script from the hub and run it. However, it errors because it is unable to find the files. The structure of my hub repo is the following
```
ag_news.py
train.csv
test.csv
```
and the loading script I specify `data_dir=Path(__file__).parent` and `data_files=DataFilesDict({"train": "train.csv", "test": "test.csv"})`. In the documentation I could not find info regarding loading a dataset from the hub using a loading script present on the hub.
Any suggestion is very much appreciated.
Best,
Pietro
Link to the hub repo: https://huggingface.co/datasets/pietrolesci/ag_news
BONUS: how can I make the data viewer work in this specific case? :) | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3300/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3300/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3299 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3299/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3299/comments | https://api.github.com/repos/huggingface/datasets/issues/3299/events | https://github.com/huggingface/datasets/issues/3299 | 1,058,518,213 | I_kwDODunzps4_F7TF | 3,299 | Add option to find unique elements in nested sequences when calling `Dataset.unique` | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"Hi @mariosasko!\r\n\r\nHas this been patched into any of the releases?",
"Hi! Not yet, would you be interested in contributing a PR? I can give you some pointers if needed. ",
"@mariosasko did this ever get implemented? Willing to help if you are still up for it.",
"@dcruiz01 No, but here is an example of ho... | 2021-11-19T13:16:06 | 2023-05-19T14:45:40 | null | CONTRIBUTOR | null | null | null | It would be nice to have an option to flatten nested sequences to find unique elements stored in them when calling `Dataset.unique`. ~~Currently, `Dataset.unique` only supports finding unique sequences and not unique elements in that situation.~~ | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3299/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3299/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3298/comments | https://api.github.com/repos/huggingface/datasets/issues/3298/events | https://github.com/huggingface/datasets/issues/3298 | 1,058,420,201 | I_kwDODunzps4_FjXp | 3,298 | Agnews dataset viewer is not working | {
"login": "pietrolesci",
"id": 61748653,
"node_id": "MDQ6VXNlcjYxNzQ4NjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/61748653?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pietrolesci",
"html_url": "https://github.com/pietrolesci",
"followers_url": "https://api.github.com/users/pietrolesci/followers",
"following_url": "https://api.github.com/users/pietrolesci/following{/other_user}",
"gists_url": "https://api.github.com/users/pietrolesci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pietrolesci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pietrolesci/subscriptions",
"organizations_url": "https://api.github.com/users/pietrolesci/orgs",
"repos_url": "https://api.github.com/users/pietrolesci/repos",
"events_url": "https://api.github.com/users/pietrolesci/events{/privacy}",
"received_events_url": "https://api.github.com/users/pietrolesci/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting\r\nWe've already fixed the code that generates the preview for this dataset, we'll release the fix soon :)",
"Hi @lhoestq, thanks for your feedback!",
"Fixed in the viewer.\r\n\r\nhttps://huggingface.co/datasets/ag_news"
] | 2021-11-19T11:18:59 | 2021-12-21T16:24:05 | 2021-12-21T16:24:05 | NONE | null | null | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:** https://huggingface.co/datasets/ag_news
Hi there, the `ag_news` dataset viewer is not working.
Am I the one who added this dataset? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3298/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3298/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3297 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3297/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3297/comments | https://api.github.com/repos/huggingface/datasets/issues/3297/events | https://github.com/huggingface/datasets/issues/3297 | 1,058,263,859 | I_kwDODunzps4_E9Mz | 3,297 | .map() cache is wrongfully reused - only happens when the mapping function is imported | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "https://api.github.com/users/eladsegal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladsegal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladsegal/subscriptions",
"organizations_url": "https://api.github.com/users/eladsegal/orgs",
"repos_url": "https://api.github.com/users/eladsegal/repos",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladsegal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [
"Hi ! Thanks for reporting. Indeed this is a current limitation of the usage we have of `dill` in `datasets`. I'd suggest you use your workaround for now until we find a way to fix this. Maybe functions that are not coming from a module not installed with pip should be dumped completely, rather than only taking the... | 2021-11-19T08:18:36 | 2023-01-30T12:40:17 | null | CONTRIBUTOR | null | null | null | ## Describe the bug
When `.map` is used with a mapping function that is imported, the cache is reused even if the mapping function has been modified.
The reason for this is that `dill` that is used for creating the fingerprint [pickles imported functions by reference](https://stackoverflow.com/a/67851411).
I guess it is not a widespread case, but it can still lead to unwanted results unnoticeably.
## Steps to reproduce the bug
Create files `a.py` and `b.py`:
```python
# a.py
from datasets import load_dataset
def main():
squad = load_dataset("squad")
squad.map(mapping_func, batched=True)
def mapping_func(examples):
ID_LENGTH = 4
examples["id"] = [id_[:ID_LENGTH] for id_ in examples["id"]]
return examples
if __name__ == "__main__":
main()
```
```python
# b.py
from datasets import load_dataset
from a import mapping_func
def main():
squad = load_dataset("squad")
squad.map(mapping_func, batched=True)
if __name__ == "__main__":
main()
```
Run `python b.py` twice: In the first run you will see tqdm bars showing that the data is processed, and in the second run you will see "Loading cached processed dataset at...".
Now change `ID_LENGTH` to another number in order to change the mapping function, and run `python b.py` again. You'll see that `.map` loads from the cache the result of the previous mapping function.
## Expected results
Run `python a.py` twice: In the first run you will see tqdm bars showing that the data is processed, and in the second run you will see "Loading cached processed dataset at...".
Now change `ID_LENGTH` to another number in order to change the mapping function, and run `python a.py` again. You'll see that the dataset is being processed and that there's no reuse of the previous mapping function result.
## Workaround
Put the mapping function inside a dummy class as a static method:
```python
# a.py
class MappingFuncClass:
@staticmethod
def mapping_func(examples):
ID_LENGTH = 4
examples["id"] = [id_[:ID_LENGTH] for id_ in examples["id"]]
return examples
```
```python
# b.py
from datasets import load_dataset
from a import MappingFuncClass
def main():
squad = load_dataset("squad")
squad.map(MappingFuncClass.mapping_func, batched=True)
if __name__ == "__main__":
main()
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3297/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3297/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3295 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3295/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3295/comments | https://api.github.com/repos/huggingface/datasets/issues/3295/events | https://github.com/huggingface/datasets/issues/3295 | 1,057,954,892 | I_kwDODunzps4_DxxM | 3,295 | Temporary dataset_path for remote fs URIs not built properly in arrow_dataset.py::load_from_disk | {
"login": "francisco-perez-sorrosal",
"id": 918006,
"node_id": "MDQ6VXNlcjkxODAwNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/918006?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/francisco-perez-sorrosal",
"html_url": "https://github.com/francisco-perez-sorrosal",
"followers_url": "https://api.github.com/users/francisco-perez-sorrosal/followers",
"following_url": "https://api.github.com/users/francisco-perez-sorrosal/following{/other_user}",
"gists_url": "https://api.github.com/users/francisco-perez-sorrosal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/francisco-perez-sorrosal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/francisco-perez-sorrosal/subscriptions",
"organizations_url": "https://api.github.com/users/francisco-perez-sorrosal/orgs",
"repos_url": "https://api.github.com/users/francisco-perez-sorrosal/repos",
"events_url": "https://api.github.com/users/francisco-perez-sorrosal/events{/privacy}",
"received_events_url": "https://api.github.com/users/francisco-perez-sorrosal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! Good catch and thanks for opening a PR :)\r\n\r\nI just responded in your PR"
] | 2021-11-18T23:24:02 | 2021-12-06T10:45:04 | 2021-12-06T10:45:04 | CONTRIBUTOR | null | null | null | ## Describe the bug
When trying to build a temporary dataset path from a remote URI in this block of code:
https://github.com/huggingface/datasets/blob/42f6b1d18a4a1b6009b6e62d115491be16dfca22/src/datasets/arrow_dataset.py#L1038-L1042
the result is not the expected when passing an absolute path in an URI like `hdfs:///absolute/path`.
## Steps to reproduce the bug
```python
dataset_path = "hdfs:///absolute/path"
src_dataset_path = extract_path_from_uri(dataset_path)
tmp_dir = get_temporary_cache_files_directory()
dataset_path = Path(tmp_dir, src_dataset_path)
print(dataset_path)
```
## Expected results
With the code above, we would expect a value in `dataset_path` similar to:
`/tmp/tmpnwxyvao5/absolute/path`
## Actual results
However, we get a `dataset_path` value like:
`/absolute/path`
This is because this line here: https://github.com/huggingface/datasets/blob/42f6b1d18a4a1b6009b6e62d115491be16dfca22/src/datasets/arrow_dataset.py#L1041
returns the last absolute path when two absolute paths (the one in `tmp_dir` and the one extracted from the URI in `src_dataset_path`) are passed as arguments.
## Environment info
- `datasets` version: 1.13.3
- Platform: Linux-3.10.0-1160.15.2.el7.x86_64-x86_64-with-glibc2.33
- Python version: 3.9.7
- PyArrow version: 5.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3295/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3295/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3294 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3294/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3294/comments | https://api.github.com/repos/huggingface/datasets/issues/3294/events | https://github.com/huggingface/datasets/issues/3294 | 1,057,495,473 | I_kwDODunzps4_CBmx | 3,294 | Add Natural Adversarial Objects dataset | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
... | open | false | null | [] | null | [] | 2021-11-18T15:34:44 | 2021-12-08T12:00:02 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Natural Adversarial Objects (NAO)
- **Description:** Natural Adversarial Objects (NAO) is a new dataset to evaluate the robustness of object detection models. NAO contains 7,934 images and 9,943 objects that are unmodified and representative of real-world scenarios, but cause state-of-the-art detection models to misclassify with high confidence.
- **Paper:** https://arxiv.org/abs/2111.04204v1
- **Data:** https://drive.google.com/drive/folders/15P8sOWoJku6SSEiHLEts86ORfytGezi8
- **Motivation:** interesting object detection dataset useful for miscclassifications
cc @NielsRogge
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3294/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3294/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3292/comments | https://api.github.com/repos/huggingface/datasets/issues/3292/events | https://github.com/huggingface/datasets/issues/3292 | 1,056,962,554 | I_kwDODunzps4-__f6 | 3,292 | Not able to load 'wikipedia' dataset | {
"login": "abhibisht89",
"id": 13541524,
"node_id": "MDQ6VXNlcjEzNTQxNTI0",
"avatar_url": "https://avatars.githubusercontent.com/u/13541524?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhibisht89",
"html_url": "https://github.com/abhibisht89",
"followers_url": "https://api.github.com/users/abhibisht89/followers",
"following_url": "https://api.github.com/users/abhibisht89/following{/other_user}",
"gists_url": "https://api.github.com/users/abhibisht89/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhibisht89/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhibisht89/subscriptions",
"organizations_url": "https://api.github.com/users/abhibisht89/orgs",
"repos_url": "https://api.github.com/users/abhibisht89/repos",
"events_url": "https://api.github.com/users/abhibisht89/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhibisht89/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"Hi ! Indeed it looks like the code snippet on the Hugging face Hub doesn't show the second parameter\r\n\r\n\r\n\r\nThanks for reporting, I'm taking a look\r\n"
] | 2021-11-18T05:41:18 | 2021-11-19T16:49:29 | 2021-11-19T16:49:29 | NONE | null | null | null | ## Describe the bug
I am following the instruction for loading the wikipedia dataset using datasets. However getting the below error.
## Steps to reproduce the bug
from datasets import load_dataset
dataset = load_dataset("wikipedia")
```
## Expected results
A clear and concise description of the expected results.
## Actual results
~/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/datasets/builder.py in _create_builder_config(self, name, custom_features, **config_kwargs)
339 "Config name is missing."
340 "\nPlease pick one among the available configs: %s" % list(self.builder_configs.keys())
--> 341 + "\nExample of usage:\n\t`{}`".format(example_of_usage)
342 )
343 builder_config = self.BUILDER_CONFIGS[0]
ValueError: Config name is missing.
Please pick one among the available configs: ['20200501.aa', '20200501.ab', '20200501.ace', '20200501.ady', '20200501.af', '20200501.ak', '20200501.als', '20200501.am', '20200501.an', '20200501.ang', '20200501.ar', '20200501.arc', '20200501.arz', '20200501.as', '20200501.ast', '20200501.atj', '20200501.av', '20200501.ay', '20200501.az', '20200501.azb', '20200501.ba', '20200501.bar', '20200501.bat-smg', '20200501.bcl', '20200501.be', '20200501.be-x-old', '20200501.bg', '20200501.bh', '20200501.bi', '20200501.bjn', '20200501.bm', '20200501.bn', '20200501.bo', '20200501.bpy', '20200501.br', '20200501.bs', '20200501.bug', '20200501.bxr', '20200501.ca', '20200501.cbk-zam', '20200501.cdo', '20200501.ce', '20200501.ceb', '20200501.ch', '20200501.cho', '20200501.chr', '20200501.chy', '20200501.ckb', '20200501.co', '20200501.cr', '20200501.crh', '20200501.cs', '20200501.csb', '20200501.cu', '20200501.cv', '20200501.cy', '20200501.da', '20200501.de', '20200501.din', '20200501.diq', '20200501.dsb', '20200501.dty', '20200501.dv', '20200501.dz', '20200501.ee', '20200501.el', '20200501.eml', '20200501.en', '20200501.eo', '20200501.es', '20200501.et', '20200501.eu', '20200501.ext', '20200501.fa', '20200501.ff', '20200501.fi', '20200501.fiu-vro', '20200501.fj', '20200501.fo', '20200501.fr', '20200501.frp', '20200501.frr', '20200501.fur', '20200501.fy', '20200501.ga', '20200501.gag', '20200501.gan', '20200501.gd', '20200501.gl', '20200501.glk', '20200501.gn', '20200501.gom', '20200501.gor', '20200501.got', '20200501.gu', '20200501.gv', '20200501.ha', '20200501.hak', '20200501.haw', '20200501.he', '20200501.hi', '20200501.hif', '20200501.ho', '20200501.hr', '20200501.hsb', '20200501.ht', '20200501.hu', '20200501.hy', '20200501.ia', '20200501.id', '20200501.ie', '20200501.ig', '20200501.ii', '20200501.ik', '20200501.ilo', '20200501.inh', '20200501.io', '20200501.is', '20200501.it', '20200501.iu', '20200501.ja', '20200501.jam', '20200501.jbo', '20200501.jv', '20200501.ka', '20200501.kaa', '20200501.kab', '20200501.kbd', '20200501.kbp', '20200501.kg', '20200501.ki', '20200501.kj', '20200501.kk', '20200501.kl', '20200501.km', '20200501.kn', '20200501.ko', '20200501.koi', '20200501.krc', '20200501.ks', '20200501.ksh', '20200501.ku', '20200501.kv', '20200501.kw', '20200501.ky', '20200501.la', '20200501.lad', '20200501.lb', '20200501.lbe', '20200501.lez', '20200501.lfn', '20200501.lg', '20200501.li', '20200501.lij', '20200501.lmo', '20200501.ln', '20200501.lo', '20200501.lrc', '20200501.lt', '20200501.ltg', '20200501.lv', '20200501.mai', '20200501.map-bms', '20200501.mdf', '20200501.mg', '20200501.mh', '20200501.mhr', '20200501.mi', '20200501.min', '20200501.mk', '20200501.ml', '20200501.mn', '20200501.mr', '20200501.mrj', '20200501.ms', '20200501.mt', '20200501.mus', '20200501.mwl', '20200501.my', '20200501.myv', '20200501.mzn', '20200501.na', '20200501.nah', '20200501.nap', '20200501.nds', '20200501.nds-nl', '20200501.ne', '20200501.new', '20200501.ng', '20200501.nl', '20200501.nn', '20200501.no', '20200501.nov', '20200501.nrm', '20200501.nso', '20200501.nv', '20200501.ny', '20200501.oc', '20200501.olo', '20200501.om', '20200501.or', '20200501.os', '20200501.pa', '20200501.pag', '20200501.pam', '20200501.pap', '20200501.pcd', '20200501.pdc', '20200501.pfl', '20200501.pi', '20200501.pih', '20200501.pl', '20200501.pms', '20200501.pnb', '20200501.pnt', '20200501.ps', '20200501.pt', '20200501.qu', '20200501.rm', '20200501.rmy', '20200501.rn', '20200501.ro', '20200501.roa-rup', '20200501.roa-tara', '20200501.ru', '20200501.rue', '20200501.rw', '20200501.sa', '20200501.sah', '20200501.sat', '20200501.sc', '20200501.scn', '20200501.sco', '20200501.sd', '20200501.se', '20200501.sg', '20200501.sh', '20200501.si', '20200501.simple', '20200501.sk', '20200501.sl', '20200501.sm', '20200501.sn', '20200501.so', '20200501.sq', '20200501.sr', '20200501.srn', '20200501.ss', '20200501.st', '20200501.stq', '20200501.su', '20200501.sv', '20200501.sw', '20200501.szl', '20200501.ta', '20200501.tcy', '20200501.te', '20200501.tet', '20200501.tg', '20200501.th', '20200501.ti', '20200501.tk', '20200501.tl', '20200501.tn', '20200501.to', '20200501.tpi', '20200501.tr', '20200501.ts', '20200501.tt', '20200501.tum', '20200501.tw', '20200501.ty', '20200501.tyv', '20200501.udm', '20200501.ug', '20200501.uk', '20200501.ur', '20200501.uz', '20200501.ve', '20200501.vec', '20200501.vep', '20200501.vi', '20200501.vls', '20200501.vo', '20200501.wa', '20200501.war', '20200501.wo', '20200501.wuu', '20200501.xal', '20200501.xh', '20200501.xmf', '20200501.yi', '20200501.yo', '20200501.za', '20200501.zea', '20200501.zh', '20200501.zh-classical', '20200501.zh-min-nan', '20200501.zh-yue', '20200501.zu']
Example of usage:
`load_dataset('wikipedia', '20200501.aa')`
I think the other parameter is missing in the load_dataset function that is not shown in the instruction. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3292/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3292/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3285 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3285/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3285/comments | https://api.github.com/repos/huggingface/datasets/issues/3285/events | https://github.com/huggingface/datasets/issues/3285 | 1,055,506,730 | I_kwDODunzps4-6cEq | 3,285 | Add IEMOCAP dataset | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
... | open | false | null | [] | null | [
"The IEMOCAP dataset is private and available only on request.\r\n```\r\nTo obtain the IEMOCAP data you just need to fill out an electronic release form below.\r\n```\r\n\r\n- [Request form](https://sail.usc.edu/iemocap/release_form.php)\r\n- [License ](https://sail.usc.edu/iemocap/Data_Release_Form_IEMOCAP.pdf)\r\... | 2021-11-16T22:47:20 | 2023-06-10T08:14:52 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** IEMOCAP
- **Description:** acted, multimodal and multispeaker database
- **Paper:** https://sail.usc.edu/iemocap/Busso_2008_iemocap.pdf
- **Data:** https://sail.usc.edu/iemocap/index.html
- **Motivation:** Useful multimodal dataset
cc @anton-l
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3285/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3285/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3284/comments | https://api.github.com/repos/huggingface/datasets/issues/3284/events | https://github.com/huggingface/datasets/issues/3284 | 1,055,502,909 | I_kwDODunzps4-6bI9 | 3,284 | Add VoxLingua107 dataset | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
... | open | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [
"#self-assign"
] | 2021-11-16T22:44:08 | 2021-12-06T09:49:45 | null | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** VoxLingua107
- **Description:** VoxLingua107 is a speech dataset for training spoken language identification models. The dataset consists of short speech segments automatically extracted from YouTube videos and labeled according the language of the video title and description, with some post-processing steps to filter out false positives.
- **Paper:** https://arxiv.org/abs/2011.12998
- **Data:** http://bark.phon.ioc.ee/voxlingua107/
- **Motivation:** Nice audio classification dataset
cc @anton-l
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3284/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3284/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3283 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3283/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3283/comments | https://api.github.com/repos/huggingface/datasets/issues/3283/events | https://github.com/huggingface/datasets/issues/3283 | 1,055,495,874 | I_kwDODunzps4-6ZbC | 3,283 | Add Speech Commands dataset | {
"login": "osanseviero",
"id": 7246357,
"node_id": "MDQ6VXNlcjcyNDYzNTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7246357?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/osanseviero",
"html_url": "https://github.com/osanseviero",
"followers_url": "https://api.github.com/users/osanseviero/followers",
"following_url": "https://api.github.com/users/osanseviero/following{/other_user}",
"gists_url": "https://api.github.com/users/osanseviero/gists{/gist_id}",
"starred_url": "https://api.github.com/users/osanseviero/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/osanseviero/subscriptions",
"organizations_url": "https://api.github.com/users/osanseviero/orgs",
"repos_url": "https://api.github.com/users/osanseviero/repos",
"events_url": "https://api.github.com/users/osanseviero/events{/privacy}",
"received_events_url": "https://api.github.com/users/osanseviero/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 2725241052,
... | closed | false | {
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gists_url": "https://api.github.com/users/polinaeterna/gists{/gist_id}",
"starred_url": "https://api.github.com/users/polinaeterna/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/polinaeterna/subscriptions",
"organizations_url": "https://api.github.com/users/polinaeterna/orgs",
"repos_url": "https://api.github.com/users/polinaeterna/repos",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"received_events_url": "https://api.github.com/users/polinaeterna/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "polinaeterna",
"id": 16348744,
"node_id": "MDQ6VXNlcjE2MzQ4NzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/polinaeterna",
"html_url": "https://github.com/polinaeterna",
"followers_url": "... | null | [
"#self-assign"
] | 2021-11-16T22:39:56 | 2021-12-10T10:30:15 | 2021-12-10T10:30:15 | MEMBER | null | null | null | ## Adding a Dataset
- **Name:** Speech commands
- **Description:** A Dataset for Limited-Vocabulary Speech Recognition
- **Paper:** https://arxiv.org/abs/1804.03209
- **Data:** https://www.tensorflow.org/datasets/catalog/speech_commands, Available:
http://download.tensorflow.org/data/speech_commands_v0.02.tar.gz
- **Motivation:** Nice dataset for audio classification training
cc @anton-l
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3283/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3283/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3282/comments | https://api.github.com/repos/huggingface/datasets/issues/3282/events | https://github.com/huggingface/datasets/issues/3282 | 1,055,054,898 | I_kwDODunzps4-4twy | 3,282 | ConnectionError: Couldn't reach https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/resolve/main/OSCAR-2109.py | {
"login": "MinionAttack",
"id": 10078549,
"node_id": "MDQ6VXNlcjEwMDc4NTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/10078549?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MinionAttack",
"html_url": "https://github.com/MinionAttack",
"followers_url": "https://api.github.com/users/MinionAttack/followers",
"following_url": "https://api.github.com/users/MinionAttack/following{/other_user}",
"gists_url": "https://api.github.com/users/MinionAttack/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MinionAttack/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MinionAttack/subscriptions",
"organizations_url": "https://api.github.com/users/MinionAttack/orgs",
"repos_url": "https://api.github.com/users/MinionAttack/repos",
"events_url": "https://api.github.com/users/MinionAttack/events{/privacy}",
"received_events_url": "https://api.github.com/users/MinionAttack/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting :)\r\nI think this is because the dataset is behind an access page. We can fix the dataset viewer\r\n\r\nIf you also have this error when you use the `datasets` library in python, you should probably pass `use_auth_token=True` to the `load_dataset()` function to use your account to access... | 2021-11-16T16:05:19 | 2022-04-12T11:57:43 | 2022-04-12T11:57:43 | NONE | null | null | null | ## Dataset viewer issue for '*oscar-corpus/OSCAR-2109*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/oscar-corpus/OSCAR-2109)*
*The dataset library cannot download any language from the oscar-corpus/OSCAR-2109 dataset. By entering the URL in your browser I can access the file.*
```
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://huggingface.co/datasets/oscar-corpus/OSCAR-2109/resolve/main/OSCAR-2109.py
```
Am I the one who added this dataset ? No
Using the older version of [OSCAR](https://huggingface.co/datasets/oscar) I don't have any issues downloading languages with the dataset library. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3282/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3282/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3273 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3273/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3273/comments | https://api.github.com/repos/huggingface/datasets/issues/3273/events | https://github.com/huggingface/datasets/issues/3273 | 1,053,554,038 | I_kwDODunzps4-y_V2 | 3,273 | Respect row ordering when concatenating datasets along axis=1 | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [] | 2021-11-15T11:27:14 | 2021-11-17T15:41:11 | 2021-11-17T15:41:11 | CONTRIBUTOR | null | null | null | Currently, there is a bug when concatenating datasets along `axis=1` if more than one dataset has the `_indices` attribute defined. In that scenario, all indices mappings except the first one get ignored.
A minimal reproducible example:
```python
>>> from datasets import Dataset, concatenate_datasets
>>> a = Dataset.from_dict({"a": [30, 20, 10]})
>>> b = Dataset.from_dict({"b": [2, 1, 3]})
>>> d = concatenate_datasets([a.sort("a"), b.sort("b")], axis=1)
>>> print(d[:3]) # expected: {'a': [10, 20, 30], 'b': [1, 2, 3]}
{'a': [10, 20, 30], 'b': [3, 1, 2]}
```
I've noticed the bug while working on #3195. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3273/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3273/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3272 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3272/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3272/comments | https://api.github.com/repos/huggingface/datasets/issues/3272/events | https://github.com/huggingface/datasets/issues/3272 | 1,053,516,479 | I_kwDODunzps4-y2K_ | 3,272 | Make iter_archive work with ZIP files | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | {
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehdi2402/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehdi2402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehdi2402/subscriptions",
"organizations_url": "https://api.github.com/users/Mehdi2402/orgs",
"repos_url": "https://api.github.com/users/Mehdi2402/repos",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehdi2402/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://a... | null | [
"Hello, is this issue open for any contributor ? can I work on it ?\r\n\r\n",
"Hi ! Sure this is open for any contributor. If you're interested feel free to self-assign this issue to you by commenting `#self-assign`. Then if you have any question or if I can help, feel free to ping me.\r\n\r\nTo begin with, feel ... | 2021-11-15T10:50:42 | 2021-11-25T00:08:47 | null | MEMBER | null | null | null | Currently users can use `dl_manager.iter_archive` in their dataset script to iterate over all the files of a TAR archive.
It would be nice if it could work with ZIP files too ! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3272/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3272/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3269/comments | https://api.github.com/repos/huggingface/datasets/issues/3269/events | https://github.com/huggingface/datasets/issues/3269 | 1,053,218,769 | I_kwDODunzps4-xtfR | 3,269 | coqa NonMatchingChecksumError | {
"login": "ZhaofengWu",
"id": 11954789,
"node_id": "MDQ6VXNlcjExOTU0Nzg5",
"avatar_url": "https://avatars.githubusercontent.com/u/11954789?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZhaofengWu",
"html_url": "https://github.com/ZhaofengWu",
"followers_url": "https://api.github.com/users/ZhaofengWu/followers",
"following_url": "https://api.github.com/users/ZhaofengWu/following{/other_user}",
"gists_url": "https://api.github.com/users/ZhaofengWu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZhaofengWu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZhaofengWu/subscriptions",
"organizations_url": "https://api.github.com/users/ZhaofengWu/orgs",
"repos_url": "https://api.github.com/users/ZhaofengWu/repos",
"events_url": "https://api.github.com/users/ZhaofengWu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZhaofengWu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @ZhaofengWu, thanks for reporting.\r\n\r\nUnfortunately, I'm not able to reproduce your bug:\r\n```python\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"coqa\")\r\nDownloading: 3.82kB [00:00, 1.91MB/s]\r\nDownloading: 1.79kB [00:00, 1.79MB/s]\r\nUsing custom data configuration d... | 2021-11-15T05:04:07 | 2022-01-19T13:58:19 | 2022-01-19T13:58:19 | NONE | null | null | null | ```
>>> from datasets import load_dataset
>>> dataset = load_dataset("coqa")
Downloading: 3.82kB [00:00, 1.26MB/s]
Downloading: 1.79kB [00:00, 733kB/s]
Using custom data configuration default
Downloading and preparing dataset coqa/default (download: 55.40 MiB, generated: 18.35 MiB, post-processed: Unknown size, total: 73.75 MiB) to /Users/zhaofengw/.cache/huggingface/datasets/coqa/default/1.0.0/553ce70bfdcd15ff4b5f4abc4fc2f37137139cde1f58f4f60384a53a327716f0...
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 222/222 [00:00<00:00, 1.38MB/s]
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 222/222 [00:00<00:00, 1.32MB/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.91it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1117.44it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/zhaofengw/miniconda3/lib/python3.9/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/Users/zhaofengw/miniconda3/lib/python3.9/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/Users/zhaofengw/miniconda3/lib/python3.9/site-packages/datasets/builder.py", line 679, in _download_and_prepare
verify_checksums(
File "/Users/zhaofengw/miniconda3/lib/python3.9/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['https://nlp.stanford.edu/data/coqa/coqa-train-v1.0.json', 'https://nlp.stanford.edu/data/coqa/coqa-dev-v1.0.json']
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3269/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3269/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3268 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3268/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3268/comments | https://api.github.com/repos/huggingface/datasets/issues/3268/events | https://github.com/huggingface/datasets/issues/3268 | 1,052,992,681 | I_kwDODunzps4-w2Sp | 3,268 | Dataset viewer issue for 'liweili/c4_200m' | {
"login": "liliwei25",
"id": 22389228,
"node_id": "MDQ6VXNlcjIyMzg5MjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/22389228?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liliwei25",
"html_url": "https://github.com/liliwei25",
"followers_url": "https://api.github.com/users/liliwei25/followers",
"following_url": "https://api.github.com/users/liliwei25/following{/other_user}",
"gists_url": "https://api.github.com/users/liliwei25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liliwei25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liliwei25/subscriptions",
"organizations_url": "https://api.github.com/users/liliwei25/orgs",
"repos_url": "https://api.github.com/users/liliwei25/repos",
"events_url": "https://api.github.com/users/liliwei25/events{/privacy}",
"received_events_url": "https://api.github.com/users/liliwei25/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.c... | null | [
"Hi ! I think the issue comes from this [line](https://huggingface.co/datasets/liweili/c4_200m/blob/main/c4_200m.py#L87):\r\n```python\r\npath = filepath + \"/*.tsv*\"\r\n```\r\n\r\nYou can fix this by doing this instead:\r\n```python\r\npath = os.path.join(filepath, \"/*.tsv*\")\r\n```\r\n\r\nHere is why:\r\n\r\nL... | 2021-11-14T17:18:46 | 2021-12-21T10:25:20 | 2021-12-21T10:24:51 | NONE | null | null | null | ## Dataset viewer issue for '*liweili/c4_200m*'
**Link:** *[link to the dataset viewer page](https://huggingface.co/datasets/liweili/c4_200m)*
*Server Error*
```
Status code: 404
Exception: Status404Error
Message: Not found. Maybe the cache is missing, or maybe the ressource does not exist.
```
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3268/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3268/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3265/comments | https://api.github.com/repos/huggingface/datasets/issues/3265/events | https://github.com/huggingface/datasets/issues/3265 | 1,052,666,558 | I_kwDODunzps4-vmq- | 3,265 | Checksum error for kilt_task_wow | {
"login": "slyviacassell",
"id": 22296717,
"node_id": "MDQ6VXNlcjIyMjk2NzE3",
"avatar_url": "https://avatars.githubusercontent.com/u/22296717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/slyviacassell",
"html_url": "https://github.com/slyviacassell",
"followers_url": "https://api.github.com/users/slyviacassell/followers",
"following_url": "https://api.github.com/users/slyviacassell/following{/other_user}",
"gists_url": "https://api.github.com/users/slyviacassell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/slyviacassell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/slyviacassell/subscriptions",
"organizations_url": "https://api.github.com/users/slyviacassell/orgs",
"repos_url": "https://api.github.com/users/slyviacassell/repos",
"events_url": "https://api.github.com/users/slyviacassell/events{/privacy}",
"received_events_url": "https://api.github.com/users/slyviacassell/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Using `dataset = load_dataset(\"kilt_tasks\", \"wow\", ignore_verifications=True)` may fix it, but I do not think it is a elegant solution.",
"Hi @slyviacassell, thanks for reporting.\r\n\r\nYes, there is an issue with the checksum verification. I'm fixing it.\r\n\r\nAnd as you pointed out, in the meantime, you ... | 2021-11-13T12:04:17 | 2021-11-16T11:23:53 | 2021-11-16T11:21:58 | NONE | null | null | null | ## Describe the bug
Checksum failed when downloads kilt_tasks_wow. See error output for details.
## Steps to reproduce the bug
```python
import datasets
datasets.load_datasets('kilt_tasks','wow')
```
## Expected results
Download successful
## Actual results
```
Downloading and preparing dataset kilt_tasks/wow (download: 72.07 MiB, generated: 61.82 MiB, post-processed: Unknown size, total: 133.89 MiB) to /root/.cache/huggingface/datasets/kilt_tasks/wow/1.0.0/57dc8b2431e76637e0c6ef79689ca4af61ed3a330e2e0cd62c8971465a35db3a...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 5121.25it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1527.42it/s]
Traceback (most recent call last):
File "kilt_wow.py", line 30, in <module>
main()
File "kilt_wow.py", line 27, in main
train, dev, test = dataset.generate_k_shot_data(k=32, seed=seed, path="../data/")
File "/workspace/projects/CrossFit/tasks/fewshot_gym_dataset.py", line 79, in generate_k_shot_data
dataset = self.load_dataset()
File "kilt_wow.py", line 21, in load_dataset
return datasets.load_dataset('kilt_tasks','wow')
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 679, in _download_and_prepare
verify_checksums(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 40, in verify_checksums
raise NonMatchingChecksumError(error_msg + str(bad_urls))
datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
['http://dl.fbaipublicfiles.com/KILT/wow-train-kilt.jsonl', 'http://dl.fbaipublicfiles.com/KILT/wow-dev-kilt.jsonl']
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-4.15.0-161-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3265/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3265/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3264/comments | https://api.github.com/repos/huggingface/datasets/issues/3264/events | https://github.com/huggingface/datasets/issues/3264 | 1,052,663,513 | I_kwDODunzps4-vl7Z | 3,264 | Downloading URL change for WikiAuto Manual, jeopardy and definite_pronoun_resolution | {
"login": "slyviacassell",
"id": 22296717,
"node_id": "MDQ6VXNlcjIyMjk2NzE3",
"avatar_url": "https://avatars.githubusercontent.com/u/22296717?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/slyviacassell",
"html_url": "https://github.com/slyviacassell",
"followers_url": "https://api.github.com/users/slyviacassell/followers",
"following_url": "https://api.github.com/users/slyviacassell/following{/other_user}",
"gists_url": "https://api.github.com/users/slyviacassell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/slyviacassell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/slyviacassell/subscriptions",
"organizations_url": "https://api.github.com/users/slyviacassell/orgs",
"repos_url": "https://api.github.com/users/slyviacassell/repos",
"events_url": "https://api.github.com/users/slyviacassell/events{/privacy}",
"received_events_url": "https://api.github.com/users/slyviacassell/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"#take\r\nI am willing to fix this. Links can be replaced for WikiAuto Manual and jeopardy with new ones provided by authors.\r\n\r\nAs for the definite_pronoun_resolution URL, a certificate error seems to be preventing a download. I have the files on my local machine. I can include them in the dataset folder as th... | 2021-11-13T11:47:12 | 2022-06-01T17:38:16 | 2022-06-01T17:38:16 | NONE | null | null | null | ## Describe the bug
- WikiAuto Manual
The original manual datasets with the following downloading URL in this [repository](https://github.com/chaojiang06/wiki-auto) was [deleted](https://github.com/chaojiang06/wiki-auto/commit/0af9b066f2b4e02726fb8a9be49283c0ad25367f) by the author.
```
https://github.com/chaojiang06/wiki-auto/raw/master/wiki-manual/train.tsv
```
- jeopardy
The downloading URL for jeopardy may move from
```
http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
to
```
https://drive.google.com/file/d/0BwT5wj_P7BKXb2hfM3d2RHU1ckE/view?resourcekey=0-1abK4cJq-mqxFoSg86ieIg
```
- definite_pronoun_resolution
The following downloading URL for definite_pronoun_resolution cannot be reached for some reasons.
```
http://www.hlt.utdallas.edu/~vince/data/emnlp12/train.c.txt
```
## Steps to reproduce the bug
```python
import datasets
datasets.load_datasets('wiki_auto','manual')
datasets.load_datasets('jeopardy')
datasets.load_datasets('definite_pronoun_resolution')
```
## Expected results
Download successfully
## Actual results
- WikiAuto Manual
```
Downloading and preparing dataset wiki_auto/manual (download: 151.65 MiB, generated: 155.97 MiB, post-processed: Unknown size, total: 307.61 MiB) to /root/.cache/huggingface/datasets/wiki_auto/manual/1.0.0/5ffdd9fc62422d29bd02675fb9606f77c1251ee17169ac10b143ce07ef2f4db8...
0%| | 0/3 [00:00<?, ?it/s]Traceback (most recent call last):
File "wiki_auto.py", line 43, in <module>
main()
File "wiki_auto.py", line 40, in main
train, dev, test = dataset.generate_k_shot_data(k=16, seed=seed, path="../data/")
File "/workspace/projects/CrossFit/tasks/fewshot_gym_dataset.py", line 24, in generate_k_shot_data
dataset = self.load_dataset()
File "wiki_auto.py", line 34, in load_dataset
return datasets.load_dataset('wiki_auto', 'manual')
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/root/.cache/huggingface/modules/datasets_modules/datasets/wiki_auto/5ffdd9fc62422d29bd02675fb9606f77c1251ee17169ac10b143ce07ef2f4db8/wiki_auto.py", line 193, in _split_generators
data_dir = dl_manager.download_and_extract(my_urls)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 196, in download
downloaded_path_or_paths = map_nested(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 216, in map_nested
mapped = [
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 217, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 152, in _single_map_nested
return function(data_struct)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 295, in cached_path
output_path = get_from_cache(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 592, in get_from_cache
raise FileNotFoundError("Couldn't find file at {}".format(url))
FileNotFoundError: Couldn't find file at https://github.com/chaojiang06/wiki-auto/raw/master/wiki-manual/train.tsv
```
- jeopardy
```
Using custom data configuration default
Downloading and preparing dataset jeopardy/default (download: 12.13 MiB, generated: 34.46 MiB, post-processed: Unknown size, total: 46.59 MiB) to /root/.cache/huggingface/datasets/jeopardy/default/0.1.0/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810...
Traceback (most recent call last):
File "jeopardy.py", line 45, in <module>
main()
File "jeopardy.py", line 42, in main
train, dev, test = dataset.generate_k_shot_data(k=32, seed=seed, path="../data/")
File "/workspace/projects/CrossFit/tasks/fewshot_gym_dataset.py", line 79, in generate_k_shot_data
dataset = self.load_dataset()
File "jeopardy.py", line 36, in load_dataset
return datasets.load_dataset("jeopardy")
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/root/.cache/huggingface/modules/datasets_modules/datasets/jeopardy/25ee3e4a73755e637b8810f6493fd36e4523dea3ca8a540529d0a6e24c7f9810/jeopardy.py", line 72, in _split_generators
filepath = dl_manager.download_and_extract(_DATA_URL)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 196, in download
downloaded_path_or_paths = map_nested(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 206, in map_nested
return function(data_struct)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 295, in cached_path
output_path = get_from_cache(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://skeeto.s3.amazonaws.com/share/JEOPARDY_QUESTIONS1.json.gz
```
- definite_pronoun_resolution
```
Downloading and preparing dataset definite_pronoun_resolution/plain_text (download: 222.12 KiB, generated: 239.12 KiB, post-processed: Unknown size, total: 461.24 KiB) to /root/.cache/huggingface/datasets/definite_pronoun_resolution/plain_text/1.0.0/35a1dfd4fba4afb8ba226cbbb65ac7cef0dd3cf9302d8f803740f05d2f16ceff...
0%| | 0/2 [00:00<?, ?it/s]Traceback (most recent call last):
File "definite_pronoun_resolution.py", line 37, in <module>
main()
File "definite_pronoun_resolution.py", line 34, in main
train, dev, test = dataset.generate_k_shot_data(k=32, seed=seed, path="../data/")
File "/workspace/projects/CrossFit/tasks/fewshot_gym_dataset.py", line 79, in generate_k_shot_data
dataset = self.load_dataset()
File "definite_pronoun_resolution.py", line 28, in load_dataset
return datasets.load_dataset('definite_pronoun_resolution')
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/root/.cache/huggingface/modules/datasets_modules/datasets/definite_pronoun_resolution/35a1dfd4fba4afb8ba226cbbb65ac7cef0dd3cf9302d8f803740f05d2f16ceff/definite_pronoun_resolution.py", line 76, in _split_generators
files = dl_manager.download_and_extract(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 196, in download
downloaded_path_or_paths = map_nested(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 216, in map_nested
mapped = [
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 217, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 152, in _single_map_nested
return function(data_struct)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 295, in cached_path
output_path = get_from_cache(
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://www.hlt.utdallas.edu/~vince/data/emnlp12/train.c.txt
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-4.15.0-161-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3264/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3264/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3263/comments | https://api.github.com/repos/huggingface/datasets/issues/3263/events | https://github.com/huggingface/datasets/issues/3263 | 1,052,552,516 | I_kwDODunzps4-vK1E | 3,263 | FET DATA | {
"login": "FStell01",
"id": 90987031,
"node_id": "MDQ6VXNlcjkwOTg3MDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/90987031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FStell01",
"html_url": "https://github.com/FStell01",
"followers_url": "https://api.github.com/users/FStell01/followers",
"following_url": "https://api.github.com/users/FStell01/following{/other_user}",
"gists_url": "https://api.github.com/users/FStell01/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FStell01/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FStell01/subscriptions",
"organizations_url": "https://api.github.com/users/FStell01/orgs",
"repos_url": "https://api.github.com/users/FStell01/repos",
"events_url": "https://api.github.com/users/FStell01/events{/privacy}",
"received_events_url": "https://api.github.com/users/FStell01/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [] | 2021-11-13T05:46:06 | 2021-11-13T13:31:47 | 2021-11-13T13:31:47 | NONE | null | null | null | ## Adding a Dataset
- **Name:** *name of the dataset*
- **Description:** *short description of the dataset (or link to social media or blog post)*
- **Paper:** *link to the dataset paper if available*
- **Data:** *link to the Github repository or current dataset location*
- **Motivation:** *what are some good reasons to have this dataset*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md). | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3263/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3263/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3261 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3261/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3261/comments | https://api.github.com/repos/huggingface/datasets/issues/3261/events | https://github.com/huggingface/datasets/issues/3261 | 1,052,346,381 | I_kwDODunzps4-uYgN | 3,261 | Scifi_TV_Shows: Having trouble getting viewer to find appropriate files | {
"login": "lara-martin",
"id": 37913218,
"node_id": "MDQ6VXNlcjM3OTEzMjE4",
"avatar_url": "https://avatars.githubusercontent.com/u/37913218?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lara-martin",
"html_url": "https://github.com/lara-martin",
"followers_url": "https://api.github.com/users/lara-martin/followers",
"following_url": "https://api.github.com/users/lara-martin/following{/other_user}",
"gists_url": "https://api.github.com/users/lara-martin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lara-martin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lara-martin/subscriptions",
"organizations_url": "https://api.github.com/users/lara-martin/orgs",
"repos_url": "https://api.github.com/users/lara-martin/repos",
"events_url": "https://api.github.com/users/lara-martin/events{/privacy}",
"received_events_url": "https://api.github.com/users/lara-martin/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Hi ! I think this is because `iter_archive` doesn't support ZIP files yet. See https://github.com/huggingface/datasets/issues/3272\r\n\r\nYou can navigate into the archive this way instead:\r\n```python\r\n# in split_generators\r\ndata_dir = dl_manager.download_and_extract(url)\r\ntrain_filepath = os.path.join(dat... | 2021-11-12T19:25:19 | 2021-12-21T10:24:10 | 2021-12-21T10:24:10 | NONE | null | null | null | ## Dataset viewer issue for '*Science Fiction TV Show Plots Corpus (Scifi_TV_Shows)*'
**Link:** [link](https://huggingface.co/datasets/lara-martin/Scifi_TV_Shows)
I tried adding both a script (https://huggingface.co/datasets/lara-martin/Scifi_TV_Shows/blob/main/Scifi_TV_Shows.py) and some dummy examples (https://huggingface.co/datasets/lara-martin/Scifi_TV_Shows/tree/main/dummy), but the viewer still has a 404 error ("Not found. Maybe the cache is missing, or maybe the ressource does not exist."). I'm not sure what to try next. Thanks in advance!
Am I the one who added this dataset? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3261/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3261/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3258/comments | https://api.github.com/repos/huggingface/datasets/issues/3258/events | https://github.com/huggingface/datasets/issues/3258 | 1,052,188,195 | I_kwDODunzps4-tx4j | 3,258 | Reload dataset that was already downloaded with `load_from_disk` from cloud storage | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [] | 2021-11-12T17:14:59 | 2021-11-12T17:14:59 | null | MEMBER | null | null | null | `load_from_disk` downloads the dataset to a temporary directory without checking if the dataset has already been downloaded once.
It would be nice to have some sort of caching for datasets downloaded this way. This could leverage the fingerprint of the dataset that was saved in the `state.json` file. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3258/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3258/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3257 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3257/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3257/comments | https://api.github.com/repos/huggingface/datasets/issues/3257/events | https://github.com/huggingface/datasets/issues/3257 | 1,052,118,365 | I_kwDODunzps4-tg1d | 3,257 | Use f-strings for string formatting | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | {
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://api.github.com/users/Mehdi2402/followers",
"following_url": "https://api.github.com/users/Mehdi2402/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehdi2402/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehdi2402/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehdi2402/subscriptions",
"organizations_url": "https://api.github.com/users/Mehdi2402/orgs",
"repos_url": "https://api.github.com/users/Mehdi2402/repos",
"events_url": "https://api.github.com/users/Mehdi2402/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehdi2402/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Mehdi2402",
"id": 56029953,
"node_id": "MDQ6VXNlcjU2MDI5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/56029953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehdi2402",
"html_url": "https://github.com/Mehdi2402",
"followers_url": "https://a... | null | [
"Hi, I would be glad to help with this. Is there anyone else working on it?",
"Hi, I would be glad to work on this too.",
"#self-assign",
"Hi @Carlosbogo,\r\n\r\nwould you be interested in replacing the `.format` and `%` syntax with f-strings in the modules in the `datasets` directory since @Mehdi2402 has ope... | 2021-11-12T16:02:15 | 2021-11-17T16:18:38 | 2021-11-17T16:18:38 | CONTRIBUTOR | null | null | null | f-strings offer better readability/performance than `str.format` and `%`, so we should use them in all places in our codebase unless there is good reason to keep the older syntax.
> **NOTE FOR CONTRIBUTORS**: To avoid large PRs and possible merge conflicts, do 1-3 modules per PR. Also, feel free to ignore the files located under `datasets/*`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3257/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3257/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3255/comments | https://api.github.com/repos/huggingface/datasets/issues/3255/events | https://github.com/huggingface/datasets/issues/3255 | 1,051,783,129 | I_kwDODunzps4-sO_Z | 3,255 | SciELO dataset ConnectionError | {
"login": "WojciechKusa",
"id": 2575047,
"node_id": "MDQ6VXNlcjI1NzUwNDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2575047?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WojciechKusa",
"html_url": "https://github.com/WojciechKusa",
"followers_url": "https://api.github.com/users/WojciechKusa/followers",
"following_url": "https://api.github.com/users/WojciechKusa/following{/other_user}",
"gists_url": "https://api.github.com/users/WojciechKusa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WojciechKusa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WojciechKusa/subscriptions",
"organizations_url": "https://api.github.com/users/WojciechKusa/orgs",
"repos_url": "https://api.github.com/users/WojciechKusa/repos",
"events_url": "https://api.github.com/users/WojciechKusa/events{/privacy}",
"received_events_url": "https://api.github.com/users/WojciechKusa/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [] | 2021-11-12T09:57:14 | 2021-11-16T17:55:22 | 2021-11-16T17:55:22 | NONE | null | null | null | ## Describe the bug
I get `ConnectionError` when I am trying to load the SciELO dataset.
When I try the URL with `requests` I get:
```
>>> requests.head("https://ndownloader.figstatic.com/files/14019287")
<Response [302]>
```
And as far as I understand redirections in `datasets` are not supported for downloads.
https://github.com/huggingface/datasets/blob/807341d0db0728073ab605c812c67f927d148f38/datasets/scielo/scielo.py#L45
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("scielo", "en-es")
```
## Expected results
Download SciELO dataset and load Dataset object
## Actual results
```
Downloading and preparing dataset scielo/en-es (download: 21.90 MiB, generated: 68.45 MiB, post-processed: Unknown size, total: 90.35 MiB) to /Users/test/.cache/huggingface/datasets/scielo/en-es/1.0.0/7e05d55a20257efeb9925ff5de65bd4884fc6ddb6d765f1ea3e8860449d90e0e...
Traceback (most recent call last):
File "scielo.py", line 3, in <module>
dataset = load_dataset("scielo", "en-es")
File "../lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "../lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "../lib/python3.8/site-packages/datasets/builder.py", line 675, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/Users/test/.cache/huggingface/modules/datasets_modules/datasets/scielo/7e05d55a20257efeb9925ff5de65bd4884fc6ddb6d765f1ea3e8860449d90e0e/scielo.py", line 77, in _split_generators
data_dir = dl_manager.download_and_extract(_URLS[self.config.name])
File "../lib/python3.8/site-packages/datasets/utils/download_manager.py", line 284, in download_and_extract
return self.extract(self.download(url_or_urls))
File "../lib/python3.8/site-packages/datasets/utils/download_manager.py", line 196, in download
downloaded_path_or_paths = map_nested(
File "../lib/python3.8/site-packages/datasets/utils/py_utils.py", line 206, in map_nested
return function(data_struct)
File "../lib/python3.8/site-packages/datasets/utils/download_manager.py", line 217, in _download
return cached_path(url_or_filename, download_config=download_config)
File "../lib/python3.8/site-packages/datasets/utils/file_utils.py", line 295, in cached_path
output_path = get_from_cache(
File "../lib/python3.8/site-packages/datasets/utils/file_utils.py", line 594, in get_from_cache
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach https://ndownloader.figstatic.com/files/14019287
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.12
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3255/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3255/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3253 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3253/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3253/comments | https://api.github.com/repos/huggingface/datasets/issues/3253/events | https://github.com/huggingface/datasets/issues/3253 | 1,051,308,972 | I_kwDODunzps4-qbOs | 3,253 | `GeneratorBasedBuilder` does not support `None` values | {
"login": "pavel-lexyr",
"id": 69010336,
"node_id": "MDQ6VXNlcjY5MDEwMzM2",
"avatar_url": "https://avatars.githubusercontent.com/u/69010336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pavel-lexyr",
"html_url": "https://github.com/pavel-lexyr",
"followers_url": "https://api.github.com/users/pavel-lexyr/followers",
"following_url": "https://api.github.com/users/pavel-lexyr/following{/other_user}",
"gists_url": "https://api.github.com/users/pavel-lexyr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pavel-lexyr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pavel-lexyr/subscriptions",
"organizations_url": "https://api.github.com/users/pavel-lexyr/orgs",
"repos_url": "https://api.github.com/users/pavel-lexyr/repos",
"events_url": "https://api.github.com/users/pavel-lexyr/events{/privacy}",
"received_events_url": "https://api.github.com/users/pavel-lexyr/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthanks for reporting and providing a minimal reproducible example. \r\n\r\nThis line of the PR I've linked in our discussion on the Forum will add support for `None` values:\r\nhttps://github.com/huggingface/datasets/blob/a53de01842aac65c66a49b2439e18fa93ff73ceb/src/datasets/features/features.py#L835\r\... | 2021-11-11T19:51:21 | 2021-12-09T14:26:58 | 2021-12-09T14:26:58 | NONE | null | null | null | ## Describe the bug
`GeneratorBasedBuilder` does not support `None` values.
## Steps to reproduce the bug
See [this repository](https://github.com/pavel-lexyr/huggingface-datasets-bug-reproduction) for minimal reproduction.
## Expected results
Dataset is initialized with a `None` value in the `value` column.
## Actual results
```
Traceback (most recent call last):
File "main.py", line 3, in <module>
datasets.load_dataset("./bad-data")
File ".../datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File ".../datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File ".../datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File ".../datasets/builder.py", line 1103, in _prepare_split
example = self.info.features.encode_example(record)
File ".../datasets/features/features.py", line 1033, in encode_example
return encode_nested_example(self, example)
File ".../datasets/features/features.py", line 808, in encode_nested_example
return {
File ".../datasets/features/features.py", line 809, in <dictcomp>
k: encode_nested_example(sub_schema, sub_obj) for k, (sub_schema, sub_obj) in utils.zip_dict(schema, obj)
File ".../datasets/features/features.py", line 855, in encode_nested_example
return schema.encode_example(obj)
File ".../datasets/features/features.py", line 299, in encode_example
return float(value)
TypeError: float() argument must be a string or a number, not 'NoneType'
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-5.4.0-81-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 6.0.0 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3253/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3253/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3247 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3247/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3247/comments | https://api.github.com/repos/huggingface/datasets/issues/3247/events | https://github.com/huggingface/datasets/issues/3247 | 1,049,699,088 | I_kwDODunzps4-kSMQ | 3,247 | Loading big json dataset raises pyarrow.lib.ArrowNotImplementedError | {
"login": "maxzirps",
"id": 29249513,
"node_id": "MDQ6VXNlcjI5MjQ5NTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/29249513?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxzirps",
"html_url": "https://github.com/maxzirps",
"followers_url": "https://api.github.com/users/maxzirps/followers",
"following_url": "https://api.github.com/users/maxzirps/following{/other_user}",
"gists_url": "https://api.github.com/users/maxzirps/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxzirps/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxzirps/subscriptions",
"organizations_url": "https://api.github.com/users/maxzirps/orgs",
"repos_url": "https://api.github.com/users/maxzirps/repos",
"events_url": "https://api.github.com/users/maxzirps/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxzirps/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nthis issue is similar to https://github.com/huggingface/datasets/issues/3093, so you can either use the solution provided there or try to load the data in one chunk (you can control the chunk size by specifying the `chunksize` parameter (`int`) in `load_dataset`).\r\n\r\n@lhoestq Is this worth opening a... | 2021-11-10T11:17:59 | 2022-04-10T14:05:57 | 2022-04-10T14:05:57 | NONE | null | null | null | ## Describe the bug
When trying to create a dataset from a json file with around 25MB, the following error is raised `pyarrow.lib.ArrowNotImplementedError: Unsupported cast from struct<b: int64, c: int64> to struct using function cast_struct`
Splitting the big file into smaller ones and then loading it with the `load_dataset` method did also not work.
Creating a pandas dataframe from it and then loading it with `Dataset.from_pandas` works
## Steps to reproduce the bug
```python
load_dataset("json", data_files="test.json")
```
test.json ~25MB
```json
{"a": {"c": 8, "b": 5}}
{"a": {"b": 7, "c": 6}}
{"a": {"c": 8, "b": 5}}
{"a": {"b": 7, "c": 6}}
{"a": {"c": 8, "b": 5}}
...
```
working.json ~160bytes
```json
{"a": {"c": 8, "b": 5}}
{"a": {"b": 7, "c": 6}}
{"a": {"c": 8, "b": 5}}
{"a": {"b": 7, "c": 6}}
{"a": {"c": 8, "b": 5}}
```
## Expected results
It should load the dataset from the json file without error.
## Actual results
It raises Exception `pyarrow.lib.ArrowNotImplementedError: Unsupported cast from struct<b: int64, c: int64> to struct using function cast_struct`
```
Traceback (most recent call last):
File "/Users/m/workspace/xxx/project/main.py", line 60, in <module>
dataset = load_dataset("json", data_files="result.json")
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/datasets/load.py", line 1627, in load_dataset
builder_instance.download_and_prepare(
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/datasets/builder.py", line 1159, in _prepare_split
writer.write_table(table)
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/datasets/arrow_writer.py", line 428, in write_table
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1685, in pyarrow.lib.Table.from_arrays
File "pyarrow/table.pxi", line 630, in pyarrow.lib._sanitize_arrays
File "pyarrow/array.pxi", line 338, in pyarrow.lib.asarray
File "pyarrow/table.pxi", line 304, in pyarrow.lib.ChunkedArray.cast
File "/opt/homebrew/Caskroom/miniforge/base/envs/xxx/lib/python3.9/site-packages/pyarrow/compute.py", line 309, in cast
return call_function("cast", [arr], options)
File "pyarrow/_compute.pyx", line 528, in pyarrow._compute.call_function
File "pyarrow/_compute.pyx", line 327, in pyarrow._compute.Function.call
File "pyarrow/error.pxi", line 143, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 120, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Unsupported cast from struct<b: int64, c: int64> to struct using function cast_struct
```
## Environment info
- `datasets` version: 1.14.0
- Platform: macOS-12.0.1-arm64-arm-64bit
- Python version: 3.9.7
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3247/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3247/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3242/comments | https://api.github.com/repos/huggingface/datasets/issues/3242/events | https://github.com/huggingface/datasets/issues/3242 | 1,048,527,232 | I_kwDODunzps4-f0GA | 3,242 | Adding ANERcorp-CAMeLLab dataset | {
"login": "vitalyshalumov",
"id": 33824221,
"node_id": "MDQ6VXNlcjMzODI0MjIx",
"avatar_url": "https://avatars.githubusercontent.com/u/33824221?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vitalyshalumov",
"html_url": "https://github.com/vitalyshalumov",
"followers_url": "https://api.github.com/users/vitalyshalumov/followers",
"following_url": "https://api.github.com/users/vitalyshalumov/following{/other_user}",
"gists_url": "https://api.github.com/users/vitalyshalumov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vitalyshalumov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vitalyshalumov/subscriptions",
"organizations_url": "https://api.github.com/users/vitalyshalumov/orgs",
"repos_url": "https://api.github.com/users/vitalyshalumov/repos",
"events_url": "https://api.github.com/users/vitalyshalumov/events{/privacy}",
"received_events_url": "https://api.github.com/users/vitalyshalumov/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | open | false | null | [] | null | [
"Adding ANERcorp dataset\r\n\r\n## Adding a Dataset\r\n- **Name:** *ANERcorp-CAMeLLab*\r\n- **Description:** *Since its creation in 2008, the ANERcorp dataset (Benajiba & Rosso, 2008) has been a standard reference used by Arabic named entity recognition researchers around the world. However, over time, this dataset... | 2021-11-09T12:04:04 | 2021-11-09T12:41:15 | null | NONE | null | null | null | null | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3242/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3242/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3240 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3240/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3240/comments | https://api.github.com/repos/huggingface/datasets/issues/3240/events | https://github.com/huggingface/datasets/issues/3240 | 1,048,376,021 | I_kwDODunzps4-fPLV | 3,240 | Couldn't reach data file for disaster_response_messages | {
"login": "pandya6988",
"id": 81331791,
"node_id": "MDQ6VXNlcjgxMzMxNzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/81331791?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pandya6988",
"html_url": "https://github.com/pandya6988",
"followers_url": "https://api.github.com/users/pandya6988/followers",
"following_url": "https://api.github.com/users/pandya6988/following{/other_user}",
"gists_url": "https://api.github.com/users/pandya6988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pandya6988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pandya6988/subscriptions",
"organizations_url": "https://api.github.com/users/pandya6988/orgs",
"repos_url": "https://api.github.com/users/pandya6988/repos",
"events_url": "https://api.github.com/users/pandya6988/events{/privacy}",
"received_events_url": "https://api.github.com/users/pandya6988/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"It looks like the dataset isn't available anymore on appen.com\r\n\r\nThe CSV files appear to still be available at https://www.kaggle.com/landlord/multilingual-disaster-response-messages though. It says that the data are under the CC0 license so I guess we can host the dataset elsewhere instead ?"
] | 2021-11-09T09:26:42 | 2021-12-14T14:38:29 | 2021-12-14T14:38:29 | NONE | null | null | null | ## Describe the bug
Following command gives an ConnectionError.
## Steps to reproduce the bug
```python
disaster = load_dataset('disaster_response_messages')
```
## Error
```
ConnectionError: Couldn't reach https://datasets.appen.com/appen_datasets/disaster_response_data/disaster_response_messages_training.csv
```
## Expected results
It should load dataset without an error
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version:
- Platform: Google Colab
- Python version: 3.7
- PyArrow version:
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3240/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3240/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3239 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3239/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3239/comments | https://api.github.com/repos/huggingface/datasets/issues/3239/events | https://github.com/huggingface/datasets/issues/3239 | 1,048,360,232 | I_kwDODunzps4-fLUo | 3,239 | Inconsistent performance of the "arabic_billion_words" dataset | {
"login": "vitalyshalumov",
"id": 33824221,
"node_id": "MDQ6VXNlcjMzODI0MjIx",
"avatar_url": "https://avatars.githubusercontent.com/u/33824221?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vitalyshalumov",
"html_url": "https://github.com/vitalyshalumov",
"followers_url": "https://api.github.com/users/vitalyshalumov/followers",
"following_url": "https://api.github.com/users/vitalyshalumov/following{/other_user}",
"gists_url": "https://api.github.com/users/vitalyshalumov/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vitalyshalumov/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vitalyshalumov/subscriptions",
"organizations_url": "https://api.github.com/users/vitalyshalumov/orgs",
"repos_url": "https://api.github.com/users/vitalyshalumov/repos",
"events_url": "https://api.github.com/users/vitalyshalumov/events{/privacy}",
"received_events_url": "https://api.github.com/users/vitalyshalumov/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 2021-11-09T09:11:00 | 2021-11-09T09:11:00 | null | NONE | null | null | null | ## Describe the bug
When downloaded from macine 1 the dataset is downloaded and parsed correctly.
When downloaded from machine two (which has a different cache directory),
the following script:
import datasets
from datasets import load_dataset
raw_dataset_elkhair_1 = load_dataset('arabic_billion_words', 'Alittihad', split="train",download_mode='force_redownload')
gives the following error:
**Downloading and preparing dataset arabic_billion_words/Alittihad (download: 332.13 MiB, generated: 1.49 GiB, post-processed: Unknown size, total: 1.82 GiB) to /root/.cache/huggingface/datasets/arabic_billion_words/Alittihad/1.1.0/687a1f963284c8a766558661375ea8f7ab3fa3633f8cd9c9f42a53ebe83bfe17...
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 348M/348M [00:24<00:00, 14.0MB/s]
Traceback (most recent call last):
File ".../why_mismatch.py", line 3, in <module>
File "/opt/conda/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/opt/conda/lib/python3.8/site-packages/datasets/builder.py", line 709, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "/opt/conda/lib/python3.8/site-packages/datasets/utils/info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=1601790302, num_examples=349342, dataset_name='arabic_billion_words'), 'recorded': SplitInfo(name='train', num_bytes=0, num_examples=0, dataset_name='arabic_billion_words')}]**
Note that the package versions of datasets (1.15.1) and rarfile (4.0) are identical.
## Steps to reproduce the bug
import datasets
from datasets import load_dataset
raw_dataset_elkhair_1 = load_dataset('arabic_billion_words', 'Alittihad', split="train",download_mode='force_redownload')
# Sample code to reproduce the bug
## Expected results
Downloading and preparing dataset arabic_billion_words/Alittihad (download: 332.13 MiB, generated: 1.49 GiB, post-processed: Unknown size, total: 1.82 GiB) to .../.cache/huggingface/datasets/arabic_billion_words/Alittihad/1.1.0/687a1f963284c8a766558661375ea8f7ab3fa3633f8cd9c9f42a53ebe83bfe17...
Downloading: 100%|███████████████████████████| 348M/348M [00:22<00:00, 15.8MB/s]
Dataset arabic_billion_words downloaded and prepared to .../.cache/huggingface/datasets/arabic_billion_words/Alittihad/1.1.0/687a1f963284c8a766558661375ea8f7ab3fa3633f8cd9c9f42a53ebe83bfe17. Subsequent calls will reuse this data.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
Machine 1:
- `datasets` version: 1.15.1
- Platform: Linux-5.8.0-63-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyArrow version: 4.0.1
Machine 2 (the bugged one)
- `datasets` version: 1.15.1
- Platform: Linux-4.4.0-210-generic-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3239/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3239/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3238 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3238/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3238/comments | https://api.github.com/repos/huggingface/datasets/issues/3238/events | https://github.com/huggingface/datasets/issues/3238 | 1,048,226,086 | I_kwDODunzps4-eqkm | 3,238 | Reuters21578 Couldn't reach | {
"login": "TingNLP",
"id": 54096137,
"node_id": "MDQ6VXNlcjU0MDk2MTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/54096137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TingNLP",
"html_url": "https://github.com/TingNLP",
"followers_url": "https://api.github.com/users/TingNLP/followers",
"following_url": "https://api.github.com/users/TingNLP/following{/other_user}",
"gists_url": "https://api.github.com/users/TingNLP/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TingNLP/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TingNLP/subscriptions",
"organizations_url": "https://api.github.com/users/TingNLP/orgs",
"repos_url": "https://api.github.com/users/TingNLP/repos",
"events_url": "https://api.github.com/users/TingNLP/events{/privacy}",
"received_events_url": "https://api.github.com/users/TingNLP/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"Hi ! The URL works fine on my side today, could you try again ?",
"thank you @lhoestq \r\nit works"
] | 2021-11-09T06:08:56 | 2021-11-11T00:02:57 | 2021-11-11T00:02:57 | NONE | null | null | null | ``## Adding a Dataset
- **Name:** *Reuters21578*
- **Description:** *ConnectionError: Couldn't reach https://kdd.ics.uci.edu/databases/reuters21578/reuters21578.tar.gz*
- **Data:** *https://huggingface.co/datasets/reuters21578*
`from datasets import load_dataset`
`dataset = load_dataset("reuters21578", 'ModLewis')`
ConnectionError: Couldn't reach https://kdd.ics.uci.edu/databases/reuters21578/reuters21578.tar.gz
And I try to request the link as follow:
`import requests`
`requests.head('https://kdd.ics.uci.edu/databases/reuters21578/reuters21578.tar.gz')`
SSLError: HTTPSConnectionPool(host='kdd.ics.uci.edu', port=443): Max retries exceeded with url: /databases/reuters21578/reuters21578.tar.gz (Caused by SSLError(SSLError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:852)'),))
This problem likes #575
What should I do ?
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3238/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3238/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3237 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3237/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3237/comments | https://api.github.com/repos/huggingface/datasets/issues/3237/events | https://github.com/huggingface/datasets/issues/3237 | 1,048,165,525 | I_kwDODunzps4-ebyV | 3,237 | wikitext description wrong | {
"login": "hongyuanmei",
"id": 19693633,
"node_id": "MDQ6VXNlcjE5NjkzNjMz",
"avatar_url": "https://avatars.githubusercontent.com/u/19693633?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hongyuanmei",
"html_url": "https://github.com/hongyuanmei",
"followers_url": "https://api.github.com/users/hongyuanmei/followers",
"following_url": "https://api.github.com/users/hongyuanmei/following{/other_user}",
"gists_url": "https://api.github.com/users/hongyuanmei/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hongyuanmei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hongyuanmei/subscriptions",
"organizations_url": "https://api.github.com/users/hongyuanmei/orgs",
"repos_url": "https://api.github.com/users/hongyuanmei/repos",
"events_url": "https://api.github.com/users/hongyuanmei/events{/privacy}",
"received_events_url": "https://api.github.com/users/hongyuanmei/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @hongyuanmei, thanks for reporting.\r\n\r\nI'm fixing it.",
"Duplicate of:\r\n- #795"
] | 2021-11-09T04:06:52 | 2022-02-14T15:45:11 | 2021-11-09T13:49:28 | NONE | null | null | null | ## Describe the bug
Descriptions of the wikitext datasests are wrong.
## Steps to reproduce the bug
Please see: https://github.com/huggingface/datasets/blob/f6dcafce996f39b6a4bbe3a9833287346f4a4b68/datasets/wikitext/wikitext.py#L50
## Expected results
The descriptions for raw-v1 and v1 should be switched. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3237/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3237/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3236 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3236/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3236/comments | https://api.github.com/repos/huggingface/datasets/issues/3236/events | https://github.com/huggingface/datasets/issues/3236 | 1,048,026,358 | I_kwDODunzps4-d5z2 | 3,236 | Loading of datasets changed in #3110 returns no examples | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "https://api.github.com/users/eladsegal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladsegal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladsegal/subscriptions",
"organizations_url": "https://api.github.com/users/eladsegal/orgs",
"repos_url": "https://api.github.com/users/eladsegal/repos",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladsegal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"Hi @eladsegal, thanks for reporting.\r\n\r\nI am sorry, but I can't reproduce the bug:\r\n```\r\nIn [1]: from datasets import load_dataset\r\n\r\nIn [2]: ds = load_dataset(\"qasper\")\r\nDownloading: 5.11kB [00:00, ?B/s]\r\nDownloading and preparing dataset qasper/qasper (download: 9.88 MiB, generated: 35.11 MiB, ... | 2021-11-08T23:29:46 | 2021-11-09T16:46:05 | 2021-11-09T16:45:47 | CONTRIBUTOR | null | null | null | ## Describe the bug
Loading of datasets changed in https://github.com/huggingface/datasets/pull/3110 returns no examples:
```python
DatasetDict({
train: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 0
})
validation: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 0
})
})
```
## Steps to reproduce the bug
Load any of the datasets that were changed in https://github.com/huggingface/datasets/pull/3110:
```python
from datasets import load_dataset
load_dataset("qasper")
# The problem only started with the commit of #3110
load_dataset("qasper", revision="b6469baa22c174b3906c631802a7016fedea6780")
```
## Expected results
```python
DatasetDict({
train: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 888
})
validation: Dataset({
features: ['id', 'title', 'abstract', 'full_text', 'qas'],
num_rows: 281
})
})
```
Which can be received when specifying revision of the commit before https://github.com/huggingface/datasets/pull/3110:
```python
from datasets import load_dataset
load_dataset("qasper", revision="acfe2abda1ca79f0ce5c1896aa83b4b78af76b7d")
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.2.dev0 (master)
- Python version: 3.8.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3236/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3236/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3232/comments | https://api.github.com/repos/huggingface/datasets/issues/3232/events | https://github.com/huggingface/datasets/issues/3232 | 1,047,361,573 | I_kwDODunzps4-bXgl | 3,232 | The Xsum datasets seems not able to download. | {
"login": "FYYFU",
"id": 37999885,
"node_id": "MDQ6VXNlcjM3OTk5ODg1",
"avatar_url": "https://avatars.githubusercontent.com/u/37999885?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/FYYFU",
"html_url": "https://github.com/FYYFU",
"followers_url": "https://api.github.com/users/FYYFU/followers",
"following_url": "https://api.github.com/users/FYYFU/following{/other_user}",
"gists_url": "https://api.github.com/users/FYYFU/gists{/gist_id}",
"starred_url": "https://api.github.com/users/FYYFU/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/FYYFU/subscriptions",
"organizations_url": "https://api.github.com/users/FYYFU/orgs",
"repos_url": "https://api.github.com/users/FYYFU/repos",
"events_url": "https://api.github.com/users/FYYFU/events{/privacy}",
"received_events_url": "https://api.github.com/users/FYYFU/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi ! On my side the URL is working fine, could you try again ?",
"> Hi ! On my side the URL is working fine, could you try again ?\r\n\r\nI try it again and cannot download the file (might because of my location). Could you please provide another download link(such as google drive)? :>",
"I don't know other ... | 2021-11-08T11:58:54 | 2021-11-09T15:07:16 | 2021-11-09T15:07:16 | NONE | null | null | null | ## Describe the bug
The download Link of the Xsum dataset provided in the repository is [Link](http://bollin.inf.ed.ac.uk/public/direct/XSUM-EMNLP18-Summary-Data-Original.tar.gz). It seems not able to download.
## Steps to reproduce the bug
```python
load_dataset('xsum')
```
## Actual results
``` python
raise ConnectionError("Couldn't reach {}".format(url))
ConnectionError: Couldn't reach http://bollin.inf.ed.ac.uk/public/direct/XSUM-EMNLP18-Summary-Data-Original.tar.gz
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3232/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3232/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3227/comments | https://api.github.com/repos/huggingface/datasets/issues/3227/events | https://github.com/huggingface/datasets/issues/3227 | 1,046,667,845 | I_kwDODunzps4-YuJF | 3,227 | Error in `Json(datasets.ArrowBasedBuilder)` class | {
"login": "JunShern",
"id": 7796965,
"node_id": "MDQ6VXNlcjc3OTY5NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7796965?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JunShern",
"html_url": "https://github.com/JunShern",
"followers_url": "https://api.github.com/users/JunShern/followers",
"following_url": "https://api.github.com/users/JunShern/following{/other_user}",
"gists_url": "https://api.github.com/users/JunShern/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JunShern/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JunShern/subscriptions",
"organizations_url": "https://api.github.com/users/JunShern/orgs",
"repos_url": "https://api.github.com/users/JunShern/repos",
"events_url": "https://api.github.com/users/JunShern/events{/privacy}",
"received_events_url": "https://api.github.com/users/JunShern/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"I have additionally identified the source of the error, being that [this condition](https://github.com/huggingface/datasets/blob/fc46bba66ba4f432cc10501c16a677112e13984c/src/datasets/packaged_modules/json/json.py#L124-L126) in the file\r\n`python3.8/site-packages/datasets/packaged_modules/json/json.py` is not bein... | 2021-11-07T05:50:32 | 2021-11-09T19:09:15 | 2021-11-09T19:09:15 | NONE | null | null | null | ## Describe the bug
When a json file contains a `text` field that is larger than the block_size, the JSON dataset builder fails.
## Steps to reproduce the bug
Create a folder that contains the following:
```
.
├── testdata
│ └── mydata.json
└── test.py
```
Please download [this file](https://github.com/huggingface/datasets/files/7491797/mydata.txt) as `mydata.json`. (The error does not occur in JSON files with shorter text, but it is reproducible when the text is long as in the file I provide)
:exclamation: :exclamation: GitHub doesn't allow me to upload JSON so this file is a TXT, and you should rename it to `.json`!
`test.py` simply contains:
```python
from datasets import load_dataset
my_dataset = load_dataset("testdata")
```
To reproduce the error, simply run
```
python test.py
```
## Expected results
The data should load correctly without error.
## Actual results
The dataset builder fails with:
```
Using custom data configuration testdata-d490389b8ab4fd82
Downloading and preparing dataset json/testdata to /home/junshern.chan/.cache/huggingface/datasets/json/testdata-d490389b8ab4fd82/0.0.0/3333a8af0db9764dfcff43a42ff26228f0f2e267f0d8a0a294452d188beadb34...
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2264.74it/s]
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 447.01it/s]
Failed to read file '/home/junshern.chan/hf-json-bug/testdata/mydata.json' with error <class 'pyarrow.lib.ArrowInvalid'>: JSON parse error: Missing a name for object member. in row 0
Traceback (most recent call last):
File "test.py", line 28, in <module>
my_dataset = load_dataset("testdata")
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/datasets/builder.py", line 1156, in _prepare_split
for key, table in utils.tqdm(
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/tqdm/std.py", line 1168, in __iter__
for obj in iterable:
File "/home/junshern.chan/.casio/miniconda/envs/hf-json-bug/lib/python3.8/site-packages/datasets/packaged_modules/json/json.py", line 146, in _generate_tables
raise ValueError(
ValueError: Not able to read records in the JSON file at /home/junshern.chan/hf-json-bug/testdata/mydata.json. You should probably indicate the field of the JSON file containing your records. This JSON file contain the following fields: ['text']. Select the correct one and provide it as `field='XXX'` to the dataset loading method.
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.15.1
- Platform: Linux-5.8.0-63-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3227/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3227/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3220 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3220/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3220/comments | https://api.github.com/repos/huggingface/datasets/issues/3220/events | https://github.com/huggingface/datasets/issues/3220 | 1,045,549,029 | I_kwDODunzps4-Uc_l | 3,220 | Add documentation about dataset viewer feature | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_k... | open | false | null | [] | null | [
"In particular, include this somewhere in the docs: https://huggingface.co/docs/hub/datasets-viewer#access-the-parquet-files\r\n\r\nSee https://github.com/huggingface/hub-docs/issues/563"
] | 2021-11-05T08:11:19 | 2023-09-25T11:48:38 | null | MEMBER | null | null | null | Add to the docs more details about the dataset viewer feature in the Hub.
CC: @julien-c
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3220/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3219 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3219/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3219/comments | https://api.github.com/repos/huggingface/datasets/issues/3219/events | https://github.com/huggingface/datasets/issues/3219 | 1,045,095,000 | I_kwDODunzps4-SuJY | 3,219 | Eventual Invalid Token Error at setup of private datasets | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-11-04T18:50:45 | 2021-11-08T13:23:06 | 2021-11-08T08:59:43 | MEMBER | null | null | null | ## Describe the bug
From time to time, there appear Invalid Token errors with private datasets:
- https://app.circleci.com/pipelines/github/huggingface/datasets/8520/workflows/d44629f2-4749-40f8-a657-50931d0b3434/jobs/52534
```
____________ ERROR at setup of test_load_streaming_private_dataset _____________
ValueError: Invalid token passed!
____ ERROR at setup of test_load_streaming_private_dataset_with_zipped_data ____
ValueError: Invalid token passed!
=========================== short test summary info ============================
ERROR tests/test_load.py::test_load_streaming_private_dataset - ValueError: I...
ERROR tests/test_load.py::test_load_streaming_private_dataset_with_zipped_data
```
- https://app.circleci.com/pipelines/github/huggingface/datasets/8557/workflows/a8383181-ba6d-4487-9d0a-f750b6dcb936/jobs/52763
```
____ ERROR at setup of test_load_streaming_private_dataset_with_zipped_data ____
[gw1] linux -- Python 3.6.15 /home/circleci/.pyenv/versions/3.6.15/bin/python3.6
hf_api = <huggingface_hub.hf_api.HfApi object at 0x7f4899bab908>
hf_token = 'vgNbyuaLNEBuGbgCEtSBCOcPjZnngJufHkTaZvHwkXKGkHpjBPwmLQuJVXRxBuaRzNlGjlMpYRPbthfHPFWXaaEDTLiqTTecYENxukRYVAAdpeApIUPxcgsowadkTkPj'
zip_csv_path = PosixPath('/tmp/pytest-of-circleci/pytest-0/popen-gw1/data16/dataset.csv.zip')
@pytest.fixture(scope="session")
def hf_private_dataset_repo_zipped_txt_data_(hf_api: HfApi, hf_token, zip_csv_path):
repo_name = "repo_zipped_txt_data-{}".format(int(time.time() * 10e3))
hf_api.create_repo(token=hf_token, name=repo_name, repo_type="dataset", private=True)
repo_id = f"{USER}/{repo_name}"
hf_api.upload_file(
token=hf_token,
path_or_fileobj=str(zip_csv_path),
path_in_repo="data.zip",
repo_id=repo_id,
> repo_type="dataset",
)
tests/hub_fixtures.py:68:
...
ValueError: Invalid token passed!
=========================== short test summary info ============================
ERROR tests/test_load.py::test_load_streaming_private_dataset_with_zipped_data
```
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3219/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3217 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3217/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3217/comments | https://api.github.com/repos/huggingface/datasets/issues/3217/events | https://github.com/huggingface/datasets/issues/3217 | 1,045,029,710 | I_kwDODunzps4-SeNO | 3,217 | Fix code quality bug in riddle_sense dataset | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"To give more context: https://github.com/psf/black/issues/318. `black` doesn't treat this as a bug, but `flake8` does. \r\n"
] | 2021-11-04T17:40:32 | 2021-11-04T17:50:02 | 2021-11-04T17:50:02 | MEMBER | null | null | null | ## Describe the bug
```
datasets/riddle_sense/riddle_sense.py:36:21: W291 trailing whitespace
``` | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3217/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3214 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3214/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3214/comments | https://api.github.com/repos/huggingface/datasets/issues/3214/events | https://github.com/huggingface/datasets/issues/3214 | 1,044,924,050 | I_kwDODunzps4-SEaS | 3,214 | Add ACAV100M Dataset | {
"login": "nateraw",
"id": 32437151,
"node_id": "MDQ6VXNlcjMyNDM3MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nateraw",
"html_url": "https://github.com/nateraw",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https://api.github.com/users/nateraw/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nateraw/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nateraw/subscriptions",
"organizations_url": "https://api.github.com/users/nateraw/orgs",
"repos_url": "https://api.github.com/users/nateraw/repos",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"received_events_url": "https://api.github.com/users/nateraw/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
},
{
"id": 3608941089,
... | open | false | null | [] | null | [] | 2021-11-04T15:59:58 | 2021-12-08T12:00:30 | null | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** *ACAV100M*
- **Description:** *contains 100 million videos with high audio-visual correspondence, ideal for self-supervised video representation learning.*
- **Paper:** *https://arxiv.org/abs/2101.10803*
- **Data:** *https://github.com/sangho-vision/acav100m*
- **Motivation:** *The largest dataset (to date) for audio-visual learning.*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3214/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3214/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3212 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3212/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3212/comments | https://api.github.com/repos/huggingface/datasets/issues/3212/events | https://github.com/huggingface/datasets/issues/3212 | 1,044,640,967 | I_kwDODunzps4-Q_TH | 3,212 | Sort files before loading | {
"login": "lvwerra",
"id": 8264887,
"node_id": "MDQ6VXNlcjgyNjQ4ODc=",
"avatar_url": "https://avatars.githubusercontent.com/u/8264887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lvwerra",
"html_url": "https://github.com/lvwerra",
"followers_url": "https://api.github.com/users/lvwerra/followers",
"following_url": "https://api.github.com/users/lvwerra/following{/other_user}",
"gists_url": "https://api.github.com/users/lvwerra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lvwerra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lvwerra/subscriptions",
"organizations_url": "https://api.github.com/users/lvwerra/orgs",
"repos_url": "https://api.github.com/users/lvwerra/repos",
"events_url": "https://api.github.com/users/lvwerra/events{/privacy}",
"received_events_url": "https://api.github.com/users/lvwerra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"This will be fixed by https://github.com/huggingface/datasets/pull/3221"
] | 2021-11-04T11:08:31 | 2021-11-05T17:49:58 | 2021-11-05T17:49:58 | MEMBER | null | null | null | When loading a dataset that consists of several files (e.g. `my_data/data_001.json`, `my_data/data_002.json` etc.) they are not loaded in order when using `load_dataset("my_data")`.
This could lead to counter-intuitive results if, for example, the data files are sorted by date or similar since they would appear in different order in the `Dataset`.
The straightforward solution is to sort the list of files alphabetically before loading them.
cc @lhoestq
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3212/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3212/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3210 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3210/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3210/comments | https://api.github.com/repos/huggingface/datasets/issues/3210/events | https://github.com/huggingface/datasets/issues/3210 | 1,044,611,471 | I_kwDODunzps4-Q4GP | 3,210 | ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py | {
"login": "xiuzhilu",
"id": 28184983,
"node_id": "MDQ6VXNlcjI4MTg0OTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/28184983?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/xiuzhilu",
"html_url": "https://github.com/xiuzhilu",
"followers_url": "https://api.github.com/users/xiuzhilu/followers",
"following_url": "https://api.github.com/users/xiuzhilu/following{/other_user}",
"gists_url": "https://api.github.com/users/xiuzhilu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/xiuzhilu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/xiuzhilu/subscriptions",
"organizations_url": "https://api.github.com/users/xiuzhilu/orgs",
"repos_url": "https://api.github.com/users/xiuzhilu/repos",
"events_url": "https://api.github.com/users/xiuzhilu/events{/privacy}",
"received_events_url": "https://api.github.com/users/xiuzhilu/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067388877,
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug",
"name": "dataset bug",
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library"
}
] | closed | false | null | [] | null | [
"Hi ! Do you have some kind of proxy in your browser that gives you access to internet ?\r\n\r\nMaybe you're having this error because you don't have access to this URL from python ?",
"Hi,do you fixed this error?\r\nI still have this issue when use \"use_auth_token=True\"",
"You don't need authentication to ac... | 2021-11-04T10:47:26 | 2022-03-30T08:26:35 | 2022-03-30T08:26:35 | NONE | null | null | null | when I use python examples/pytorch/translation/run_translation.py --model_name_or_path examples/pytorch/translation/opus-mt-en-ro --do_train --do_eval --source_lang en --target_lang ro --dataset_name wmt16 --dataset_config_name ro-en --output_dir /tmp/tst-translation --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate to finetune translation model on huggingface, I get the issue"ConnectionError: Couldn't reach https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py".But I can open the https://raw.githubusercontent.com/huggingface/datasets/1.15.1/datasets/wmt16/wmt16.py by using website. What should I do to solve the issue? | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3210/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3209/comments | https://api.github.com/repos/huggingface/datasets/issues/3209/events | https://github.com/huggingface/datasets/issues/3209 | 1,044,505,771 | I_kwDODunzps4-QeSr | 3,209 | Unpin keras once TF fixes its release | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [] | 2021-11-04T09:15:32 | 2021-11-05T10:57:37 | 2021-11-05T10:57:37 | MEMBER | null | null | null | Related to:
- #3208 | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3209/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3207/comments | https://api.github.com/repos/huggingface/datasets/issues/3207/events | https://github.com/huggingface/datasets/issues/3207 | 1,044,496,389 | I_kwDODunzps4-QcAF | 3,207 | CI error: Another metric with the same name already exists in Keras 2.7.0 | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-11-04T09:04:11 | 2021-11-04T09:30:54 | 2021-11-04T09:30:54 | MEMBER | null | null | null | ## Describe the bug
Release of TensorFlow 2.7.0 contains an incompatibility with Keras. See:
- keras-team/keras#15579
This breaks our CI test suite: https://app.circleci.com/pipelines/github/huggingface/datasets/8493/workflows/055c7ae2-43bc-49b4-9f11-8fc71f35a25c/jobs/52363
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3207/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3204 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3204/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3204/comments | https://api.github.com/repos/huggingface/datasets/issues/3204/events | https://github.com/huggingface/datasets/issues/3204 | 1,043,707,307 | I_kwDODunzps4-NbWr | 3,204 | FileNotFoundError for TupleIE dataste | {
"login": "arda-vianai",
"id": 75334917,
"node_id": "MDQ6VXNlcjc1MzM0OTE3",
"avatar_url": "https://avatars.githubusercontent.com/u/75334917?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arda-vianai",
"html_url": "https://github.com/arda-vianai",
"followers_url": "https://api.github.com/users/arda-vianai/followers",
"following_url": "https://api.github.com/users/arda-vianai/following{/other_user}",
"gists_url": "https://api.github.com/users/arda-vianai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arda-vianai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arda-vianai/subscriptions",
"organizations_url": "https://api.github.com/users/arda-vianai/orgs",
"repos_url": "https://api.github.com/users/arda-vianai/repos",
"events_url": "https://api.github.com/users/arda-vianai/events{/privacy}",
"received_events_url": "https://api.github.com/users/arda-vianai/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"@mariosasko @lhoestq Could you give me an update on how to load the dataset after the fix?\r\nThanks.",
"Hi @arda-vianai,\r\n\r\nfirst, you can try:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('tuple_ie', 'all', revision=\"master\")\r\n```\r\nIf this doesn't work, your version of `datasets... | 2021-11-03T14:56:55 | 2021-11-05T15:51:15 | 2021-11-05T14:16:05 | NONE | null | null | null | Hi,
`dataset = datasets.load_dataset('tuple_ie', 'all')`
returns a FileNotFound error. Is the data not available?
Many thanks.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3204/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3202/comments | https://api.github.com/repos/huggingface/datasets/issues/3202/events | https://github.com/huggingface/datasets/issues/3202 | 1,043,213,660 | I_kwDODunzps4-Li1c | 3,202 | Add mIoU metric | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Resolved via https://github.com/huggingface/datasets/pull/3745."
] | 2021-11-03T08:42:32 | 2022-06-01T17:39:05 | 2022-06-01T17:39:04 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Recently, some semantic segmentation models were added to HuggingFace Transformers, including [SegFormer](https://huggingface.co/transformers/model_doc/segformer.html) and [BEiT](https://huggingface.co/transformers/model_doc/beit.html).
Semantic segmentation (which is the task of labeling every pixel of an image with a corresponding class) is typically evaluated using the Mean Intersection and Union (mIoU). Together with the upcoming Image Feature, adding this metric could be very handy when creating example scripts to fine-tune any Transformer-based model on a semantic segmentation dataset.
An implementation can be found [here](https://github.com/open-mmlab/mmsegmentation/blob/504965184c3e6bc9ec43af54237129ef21981a5f/mmseg/core/evaluation/metrics.py#L132) for instance.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3202/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3202/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3201 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3201/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3201/comments | https://api.github.com/repos/huggingface/datasets/issues/3201/events | https://github.com/huggingface/datasets/issues/3201 | 1,043,209,142 | I_kwDODunzps4-Lhu2 | 3,201 | Add GSM8K dataset | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2067376369,
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request",
"name": "dataset request",
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset"
}
] | closed | false | null | [] | null | [
"Closed via https://github.com/huggingface/datasets/pull/4103"
] | 2021-11-03T08:36:44 | 2022-04-13T11:56:12 | 2022-04-13T11:56:11 | CONTRIBUTOR | null | null | null | ## Adding a Dataset
- **Name:** GSM8K (short for Grade School Math 8k)
- **Description:** GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers.
- **Paper:** https://openai.com/blog/grade-school-math/
- **Data:** https://github.com/openai/grade-school-math
- **Motivation:** The dataset is useful to investigate the reasoning abilities of large Transformer models, such as GPT-3.
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3201/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3193 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3193/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3193/comments | https://api.github.com/repos/huggingface/datasets/issues/3193/events | https://github.com/huggingface/datasets/issues/3193 | 1,041,971,117 | I_kwDODunzps4-Gzet | 3,193 | Update link to datasets-tagging app | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-11-02T07:39:59 | 2021-11-08T10:36:22 | 2021-11-08T10:36:22 | MEMBER | null | null | null | Once datasets-tagging has been transferred to Spaces:
- huggingface/datasets-tagging#22
We should update the link in Datasets. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3193/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3192 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3192/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3192/comments | https://api.github.com/repos/huggingface/datasets/issues/3192/events | https://github.com/huggingface/datasets/issues/3192 | 1,041,308,086 | I_kwDODunzps4-ERm2 | 3,192 | Multiprocessing filter/map (tests) not working on Windows | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | open | false | null | [] | null | [] | 2021-11-01T15:36:08 | 2021-11-01T15:57:03 | null | CONTRIBUTOR | null | null | null | While running the tests, I found that the multiprocessing examples fail on Windows, or rather they do not complete: they cause a deadlock. I haven't dug deep into it, but they do not seem to work as-is. I currently have no time to tests this in detail but at least the tests seem not to run correctly (deadlocking).
## Steps to reproduce the bug
```shell
pytest tests/test_arrow_dataset.py -k "test_filter_multiprocessing"
pytest tests/test_arrow_dataset.py -k "test_map_multiprocessing"
```
## Expected results
The functionality to work on all platforms.
## Actual results
Deadlock.
## Environment info
- `datasets` version: 1.14.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.2, also tested with 3.7.9
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3192/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3191 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3191/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3191/comments | https://api.github.com/repos/huggingface/datasets/issues/3191/events | https://github.com/huggingface/datasets/issues/3191 | 1,041,225,111 | I_kwDODunzps4-D9WX | 3,191 | Dataset viewer issue for '*compguesswhat*' | {
"login": "benotti",
"id": 2545336,
"node_id": "MDQ6VXNlcjI1NDUzMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2545336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/benotti",
"html_url": "https://github.com/benotti",
"followers_url": "https://api.github.com/users/benotti/followers",
"following_url": "https://api.github.com/users/benotti/following{/other_user}",
"gists_url": "https://api.github.com/users/benotti/gists{/gist_id}",
"starred_url": "https://api.github.com/users/benotti/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/benotti/subscriptions",
"organizations_url": "https://api.github.com/users/benotti/orgs",
"repos_url": "https://api.github.com/users/benotti/repos",
"events_url": "https://api.github.com/users/benotti/events{/privacy}",
"received_events_url": "https://api.github.com/users/benotti/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"```python\r\n>>> import datasets\r\n>>> dataset = datasets.load_dataset('compguesswhat', name='compguesswhat-original',split='train', streaming=True)\r\n>>> next(iter(dataset))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datasets-preview-backend/.ve... | 2021-11-01T14:16:49 | 2022-09-12T08:02:29 | 2022-09-12T08:02:29 | NONE | null | null | null | ## Dataset viewer issue for '*compguesswhat*'
**Link:** https://huggingface.co/datasets/compguesswhat
File not found
Am I the one who added this dataset ? No
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3191/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3190 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3190/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3190/comments | https://api.github.com/repos/huggingface/datasets/issues/3190/events | https://github.com/huggingface/datasets/issues/3190 | 1,041,153,631 | I_kwDODunzps4-Dr5f | 3,190 | combination of shuffle and filter results in a bug | {
"login": "rabeehk",
"id": 6278280,
"node_id": "MDQ6VXNlcjYyNzgyODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/6278280?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rabeehk",
"html_url": "https://github.com/rabeehk",
"followers_url": "https://api.github.com/users/rabeehk/followers",
"following_url": "https://api.github.com/users/rabeehk/following{/other_user}",
"gists_url": "https://api.github.com/users/rabeehk/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rabeehk/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rabeehk/subscriptions",
"organizations_url": "https://api.github.com/users/rabeehk/orgs",
"repos_url": "https://api.github.com/users/rabeehk/repos",
"events_url": "https://api.github.com/users/rabeehk/events{/privacy}",
"received_events_url": "https://api.github.com/users/rabeehk/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"I cannot reproduce this on master and pyarrow==4.0.1.\r\n",
"Hi ! There was a regression in `datasets` 1.12 that introduced this bug. It has been fixed in #3019 in 1.13\r\n\r\nCan you try to update `datasets` and try again ?",
"Thanks a lot, fixes with 1.13"
] | 2021-11-01T13:07:29 | 2021-11-02T10:50:49 | 2021-11-02T10:50:49 | CONTRIBUTOR | null | null | null | ## Describe the bug
Hi,
I would like to shuffle a dataset, then filter it based on each existing label. however, the combination of `filter`, `shuffle` seems to results in a bug. In the minimal example below, as you see in the filtered results, the filtered labels are not unique, meaning filter has not worked. Any suggestions as a temporary fix is appreciated @lhoestq.
Thanks.
Best regards
Rabeeh
## Steps to reproduce the bug
```python
import numpy as np
import datasets
datasets = datasets.load_dataset('super_glue', 'rte', script_version="master")
shuffled_data = datasets["train"].shuffle(seed=42)
for label in range(2):
print("label ", label)
data = shuffled_data.filter(lambda example: int(example['label']) == label)
print("length ", len(data), np.unique(data['label']))
```
## Expected results
Filtering per label, should only return the data with that specific label.
## Actual results
As you can see, filtered data per label, has still two labels of [0, 1]
```
label 0
length 1249 [0 1]
label 1
length 1241 [0 1]
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.12.1
- Platform: linux
- Python version: 3.7.11
- PyArrow version: 5.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3190/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3189/comments | https://api.github.com/repos/huggingface/datasets/issues/3189/events | https://github.com/huggingface/datasets/issues/3189 | 1,041,044,986 | I_kwDODunzps4-DRX6 | 3,189 | conll2003 incorrect label explanation | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @BramVanroy,\r\n\r\nsince these fields are of type `ClassLabel` (you can check this with `dset.features`), you can inspect the possible values with:\r\n```python\r\ndset.features[field_name].feature.names # .feature because it's a sequence of labels\r\n```\r\n\r\nand to find the mapping between names and integ... | 2021-11-01T11:03:30 | 2021-11-09T10:40:58 | 2021-11-09T10:40:58 | CONTRIBUTOR | null | null | null | In the [conll2003](https://huggingface.co/datasets/conll2003#data-fields) README, the labels are described as follows
> - `id`: a `string` feature.
> - `tokens`: a `list` of `string` features.
> - `pos_tags`: a `list` of classification labels, with possible values including `"` (0), `''` (1), `#` (2), `$` (3), `(` (4).
> - `chunk_tags`: a `list` of classification labels, with possible values including `O` (0), `B-ADJP` (1), `I-ADJP` (2), `B-ADVP` (3), `I-ADVP` (4).
> - `ner_tags`: a `list` of classification labels, with possible values including `O` (0), `B-PER` (1), `I-PER` (2), `B-ORG` (3), `I-ORG` (4) `B-LOC` (5), `I-LOC` (6) `B-MISC` (7), `I-MISC` (8).
First of all, it would be great if we can get a list of ALL possible pos_tags.
Second, the chunk tags labels cannot be correct. The description says the values go from 0 to 4 whereas the data shows values from at least 11 to 21 and 0.
EDIT: not really a bug, sorry for mistagging. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3189/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3188 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3188/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3188/comments | https://api.github.com/repos/huggingface/datasets/issues/3188/events | https://github.com/huggingface/datasets/issues/3188 | 1,040,980,712 | I_kwDODunzps4-DBro | 3,188 | conll2002 issues | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"Hi ! Thanks for reporting :)\r\n\r\nThis is related to https://github.com/huggingface/datasets/issues/2742, I'm working on it. It should fix the viewer for around 80 datasets.\r\n",
"Ah, hadn't seen that sorry.\r\n\r\nThe scrambled \"point of contact\" is a separate issue though, I think.",
"@lhoestq The \"poi... | 2021-11-01T09:49:24 | 2021-11-15T13:50:59 | 2021-11-12T17:18:11 | CONTRIBUTOR | null | null | null | **Link:** https://huggingface.co/datasets/conll2002
The dataset viewer throws a server error when trying to preview the dataset.
```
Message: Extraction protocol 'train' for file at 'https://raw.githubusercontent.com/teropa/nlp/master/resources/corpora/conll2002/esp.train' is not implemented yet
```
In addition, the "point of contact" has encoding issues and does not work when clicked.
Am I the one who added this dataset ? No, @lhoestq did | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3188/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3186 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3186/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3186/comments | https://api.github.com/repos/huggingface/datasets/issues/3186/events | https://github.com/huggingface/datasets/issues/3186 | 1,040,369,397 | I_kwDODunzps4-Asb1 | 3,186 | Dataset viewer for nli_tr | {
"login": "e-budur",
"id": 2246791,
"node_id": "MDQ6VXNlcjIyNDY3OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/2246791?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/e-budur",
"html_url": "https://github.com/e-budur",
"followers_url": "https://api.github.com/users/e-budur/followers",
"following_url": "https://api.github.com/users/e-budur/following{/other_user}",
"gists_url": "https://api.github.com/users/e-budur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/e-budur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/e-budur/subscriptions",
"organizations_url": "https://api.github.com/users/e-budur/orgs",
"repos_url": "https://api.github.com/users/e-budur/repos",
"events_url": "https://api.github.com/users/e-budur/events{/privacy}",
"received_events_url": "https://api.github.com/users/e-budur/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3287858981,
"node_id": "MDU6TGFiZWwzMjg3ODU4OTgx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/streaming",
"name": "streaming",
"color": "fef2c0",
"default": false,
"description": ""
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"It's an issue with the streaming mode:\r\n\r\n```python\r\n>>> import datasets\r\n>>> dataset = datasets.load_dataset('nli_tr', name='snli_tr',split='test', streaming=True)\r\n>>> next(iter(dataset))\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/slesage/hf/datas... | 2021-10-31T03:56:33 | 2022-09-12T09:15:34 | 2022-09-12T08:43:09 | CONTRIBUTOR | null | null | null | ## Dataset viewer issue for '*nli_tr*'
**Link:** https://huggingface.co/datasets/nli_tr
Hello,
Thank you for the new dataset preview feature that will help the users to view the datasets online.
We just noticed that the dataset viewer widget in the `nli_tr` dataset shows the error below. The error must be due to a temporary problem that may have blocked access to the dataset through the dataset viewer. But the dataset is currently accessible through the link in the error message. May we kindly ask if it would be possible to rerun the job so that it can access the dataset for the dataset viewer function?
Thank you.
Emrah
------------------------------------------
Server Error
Status code: 404
Exception: FileNotFoundError
Message: [Errno 2] No such file or directory: 'zip://snli_tr_1.0_train.jsonl::https://tabilab.cmpe.boun.edu.tr/datasets/nli_datasets/snli_tr_1.0.zip
------------------------------------------
Am I the one who added this dataset ? Yes
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3186/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3185/comments | https://api.github.com/repos/huggingface/datasets/issues/3185/events | https://github.com/huggingface/datasets/issues/3185 | 1,040,291,961 | I_kwDODunzps4-AZh5 | 3,185 | 7z dataset preview not implemented? | {
"login": "Kirili4ik",
"id": 30757466,
"node_id": "MDQ6VXNlcjMwNzU3NDY2",
"avatar_url": "https://avatars.githubusercontent.com/u/30757466?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Kirili4ik",
"html_url": "https://github.com/Kirili4ik",
"followers_url": "https://api.github.com/users/Kirili4ik/followers",
"following_url": "https://api.github.com/users/Kirili4ik/following{/other_user}",
"gists_url": "https://api.github.com/users/Kirili4ik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Kirili4ik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Kirili4ik/subscriptions",
"organizations_url": "https://api.github.com/users/Kirili4ik/orgs",
"repos_url": "https://api.github.com/users/Kirili4ik/repos",
"events_url": "https://api.github.com/users/Kirili4ik/events{/privacy}",
"received_events_url": "https://api.github.com/users/Kirili4ik/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer",
"name": "dataset-viewer",
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co"
}
] | closed | false | null | [] | null | [
"It's a bug in the dataset viewer: the dataset cannot be downloaded in streaming mode, but since the dataset is relatively small, the dataset viewer should have fallback to normal mode. Working on a fix.",
"Fixed. https://huggingface.co/datasets/samsum/viewer/samsum/train\r\n\r\n<img width=\"1563\" alt=\"Capture ... | 2021-10-30T20:18:27 | 2022-04-12T11:48:16 | 2022-04-12T11:48:07 | NONE | null | null | null | ## Dataset viewer issue for dataset 'samsum'
**Link:** https://huggingface.co/datasets/samsum
Server Error
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol '7z' for file at 'https://arxiv.org/src/1911.12237v2/anc/corpus.7z' is not implemented yet
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3185/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3185/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3181/comments | https://api.github.com/repos/huggingface/datasets/issues/3181/events | https://github.com/huggingface/datasets/issues/3181 | 1,039,682,097 | I_kwDODunzps49-Eox | 3,181 | `None` converted to `"None"` when loading a dataset | {
"login": "eladsegal",
"id": 13485709,
"node_id": "MDQ6VXNlcjEzNDg1NzA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13485709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eladsegal",
"html_url": "https://github.com/eladsegal",
"followers_url": "https://api.github.com/users/eladsegal/followers",
"following_url": "https://api.github.com/users/eladsegal/following{/other_user}",
"gists_url": "https://api.github.com/users/eladsegal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eladsegal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eladsegal/subscriptions",
"organizations_url": "https://api.github.com/users/eladsegal/orgs",
"repos_url": "https://api.github.com/users/eladsegal/repos",
"events_url": "https://api.github.com/users/eladsegal/events{/privacy}",
"received_events_url": "https://api.github.com/users/eladsegal/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https:... | null | [
"Hi @eladsegal, thanks for reporting.\r\n\r\n@mariosasko I saw you are already working on this, but maybe my comment will be useful to you.\r\n\r\nAll values are casted to their corresponding feature type (including `None` values). For example if the feature type is `Value(\"bool\")`, `None` is casted to `False`.\r... | 2021-10-29T15:23:53 | 2021-12-11T01:16:40 | 2021-12-09T14:26:57 | CONTRIBUTOR | null | null | null | ## Describe the bug
When loading a dataset `None` values of the type `NoneType` are converted to `'None'` of the type `str`.
## Steps to reproduce the bug
```python
from datasets import load_dataset
qasper = load_dataset("qasper", split="train", download_mode="reuse_cache_if_exists")
print(qasper[60]["full_text"]["section_name"])
```
When installing version 1.1.40, the output is
`[None, 'Introduction', 'Benchmark Datasets', ...]`
When installing from the master branch, the output is
`['None', 'Introduction', 'Benchmark Datasets', ...]`
Notice how the first element was changed from `NoneType` to `str`.
## Expected results
`None` should stay as is.
## Actual results
`None` is converted to a string.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: master
- Platform: Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3181/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3179/comments | https://api.github.com/repos/huggingface/datasets/issues/3179/events | https://github.com/huggingface/datasets/issues/3179 | 1,039,571,928 | I_kwDODunzps499pvY | 3,179 | Cannot load dataset when the config name is "special" | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
},
{
"id": 3470211881,
"node_id": "LA_kwDODunzps7O1zsp... | closed | false | null | [] | null | [
"The issue is that the datasets are malformed. Not a bug with the datasets library"
] | 2021-10-29T13:30:47 | 2021-10-29T13:35:21 | 2021-10-29T13:35:21 | CONTRIBUTOR | null | null | null | ## Describe the bug
After https://github.com/huggingface/datasets/pull/3159, we can get the config name of "Check/region_1", which is "Check___region_1".
But now we cannot load the dataset (not sure it's related to the above PR though). It's the case for all the similar datasets, listed in https://github.com/huggingface/datasets-preview-backend/issues/78
## Steps to reproduce the bug
```python
>>> from datasets import get_dataset_config_names
>>> get_dataset_config_names("Check/region_1")
['Check___region_1']
>>> load_dataset("Check/region_1")
Using custom data configuration Check___region_1-d2b3bc48f11c9be2
Downloading and preparing dataset json/Check___region_1 to /home/slesage/.cache/huggingface/datasets/json/Check___region_1-d2b3bc48f11c9be2/0.0.0/c2d554c3377ea79c7664b93dc65d0803b45e3279000f993c7bfd18937fd7f426...
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 4443.12it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1277.19it/s]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/load.py", line 1632, in load_dataset
builder_instance.download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 697, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1159, in _prepare_split
writer.write_table(table)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 442, in write_table
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "/home/slesage/hf/datasets-preview-backend/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 442, in <listcomp>
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1249, in pyarrow.lib.Table.__getitem__
File "pyarrow/table.pxi", line 1825, in pyarrow.lib.Table.column
File "pyarrow/table.pxi", line 1800, in pyarrow.lib.Table._ensure_integer_index
KeyError: 'Field "builder_name" does not exist in table schema'
```
Loading in streaming mode also returns something strange:
```python
>>> list(load_dataset("Check/region_1", streaming=True, split="train"))
Using custom data configuration Check___region_1-d2b3bc48f11c9be2
[{'builder_name': None, 'citation': '', 'config_name': None, 'dataset_size': None, 'description': '', 'download_checksums': None, 'download_size': None, 'features': {'speech': {'feature': {'dtype': 'float64', 'id': None, '_type': 'Value'}, 'length': -1, 'id': None, '_type': 'Sequence'}, 'sampling_rate': {'dtype': 'int64', 'id': None, '_type': 'Value'}, 'label': {'dtype': 'string', 'id': None, '_type': 'Value'}}, 'homepage': '', 'license': '', 'post_processed': None, 'post_processing_size': None, 'size_in_bytes': None, 'splits': None, 'supervised_keys': None, 'task_templates': None, 'version': None}, {'_data_files': [{'filename': 'dataset.arrow'}], '_fingerprint': 'f1702bb5533c549c', '_format_columns': ['speech', 'sampling_rate', 'label'], '_format_kwargs': {}, '_format_type': None, '_indexes': {}, '_indices_data_files': None, '_output_all_columns': False, '_split': None}]
```
## Expected results
The dataset should be loaded
## Actual results
An error occurs
## Environment info
- `datasets` version: 1.14.1.dev0
- Platform: Linux-5.11.0-1020-aws-x86_64-with-glibc2.31
- Python version: 3.9.6
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3179/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3178/comments | https://api.github.com/repos/huggingface/datasets/issues/3178/events | https://github.com/huggingface/datasets/issues/3178 | 1,039,539,076 | I_kwDODunzps499huE | 3,178 | "Property couldn't be hashed properly" even though fully picklable | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"After some digging, I found that this is caused by `dill` and using `recurse=True)` when trying to dump the object. The problem also occurs without multiprocessing. I can only find [the following information](https://dill.readthedocs.io/en/latest/dill.html#dill._dill.dumps) about this:\r\n\r\n> If recurse=True, th... | 2021-10-29T12:56:09 | 2023-01-04T15:33:16 | 2022-11-02T17:18:43 | CONTRIBUTOR | null | null | null | ## Describe the bug
I am trying to tokenize a dataset with spaCy. I found that no matter what I do, the spaCy language object (`nlp`) prevents `datasets` from pickling correctly - or so the warning says - even though manually pickling is no issue. It should not be an issue either, since spaCy objects are picklable.
## Steps to reproduce the bug
Here is a [colab](https://colab.research.google.com/drive/1gt75LCBIzsmBMvvipEOvWulvyZseBiA7?usp=sharing) but for some reason I cannot reproduce it there. That may have to do with logging/tqdm on Colab, or with running things in notebooks. I tried below code on Windows and Ubuntu as a Python script and getting the same issue (warning below).
```python
import pickle
from datasets import load_dataset
import spacy
class Processor:
def __init__(self):
self.nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser", "ner", "lemmatizer"])
@staticmethod
def collate(batch):
return [d["en"] for d in batch]
def parse(self, batch):
batch = batch["translation"]
return {"translation_tok": [{"en_tok": " ".join([t.text for t in doc])} for doc in self.nlp.pipe(self.collate(batch))]}
def process(self):
ds = load_dataset("wmt16", "de-en", split="train[:10%]")
ds = ds.map(self.parse, batched=True, num_proc=6)
if __name__ == '__main__':
pr = Processor()
# succeeds
with open("temp.pkl", "wb") as f:
pickle.dump(pr, f)
print("Successfully pickled!")
pr.process()
```
---
Here is a small change that includes `Hasher.hash` that shows that the hasher cannot seem to successfully pickle parts form the NLP object.
```python
from datasets.fingerprint import Hasher
import pickle
from datasets import load_dataset
import spacy
class Processor:
def __init__(self):
self.nlp = spacy.load("en_core_web_sm", disable=["tagger", "parser", "ner", "lemmatizer"])
@staticmethod
def collate(batch):
return [d["en"] for d in batch]
def parse(self, batch):
batch = batch["translation"]
return {"translation_tok": [{"en_tok": " ".join([t.text for t in doc])} for doc in self.nlp.pipe(self.collate(batch))]}
def process(self):
ds = load_dataset("wmt16", "de-en", split="train[:10]")
return ds.map(self.parse, batched=True)
if __name__ == '__main__':
pr = Processor()
# succeeds
with open("temp.pkl", "wb") as f:
pickle.dump(pr, f)
print("Successfully pickled class instance!")
# succeeds
with open("temp.pkl", "wb") as f:
pickle.dump(pr.nlp, f)
print("Successfully pickled nlp!")
# fails
print(Hasher.hash(pr.nlp))
pr.process()
```
## Expected results
This to be picklable, working (fingerprinted), and no warning.
## Actual results
In the first snippet, I get this warning
Parameter 'function'=<function Processor.parse at 0x7f44982247a0> of the transform datasets.arrow_dataset.Dataset._map_single couldn't be hashed properly, a random hash was used instead. Make sure your transforms and parameters are serializable with pickle or dill for the dataset fingerprinting and caching to work. If you reuse this transform, the caching mechanism will consider it to be different from the previous calls and recompute everything. This warning is only showed once. Subsequent hashing failures won't be showed.
In the second, I get this traceback which directs to the `Hasher.hash` line.
```
Traceback (most recent call last):
File " \Python\Python36\lib\pickle.py", line 918, in save_global
obj2, parent = _getattribute(module, name)
File " \Python\Python36\lib\pickle.py", line 266, in _getattribute
.format(name, obj))
AttributeError: Can't get local attribute 'add_codes.<locals>.ErrorsWithCodes' on <function add_codes at 0x00000296FF606EA0>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File " scratch_4.py", line 40, in <module>
print(Hasher.hash(pr.nlp))
File " \lib\site-packages\datasets\fingerprint.py", line 191, in hash
return cls.hash_default(value)
File " \lib\site-packages\datasets\fingerprint.py", line 184, in hash_default
return cls.hash_bytes(dumps(value))
File " \lib\site-packages\datasets\utils\py_utils.py", line 345, in dumps
dump(obj, file)
File " \lib\site-packages\datasets\utils\py_utils.py", line 320, in dump
Pickler(file, recurse=True).dump(obj)
File " \lib\site-packages\dill\_dill.py", line 498, in dump
StockPickler.dump(self, obj)
File " \Python\Python36\lib\pickle.py", line 409, in dump
self.save(obj)
File " \Python\Python36\lib\pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File " \Python\Python36\lib\pickle.py", line 634, in save_reduce
save(state)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\dill\_dill.py", line 990, in save_module_dict
StockPickler.save_dict(pickler, obj)
File " \Python\Python36\lib\pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File " \Python\Python36\lib\pickle.py", line 847, in _batch_setitems
save(v)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \Python\Python36\lib\pickle.py", line 781, in save_list
self._batch_appends(obj)
File " \Python\Python36\lib\pickle.py", line 805, in _batch_appends
save(x)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \Python\Python36\lib\pickle.py", line 736, in save_tuple
save(element)
File " \Python\Python36\lib\pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File " \Python\Python36\lib\pickle.py", line 634, in save_reduce
save(state)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \Python\Python36\lib\pickle.py", line 736, in save_tuple
save(element)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\dill\_dill.py", line 990, in save_module_dict
StockPickler.save_dict(pickler, obj)
File " \Python\Python36\lib\pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File " \Python\Python36\lib\pickle.py", line 847, in _batch_setitems
save(v)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\dill\_dill.py", line 1176, in save_instancemethod0
pickler.save_reduce(MethodType, (obj.__func__, obj.__self__), obj=obj)
File " \Python\Python36\lib\pickle.py", line 610, in save_reduce
save(args)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \Python\Python36\lib\pickle.py", line 736, in save_tuple
save(element)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\datasets\utils\py_utils.py", line 523, in save_function
obj=obj,
File " \Python\Python36\lib\pickle.py", line 610, in save_reduce
save(args)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \Python\Python36\lib\pickle.py", line 751, in save_tuple
save(element)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\dill\_dill.py", line 990, in save_module_dict
StockPickler.save_dict(pickler, obj)
File " \Python\Python36\lib\pickle.py", line 821, in save_dict
self._batch_setitems(obj.items())
File " \Python\Python36\lib\pickle.py", line 847, in _batch_setitems
save(v)
File " \Python\Python36\lib\pickle.py", line 521, in save
self.save_reduce(obj=obj, *rv)
File " \Python\Python36\lib\pickle.py", line 605, in save_reduce
save(cls)
File " \Python\Python36\lib\pickle.py", line 476, in save
f(self, obj) # Call unbound method with explicit self
File " \lib\site-packages\dill\_dill.py", line 1439, in save_type
StockPickler.save_global(pickler, obj, name=name)
File " \Python\Python36\lib\pickle.py", line 922, in save_global
(obj, module_name, name))
_pickle.PicklingError: Can't pickle <class 'spacy.errors.add_codes.<locals>.ErrorsWithCodes'>: it's not found as spacy.errors.add_codes.<locals>.ErrorsWithCodes
```
## Environment info
Tried on both Linux and Windows
- `datasets` version: 1.14.0
- Platform: Windows-10-10.0.19041-SP0 + Python 3.7.9; Linux-5.11.0-38-generic-x86_64-with-Ubuntu-20.04-focal + Python 3.7.12
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3178/reactions",
"total_count": 5,
"+1": 5,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3178/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3177 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3177/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3177/comments | https://api.github.com/repos/huggingface/datasets/issues/3177/events | https://github.com/huggingface/datasets/issues/3177 | 1,039,487,780 | I_kwDODunzps499VMk | 3,177 | More control over TQDM when using map/filter with multiple processes | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | closed | false | null | [] | null | [
"Hi,\r\n\r\nIt's hard to provide an API that would cover all use-cases with tqdm in this project.\r\n\r\nHowever, you can make it work by defining a custom decorator (a bit hacky tho) as follows:\r\n```python\r\nimport datasets\r\n\r\ndef progress_only_on_rank_0(func):\r\n def wrapper(*args, **kwargs):\r\n ... | 2021-10-29T11:56:16 | 2023-02-13T20:16:40 | 2023-02-13T20:16:40 | CONTRIBUTOR | null | null | null | It would help with the clutter in my terminal if tqdm is only shown for rank 0 when using `num_proces>0` in the map and filter methods of datasets.
```python
dataset.map(lambda examples: tokenize(examples["text"]), batched=True, num_proc=6)
```
The above snippet leads to a lot of TQDM bars and depending on your terminal, these will not overwrite but keep pushing each other down.
```
#0: 0%| | 0/13 [00:00<?, ?ba/s]
#1: 0%| | 0/13 [00:00<?, ?ba/s]
#2: 0%| | 0/13 [00:00<?, ?ba/s]
#3: 0%| | 0/13 [00:00<?, ?ba/s]
#4: 0%| | 0/13 [00:00<?, ?ba/s]
#5: 0%| | 0/13 [00:00<?, ?ba/s]
#0: 8%| | 1/13 [00:00<?, ?ba/s]
#1: 8%| | 1/13 [00:00<?, ?ba/s]
...
```
Instead, it would be welcome if we had the option to only show the progress of rank 0. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3177/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3172 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3172/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3172/comments | https://api.github.com/repos/huggingface/datasets/issues/3172/events | https://github.com/huggingface/datasets/issues/3172 | 1,038,351,587 | I_kwDODunzps494_zj | 3,172 | `SystemError 15` thrown in `Dataset.__del__` when using `Dataset.map()` with `num_proc>1` | {
"login": "vlievin",
"id": 9859840,
"node_id": "MDQ6VXNlcjk4NTk4NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/9859840?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vlievin",
"html_url": "https://github.com/vlievin",
"followers_url": "https://api.github.com/users/vlievin/followers",
"following_url": "https://api.github.com/users/vlievin/following{/other_user}",
"gists_url": "https://api.github.com/users/vlievin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vlievin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vlievin/subscriptions",
"organizations_url": "https://api.github.com/users/vlievin/orgs",
"repos_url": "https://api.github.com/users/vlievin/repos",
"events_url": "https://api.github.com/users/vlievin/events{/privacy}",
"received_events_url": "https://api.github.com/users/vlievin/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"NB: even if the error is raised, the dataset is successfully cached. So restarting the script after every `map()` allows to ultimately run the whole preprocessing. But this prevents to realistically run the code over multiple nodes.",
"Hi,\r\n\r\nIt's not easy to debug the problem without the script. I may be wr... | 2021-10-28T10:29:00 | 2023-09-04T14:20:49 | 2021-11-03T11:26:10 | NONE | null | null | null | ## Describe the bug
I use `datasets.map` to preprocess some data in my application. The error `SystemError 15` is thrown at the end of the execution of `Dataset.map()` (only with `num_proc>1`. Traceback included bellow.
The exception is raised only when the code runs within a specific context. Despite ~10h spent investigating this issue, I have failed to isolate the bug, so let me describe my setup.
In my project, `Dataset` is wrapped into a `LightningDataModule` and the data is preprocessed when calling `LightningDataModule.setup()`. Calling `.setup()` in an isolated script works fine (even when wrapped with `hydra.main()`). However, when calling `.setup()` within the experiment script (depends on `pytorch_lightning`), the script crashes and `SystemError 15`.
I could avoid throwing this error by modifying ` Dataset.__del__()` (see bellow), but I believe this only moves the problem somewhere else. I am completely stuck with this issue, any hint would be welcome.
```python
class Dataset()
...
def __del__(self):
if hasattr(self, "_data"):
_ = self._data # <- ugly trick that allows avoiding the issue.
del self._data
if hasattr(self, "_indices"):
del self._indices
```
## Steps to reproduce the bug
```python
# Unfortunately I couldn't isolate the bug.
```
## Expected results
Calling `Dataset.map()` without throwing an exception. Or at least raising a more detailed exception/traceback.
## Actual results
```
Exception ignored in: <function Dataset.__del__ at 0x7f7cec179160>███████████████████████████████████████████████████| 5/5 [00:05<00:00, 1.17ba/s]
Traceback (most recent call last):
File ".../python3.8/site-packages/datasets/arrow_dataset.py", line 906, in __del__
del self._data
File ".../python3.8/site-packages/ray/worker.py", line 1033, in sigterm_handler
sys.exit(signum)
SystemExit: 15
```
## Environment info
Tested on 2 environments:
**Environment 1.**
- `datasets` version: 1.14.0
- Platform: macOS-10.16-x86_64-i386-64bit
- Python version: 3.8.8
- PyArrow version: 6.0.0
**Environment 2.**
- `datasets` version: 1.14.0
- Platform: Linux-4.18.0-305.19.1.el8_4.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.7
- PyArrow version: 6.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3172/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3172/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3171 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3171/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3171/comments | https://api.github.com/repos/huggingface/datasets/issues/3171/events | https://github.com/huggingface/datasets/issues/3171 | 1,037,728,059 | I_kwDODunzps492nk7 | 3,171 | Raise exceptions instead of using assertions for control flow | {
"login": "mariosasko",
"id": 47462742,
"node_id": "MDQ6VXNlcjQ3NDYyNzQy",
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mariosasko",
"html_url": "https://github.com/mariosasko",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url": "https://api.github.com/users/mariosasko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mariosasko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariosasko/subscriptions",
"organizations_url": "https://api.github.com/users/mariosasko/orgs",
"repos_url": "https://api.github.com/users/mariosasko/repos",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"received_events_url": "https://api.github.com/users/mariosasko/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892877,
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue",
"name": "good first issue",
"color": "7057ff",
"default": true,
"description": "Good for newcomers"
}
] | closed | false | null | [] | null | [
"Adding the remaining tasks for this issue to help new code contributors. \r\n$ cd src/datasets && ack assert -lc \r\n- [x] commands/convert.py:1\r\n- [x] arrow_reader.py:3\r\n- [x] load.py:7\r\n- [x] utils/py_utils.py:2\r\n- [x] features/features.py:9\r\n- [x] arrow_writer.py:7\r\n- [x] search.py:6\r\n- [x] table... | 2021-10-27T18:26:52 | 2021-12-23T16:40:37 | 2021-12-23T16:40:37 | CONTRIBUTOR | null | null | null | Motivated by https://github.com/huggingface/transformers/issues/12789 in Transformers, one welcoming change would be replacing assertions with proper exceptions. The only type of assertions we should keep are those used as sanity checks.
Currently, there is a total of 87 files with the `assert` statements (located under `datasets` and `src/datasets`), so when working on this, to manage the PR size, only modify 4-5 files at most before submitting a PR. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3171/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3168 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3168/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3168/comments | https://api.github.com/repos/huggingface/datasets/issues/3168/events | https://github.com/huggingface/datasets/issues/3168 | 1,036,673,263 | I_kwDODunzps49ymDv | 3,168 | OpenSLR/83 is empty | {
"login": "tyrius02",
"id": 4561309,
"node_id": "MDQ6VXNlcjQ1NjEzMDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4561309?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tyrius02",
"html_url": "https://github.com/tyrius02",
"followers_url": "https://api.github.com/users/tyrius02/followers",
"following_url": "https://api.github.com/users/tyrius02/following{/other_user}",
"gists_url": "https://api.github.com/users/tyrius02/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tyrius02/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tyrius02/subscriptions",
"organizations_url": "https://api.github.com/users/tyrius02/orgs",
"repos_url": "https://api.github.com/users/tyrius02/repos",
"events_url": "https://api.github.com/users/tyrius02/events{/privacy}",
"received_events_url": "https://api.github.com/users/tyrius02/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "tyrius02",
"id": 4561309,
"node_id": "MDQ6VXNlcjQ1NjEzMDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4561309?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tyrius02",
"html_url": "https://github.com/tyrius02",
"followers_url": "https://api.github.com/users/tyrius02/followers",
"following_url": "https://api.github.com/users/tyrius02/following{/other_user}",
"gists_url": "https://api.github.com/users/tyrius02/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tyrius02/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tyrius02/subscriptions",
"organizations_url": "https://api.github.com/users/tyrius02/orgs",
"repos_url": "https://api.github.com/users/tyrius02/repos",
"events_url": "https://api.github.com/users/tyrius02/events{/privacy}",
"received_events_url": "https://api.github.com/users/tyrius02/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "tyrius02",
"id": 4561309,
"node_id": "MDQ6VXNlcjQ1NjEzMDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4561309?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tyrius02",
"html_url": "https://github.com/tyrius02",
"followers_url": "https://api.gi... | null | [
"Hi @tyrius02, thanks for reporting. I see you self-assigned this issue: are you working on this?",
"@albertvillanova Yes. Figured I introduced the broken config, I should fix it too.\r\n\r\nI've got it working, but I'm struggling with one of the tests. I've started a PR so I/we can work through it.",
"Looks li... | 2021-10-26T19:42:21 | 2021-10-29T10:04:09 | 2021-10-29T10:04:09 | CONTRIBUTOR | null | null | null | ## Describe the bug
As the summary says, openslr / SLR83 / train is empty.
The dataset returned after loading indicates there are **zero** rows. The correct number should be **17877**.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('openslr', 'SLR83')
```
## Expected results
```
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'sentence'],
num_rows: 17877
})
})
```
## Actual results
```
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'sentence'],
num_rows: 0
})
})
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.1.dev0 (master HEAD)
- Platform: Ubuntu 20.04
- Python version: 3.7.10
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3168/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3168/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3167 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3167/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3167/comments | https://api.github.com/repos/huggingface/datasets/issues/3167/events | https://github.com/huggingface/datasets/issues/3167 | 1,036,488,992 | I_kwDODunzps49x5Eg | 3,167 | bookcorpusopen no longer works | {
"login": "lucadiliello",
"id": 23355969,
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucadiliello",
"html_url": "https://github.com/lucadiliello",
"followers_url": "https://api.github.com/users/lucadiliello/followers",
"following_url": "https://api.github.com/users/lucadiliello/following{/other_user}",
"gists_url": "https://api.github.com/users/lucadiliello/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucadiliello/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucadiliello/subscriptions",
"organizations_url": "https://api.github.com/users/lucadiliello/orgs",
"repos_url": "https://api.github.com/users/lucadiliello/repos",
"events_url": "https://api.github.com/users/lucadiliello/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucadiliello/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "lhoestq",
"id": 42851186,
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lhoestq",
"html_url": "https://github.com/lhoestq",
"followers_url": "https://api.git... | null | [
"Hi ! Thanks for reporting :) I think #3280 should fix this",
"I tried with the latest changes from #3280 on google colab and it worked fine :)\r\nWe'll do a new release soon, in the meantime you can use the updated version with:\r\n```python\r\nload_dataset(\"bookcorpusopen\", revision=\"master\")\r\n```",
"Fi... | 2021-10-26T16:06:15 | 2021-11-17T15:53:46 | 2021-11-17T15:53:46 | CONTRIBUTOR | null | null | null | ## Describe the bug
When using the latest version of datasets (1.14.0), I cannot use the `bookcorpusopen` dataset. The process blocks always around `9924 examples [00:06, 1439.61 examples/s]` when preparing the dataset. I also noticed that after half an hour the process is automatically killed because of the RAM usage (the machine has 1TB of RAM...).
This did not happen with 1.4.1.
I tried also `rm -rf ~/.cache/huggingface` but did not help.
Changing python version between 3.7, 3.8 and 3.9 did not help too.
## Steps to reproduce the bug
```python
import datasets
d = datasets.load_dataset('bookcorpusopen')
```
## Expected results
A clear and concise description of the expected results.
## Actual results
Specify the actual results or traceback.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.14.0
- Platform: Linux-5.4.0-1054-aws-x86_64-with-glibc2.27
- Python version: 3.9.7
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3167/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3165 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3165/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3165/comments | https://api.github.com/repos/huggingface/datasets/issues/3165/events | https://github.com/huggingface/datasets/issues/3165 | 1,036,448,998 | I_kwDODunzps49xvTm | 3,165 | Deprecate prepare_module | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-10-26T15:27:15 | 2021-11-05T09:27:36 | 2021-11-05T09:27:36 | MEMBER | null | null | null | In version 1.13, `prepare_module` was deprecated.
Add deprecation warning and remove its usage from all the library. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3165/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3165/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3164 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3164/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3164/comments | https://api.github.com/repos/huggingface/datasets/issues/3164/events | https://github.com/huggingface/datasets/issues/3164 | 1,035,662,830 | I_kwDODunzps49uvXu | 3,164 | Add raw data files to the Hub with GitHub LFS for canonical dataset | {
"login": "zlucia",
"id": 40370937,
"node_id": "MDQ6VXNlcjQwMzcwOTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/40370937?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zlucia",
"html_url": "https://github.com/zlucia",
"followers_url": "https://api.github.com/users/zlucia/followers",
"following_url": "https://api.github.com/users/zlucia/following{/other_user}",
"gists_url": "https://api.github.com/users/zlucia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zlucia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zlucia/subscriptions",
"organizations_url": "https://api.github.com/users/zlucia/orgs",
"repos_url": "https://api.github.com/users/zlucia/repos",
"events_url": "https://api.github.com/users/zlucia/events{/privacy}",
"received_events_url": "https://api.github.com/users/zlucia/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [
"Hi @zlucia, I would actually suggest hosting the dataset as a huggingface.co-hosted dataset.\r\n\r\nThe only difference with a \"canonical\"/legacy dataset is that it's nested under an organization (here `stanford` or `stanfordnlp` for instance – completely up to you) but then you can upload your data using git-lf... | 2021-10-25T23:28:21 | 2021-10-30T19:54:51 | 2021-10-30T19:54:51 | NONE | null | null | null | I'm interested in sharing the CaseHOLD dataset (https://arxiv.org/abs/2104.08671) as a canonical dataset on the HuggingFace Hub and would like to add the raw data files to the Hub with GitHub LFS, since it seems like a more sustainable long term storage solution, compared to other storage solutions available to my team. From what I can tell, this option is not immediately supported if one follows the sharing steps detailed here: [https://huggingface.co/docs/datasets/share_dataset.html#sharing-a-canonical-dataset](https://huggingface.co/docs/datasets/share_dataset.html#sharing-a-canonical-dataset), since GitHub LFS is not supported for public forks. Is there a way to request this? Thanks! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3164/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3162 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3162/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3162/comments | https://api.github.com/repos/huggingface/datasets/issues/3162/events | https://github.com/huggingface/datasets/issues/3162 | 1,035,462,136 | I_kwDODunzps49t-X4 | 3,162 | `datasets-cli test` should work with datasets without scripts | {
"login": "sashavor",
"id": 14205986,
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashavor",
"html_url": "https://github.com/sashavor",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"repos_url": "https://api.github.com/users/sashavor/repos",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
}
] | open | false | null | [] | null | [
"> It would be really useful to be able to run `datasets-cli test`for datasets that don't have scripts attached to them (whether the datasets are private or not).\r\n> \r\n> I wasn't able to run the script for a private test dataset that I had created on the hub (https://huggingface.co/datasets/huggingface/DataMeas... | 2021-10-25T18:52:30 | 2021-11-25T16:04:29 | null | NONE | null | null | null | It would be really useful to be able to run `datasets-cli test`for datasets that don't have scripts attached to them (whether the datasets are private or not).
I wasn't able to run the script for a private test dataset that I had created on the hub (https://huggingface.co/datasets/huggingface/DataMeasurementsTest/tree/main) -- although @lhoestq came to save the day!
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3162/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3162/timeline | null | null |
https://api.github.com/repos/huggingface/datasets/issues/3155 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3155/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3155/comments | https://api.github.com/repos/huggingface/datasets/issues/3155/events | https://github.com/huggingface/datasets/issues/3155 | 1,034,468,757 | I_kwDODunzps49qL2V | 3,155 | Illegal instruction (core dumped) at datasets import | {
"login": "hacobe",
"id": 91226467,
"node_id": "MDQ6VXNlcjkxMjI2NDY3",
"avatar_url": "https://avatars.githubusercontent.com/u/91226467?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hacobe",
"html_url": "https://github.com/hacobe",
"followers_url": "https://api.github.com/users/hacobe/followers",
"following_url": "https://api.github.com/users/hacobe/following{/other_user}",
"gists_url": "https://api.github.com/users/hacobe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hacobe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hacobe/subscriptions",
"organizations_url": "https://api.github.com/users/hacobe/orgs",
"repos_url": "https://api.github.com/users/hacobe/repos",
"events_url": "https://api.github.com/users/hacobe/events{/privacy}",
"received_events_url": "https://api.github.com/users/hacobe/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"It seems to be an issue with how conda-forge is building the binaries. It works on some machines, but not a machine with AMD Opteron 8384 processors."
] | 2021-10-24T17:21:36 | 2021-11-18T19:07:04 | 2021-11-18T19:07:03 | CONTRIBUTOR | null | null | null | ## Describe the bug
I install datasets using conda and when I import datasets I get: "Illegal instruction (core dumped)"
## Steps to reproduce the bug
```
conda create --prefix path/to/env
conda activate path/to/env
conda install -c huggingface -c conda-forge datasets
# exits with output "Illegal instruction (core dumped)"
python -m datasets
```
## Environment info
When I run "datasets-cli env", I also get "Illegal instruction (core dumped)"
If I run the following commands:
```
conda create --prefix path/to/another/new/env
conda activate path/to/another/new/env
conda install -c huggingface transformers
transformers-cli env
```
Then I get:
- `transformers` version: 4.11.3
- Platform: Linux-5.4.0-67-generic-x86_64-with-glibc2.17
- Python version: 3.8.12
- PyTorch version (GPU?): not installed (NA)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
Let me know what additional information you need in order to debug this issue. Thanks in advance! | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3155/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3155/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3154 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3154/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3154/comments | https://api.github.com/repos/huggingface/datasets/issues/3154/events | https://github.com/huggingface/datasets/issues/3154 | 1,034,361,806 | I_kwDODunzps49pxvO | 3,154 | Sacrebleu unexpected behaviour/requirement for data format | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"Hi @BramVanroy!\r\n\r\nGood question. This project relies on PyArrow (tables) to store data too big to fit in RAM. In the case of metrics, this means that the number of predictions and references has to match to form a table.\r\n\r\nThat's why your example throws an error even though it matches the schema:\r\n```p... | 2021-10-24T08:55:33 | 2021-10-31T09:08:32 | 2021-10-31T09:08:31 | CONTRIBUTOR | null | null | null | ## Describe the bug
When comparing with the original `sacrebleu` implementation, the `datasets` implementation does some strange things that I do not quite understand. This issue was triggered when I was trying to implement TER and found the datasets implementation of BLEU [here](https://github.com/huggingface/datasets/pull/3153).
In the below snippet, the original sacrebleu snippet works just fine whereas the datasets implementation throws an error.
## Steps to reproduce the bug
```python
import sacrebleu
import datasets
refs = [
['The dog bit the man.', 'It was not unexpected.', 'The man bit him first.'],
['The dog had bit the man.', 'No one was surprised.', 'The man had bitten the dog.'],
]
hyps = ['The dog bit the man.', "It wasn't surprising.", 'The man had just bitten him.']
expected_bleu = 48.530827
ds_bleu = datasets.load_metric("sacrebleu")
bleu_score_sb = sacrebleu.corpus_bleu(hyps, refs).score
print(bleu_score_sb, expected_bleu)
# works: 48.5308...
bleu_score_ds = ds_bleu.compute(predictions=hyps, references=refs)["score"]
print(bleu_score_ds, expected_bleu)
# ValueError: Predictions and/or references don't match the expected format.
```
This seems to be related to how datasets forces the features format here:
https://github.com/huggingface/datasets/blob/87c71b9c29a40958973004910f97e4892559dfed/metrics/sacrebleu/sacrebleu.py#L94-L99
and then manipulates the references during the compute stage here
https://github.com/huggingface/datasets/blob/87c71b9c29a40958973004910f97e4892559dfed/metrics/sacrebleu/sacrebleu.py#L119-L122
I do not quite understand why that is required since sacrebleu handles argument parsing quite well [by itself](https://github.com/mjpost/sacrebleu/blob/2787185dd0f8d224c72ee5a831d163c2ac711a47/sacrebleu/metrics/base.py#L229).
## Actual results
Traceback (most recent call last):
File "C:\Users\bramv\AppData\Roaming\JetBrains\PyCharm2020.3\scratches\scratch_23.py", line 23, in <module>
bleu_score_ds = ds_bleu.compute(predictions=hyps, references=refs)["score"]
File "C:\dev\python\datasets\src\datasets\metric.py", line 392, in compute
self.add_batch(predictions=predictions, references=references)
File "C:\dev\python\datasets\src\datasets\metric.py", line 439, in add_batch
raise ValueError(
ValueError: Predictions and/or references don't match the expected format.
Expected format: {'predictions': Value(dtype='string', id='sequence'), 'references': Sequence(feature=Value(dtype='string', id='sequence'), length=-1, id='references')},
Input predictions: ['The dog bit the man.', "It wasn't surprising.", 'The man had just bitten him.'],
Input references: [['The dog bit the man.', 'It was not unexpected.', 'The man bit him first.'], ['The dog had bit the man.', 'No one was surprised.', 'The man had bitten the dog.']]
## Environment info
- `datasets` version: 1.14.1.dev0
- Platform: Windows-10-10.0.19041-SP0
- Python version: 3.9.2
- PyArrow version: 4.0.1
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3154/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3150 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3150/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3150/comments | https://api.github.com/repos/huggingface/datasets/issues/3150/events | https://github.com/huggingface/datasets/issues/3150 | 1,033,831,530 | I_kwDODunzps49nwRq | 3,150 | Faiss _is_ available on Windows | {
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | [
"Sure, feel free to open a PR."
] | 2021-10-22T18:07:16 | 2021-11-02T10:06:03 | 2021-11-02T10:06:03 | CONTRIBUTOR | null | null | null | In the setup file, I find the following:
https://github.com/huggingface/datasets/blob/87c71b9c29a40958973004910f97e4892559dfed/setup.py#L171
However, FAISS does install perfectly fine on Windows on my system. You can also confirm this on the [PyPi page](https://pypi.org/project/faiss-cpu/#files), where Windows wheels are available. Maybe this was true for older versions? For current versions, this can be removed I think.
(This isn't really a bug but didn't know how else to tag.)
If you agree I can do a quick PR and remove that line. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3150/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3150/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3148 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3148/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3148/comments | https://api.github.com/repos/huggingface/datasets/issues/3148/events | https://github.com/huggingface/datasets/issues/3148 | 1,033,685,208 | I_kwDODunzps49nMjY | 3,148 | Streaming with num_workers != 0 | {
"login": "justheuristic",
"id": 3491902,
"node_id": "MDQ6VXNlcjM0OTE5MDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/3491902?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/justheuristic",
"html_url": "https://github.com/justheuristic",
"followers_url": "https://api.github.com/users/justheuristic/followers",
"following_url": "https://api.github.com/users/justheuristic/following{/other_user}",
"gists_url": "https://api.github.com/users/justheuristic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/justheuristic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/justheuristic/subscriptions",
"organizations_url": "https://api.github.com/users/justheuristic/orgs",
"repos_url": "https://api.github.com/users/justheuristic/repos",
"events_url": "https://api.github.com/users/justheuristic/events{/privacy}",
"received_events_url": "https://api.github.com/users/justheuristic/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | null | [] | null | [
"I can confirm that I was able to reproduce the bug. This seems odd given that #3423 reports duplicate data retrieval when `num_workers` and `streaming` are used together, which is obviously different from what is reported here. ",
"Any update? A possible solution is to have multiple arrow files as shards, and ha... | 2021-10-22T15:07:17 | 2022-07-04T12:14:58 | 2022-07-04T12:14:58 | NONE | null | null | null | ## Describe the bug
When using dataset streaming with pytorch DataLoader, the setting num_workers to anything other than 0 causes the code to freeze forever before yielding the first batch.
The code owner is likely @lhoestq
## Steps to reproduce the bug
For your convenience, we've prepped a colab notebook that reproduces the bug
https://colab.research.google.com/drive/1Mgl0oTZSNIE3UeGl_oX9wPCOIxRg19h1?usp=sharing
```python
!pip install datasets==1.14.0
should_freeze_forever = True
# ^-- set this to True in order to freeze forever, set to False in order to work normally
import torch
from datasets import load_dataset
data = load_dataset("oscar", "unshuffled_deduplicated_bn", split="train", streaming=True)
data = data.map(lambda x: {"text": x["text"], "orig": f"oscar[{x['id']}]"}, batched=True)
data = data.shuffle(100, seed=1337)
data = data.with_format("torch")
loader = torch.utils.data.DataLoader(data, batch_size=2, num_workers=2 if should_freeze_forever else 0)
# v-- the code should freeze forever at this line
for i, row in enumerate(loader):
print(row)
if i > 10: break
print("DONE!")
```
## Expected results
The code should not freeze forever with num_workers=2
## Actual results
The code freezes forever with num_workers=2
## Environment info
- `datasets` version: 1.14.0 (also found in previous versions)
- Platform: google colab (also locally)
- Python version: 3.7, (also 3.8)
- PyArrow version: 3.0.0
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3148/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3148/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3146 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3146/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3146/comments | https://api.github.com/repos/huggingface/datasets/issues/3146/events | https://github.com/huggingface/datasets/issues/3146 | 1,033,605,947 | I_kwDODunzps49m5M7 | 3,146 | CLI test command throws NonMatchingSplitsSizesError when saving infos | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892857,
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug",
"name": "bug",
"color": "d73a4a",
"default": true,
"description": "Something isn't working"
}
] | closed | false | {
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "albertvillanova",
"id": 8515462,
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/albertvillanova",
"html_url": "https://github.com/albertvillanova",
"followers_... | null | [] | 2021-10-22T13:50:53 | 2021-10-27T08:01:49 | 2021-10-27T08:01:49 | MEMBER | null | null | null | When trying to generate a datset JSON metadata, a `NonMatchingSplitsSizesError` is thrown:
```
$ datasets-cli test datasets/arabic_billion_words --save_infos --all_configs
Testing builder 'Alittihad' (1/10)
Downloading and preparing dataset arabic_billion_words/Alittihad (download: 332.13 MiB, generated: Unknown size, post-processed: Unknown size, total: 332.13 MiB) to .cache\arabic_billion_words\Alittihad\1.1.0\8175ff1c9714c6d5d15b1141b6042e5edf048276bb81a9c14e35e149a7a62ae4...
Traceback (most recent call last):
File "path\huggingface\datasets\.venv\Scripts\datasets-cli-script.py", line 33, in <module>
sys.exit(load_entry_point('datasets', 'console_scripts', 'datasets-cli')())
File "path\huggingface\datasets\src\datasets\commands\datasets_cli.py", line 33, in main
service.run()
File "path\huggingface\datasets\src\datasets\commands\test.py", line 144, in run
builder.download_and_prepare(
File "path\huggingface\datasets\src\datasets\builder.py", line 607, in download_and_prepare
self._download_and_prepare(
File "path\huggingface\datasets\src\datasets\builder.py", line 709, in _download_and_prepare
verify_splits(self.info.splits, split_dict)
File "path\huggingface\datasets\src\datasets\utils\info_utils.py", line 74, in verify_splits
raise NonMatchingSplitsSizesError(str(bad_splits))
datasets.utils.info_utils.NonMatchingSplitsSizesError: [{'expected': SplitInfo(name='train', num_bytes=0, num_examples=0, dataset_name='arabic_billion_words'), 'recorded': SplitInfo(name='train', num_bytes=1601790302, num_examples=349342, dataset_name='arabic_billion_words')}]
```
This is due because a previous run generated a wrong `dataset_info.json`.
This error can be avoided by passing `--ignore_verifications`, but I think this should be assumed when passing `--save_infos`. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3146/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3145 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3145/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3145/comments | https://api.github.com/repos/huggingface/datasets/issues/3145/events | https://github.com/huggingface/datasets/issues/3145 | 1,033,580,009 | I_kwDODunzps49my3p | 3,145 | [when Image type will exist] provide a way to get the data as binary + filename | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_k... | closed | false | null | [] | null | [
"@severo, maybe somehow related to this PR ?\r\n- #3129",
"@severo I'll keep that in mind.\r\n\r\nYou can track progress on the Image feature in #3163 (still in the early stage). ",
"Hi ! As discussed with @severo offline it looks like the dataset viewer already supports reading PIL images, so maybe the datase... | 2021-10-22T13:23:49 | 2021-12-22T11:05:37 | 2021-12-22T11:05:36 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
When a dataset cell contains a value of type Image (be it from a remote URL, an Array2D/3D, or any other way to represent images), I want to be able to write the image to the disk, with the correct filename, and optionally to know its mimetype, in order to serve it on the web.
Note: this issue would apply exactly the same for the `Audio` type.
**Describe the solution you'd like**
If a "cell" has the type `Image`, provide a way to get the binary content of the file, and the filename, eg as:
```python
filename: str
data: bytes
```
**Describe alternatives you've considered**
A way to write the cell to the disk (passing a local directory), and then return the pathname, filename, and mimetype.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3145/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3144 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3144/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3144/comments | https://api.github.com/repos/huggingface/datasets/issues/3144/events | https://github.com/huggingface/datasets/issues/3144 | 1,033,573,760 | I_kwDODunzps49mxWA | 3,144 | Infer the features if missing | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_k... | closed | false | null | [] | null | [
"Done by @lhoestq here: https://github.com/huggingface/datasets/pull/4500 (https://github.com/huggingface/datasets/pull/4500/files#diff-02930e1d966f4b41f9ddf15d961f16f5466d9bee583138657018c7329f71aa43R1255 in particular)\r\n"
] | 2021-10-22T13:17:33 | 2022-09-08T08:23:10 | 2022-09-08T08:23:10 | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
Some datasets, in particular community datasets, have no info file, thus no features.
**Describe the solution you'd like**
If a dataset has no features, the first loaded data (5-10 rows) could be used to infer the type.
Related: `datasets` would provide a way to load the data, and get the rows AND the features as the result.
**Describe alternatives you've considered**
The HF hub could also provide some UI to help the dataset maintainers to explicit the types of their rows, or automatically infer them as an initial proposal. | {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3144/timeline | null | completed |
https://api.github.com/repos/huggingface/datasets/issues/3143 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3143/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3143/comments | https://api.github.com/repos/huggingface/datasets/issues/3143/events | https://github.com/huggingface/datasets/issues/3143 | 1,033,569,655 | I_kwDODunzps49mwV3 | 3,143 | Provide a way to check if the features (in info) match with the data of a split | {
"login": "severo",
"id": 1676121,
"node_id": "MDQ6VXNlcjE2NzYxMjE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1676121?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/severo",
"html_url": "https://github.com/severo",
"followers_url": "https://api.github.com/users/severo/followers",
"following_url": "https://api.github.com/users/severo/following{/other_user}",
"gists_url": "https://api.github.com/users/severo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/severo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/severo/subscriptions",
"organizations_url": "https://api.github.com/users/severo/orgs",
"repos_url": "https://api.github.com/users/severo/repos",
"events_url": "https://api.github.com/users/severo/events{/privacy}",
"received_events_url": "https://api.github.com/users/severo/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1935892871,
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement",
"name": "enhancement",
"color": "a2eeef",
"default": true,
"description": "New feature or request"
},
{
"id": 3470211881,
"node_id": "LA_k... | open | false | null | [] | null | [
"Related: #3144 "
] | 2021-10-22T13:13:36 | 2021-10-22T13:17:56 | null | CONTRIBUTOR | null | null | null | **Is your feature request related to a problem? Please describe.**
I understand that currently the data loaded has not always the type described in the info features
**Describe the solution you'd like**
Provide a way to check if the rows have the type described by info features
**Describe alternatives you've considered**
Always check it, and raise an error when loading the data if their type doesn't match the features.
| {
"url": "https://api.github.com/repos/huggingface/datasets/issues/3143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/datasets/issues/3143/timeline | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.